SwinNet: Swin Transformer drives edge-aware RGB-D and RGB-T salient object detection
SwinNet:Swin Transformer 驱动边缘感知 RGB-D 和 RGB-T 显着目标检测
IEEE Transactions on Circuits and Systems for Video Technology2021
一 动机
卷积神经网络 (CNN) 擅长在某些感受野内提取上下文特征,而Transformer可以对全局远程依赖特征进行建模。Swin Transformer ,吸收了 CNN 的局部优势和 Transformer 的远程依赖优点
二 方法
在以上基础上,作者提出了一种用于 RGB-D 和 RGB-T 显著目标检测的跨模态融合模型 SwinNet。
它是由Swin Transformer提取分层特性,使用通道注意力和空间注意力推动以弥合两种模态之间的差距,并由边缘信息引导以锐化显着对象的轮廓。
具体而言,双流Swin Transformer编码器首先提取多模态特征,然后提出空间对齐和通道重新校准模块以优化层内跨模态特征。 为了明确模糊边界,边缘引导解码器在边缘特征的引导下实现了层间跨模态融合。
三 网络框架
总体框架一个有4个模块:(1)双流主干;(2)通道对齐和空间校准模块;(3)边缘感知模块;(4)边缘引导解码器

3.1两流 Swin Transformer 主干
3.2空间对齐和通道重新校准模块


一方面,由于多模态图像对中显着对象的位置应该相同,因此需要首先对齐来自不同模态的特征以显示共同的显着位置。 另一方面,由于 RGB 图像表现出更多的外观和纹理信息,而深度图像表现出更多的空间线索,不同模态的特征在特征通道的重要性上是不同的,多模态特征需要重新校准以 强调各自的突出内容。 因此,提出了空间对齐和通道重新校准模块。 它首先在空间部分对齐两个模态,然后重新校准各自的通道部分,以更加关注每个模态中的显着内容。
首先计算公共空间注意力

然后,将公共空间注意图作为颜色特征和深度特征的权重,通过以下方式实现两种模式的空间对齐:

第三,空间部分 ![]() 中对齐的特征分别执行通道注意,以生成通道注意图,该图通过以下方式在每种模态中更显著的内容上显示更多权重:
中对齐的特征分别执行通道注意,以生成通道注意图,该图通过以下方式在每种模态中更显著的内容上显示更多权重:
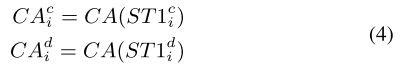
最后,将每个通道注意力图与原始特征相乘以实现通道重新校准。

在空间对齐和通道重新校准模块之后,增强的特征 ![]() 实现了位置对齐和通道重新校准,表现出更强的表示能力。
实现了位置对齐和通道重新校准,表现出更强的表示能力。
3.3边缘感知模块
高层特征有更多的语义信息,浅层特征有更多的细节,深度图像有更突出的边缘,所以,深度浅层特征用来产生边缘特征。
具体来说,![]() 进行 1×1 卷积运算和上采样运算,生成三个大小相同的特征,然后将它们连接起来生成边缘特征。
进行 1×1 卷积运算和上采样运算,生成三个大小相同的特征,然后将它们连接起来生成边缘特征。

接下来,对获得的边缘特征进行通道注意和残差连接,通过以下方式生成更清晰的边缘信息:

BConv(·)代表3×3卷积、批归一化层和ReLU激活
边缘感知模块输出边缘特征![]() ,这些特征将用于指导模型的解码过程并增强细节。
,这些特征将用于指导模型的解码过程并增强细节。
3.4边缘引导解码器
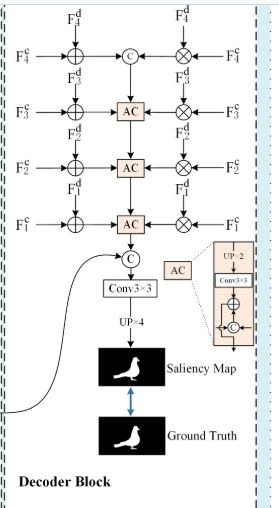
在空间对齐和通道重新校准和边缘特征提取之后,解码器将不同模态的增强层次特征与边缘特征相结合,产生边缘引导的显着特征。
![]()
接下来,根据 U-Net 框架[72]中广泛使用的解码思想,通过以下方式将高级融合特征逐步聚合为浅层融合特征:

最后,边缘感知模块的边缘特征与融合特征相结合,生成边缘引导的显着特征 Fs。
