Vision Transformers for Dense Prediction
paper:https://arxiv.org/abs/2103.13413
code:https://github.com/intel-isl/DPT
Abstract
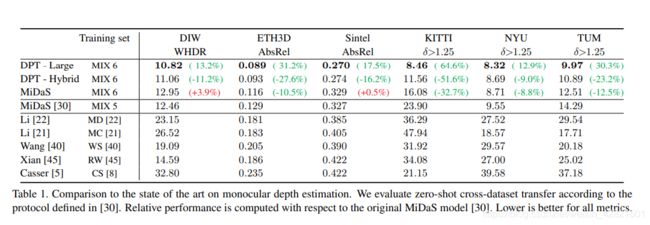
我们引入了密集视觉转换器,这是一种利用视觉转换器代替卷积网络作为密集预测任务的骨干架构。我们将视觉转换器的各个阶段的tokens组合成各种分辨率的类图像表示,并使用卷积解码器逐步将它们组合成全分辨率预测。转换器的主干过程表示在一个恒定的和相对高的分辨率,并在每个阶段有一个全局感受野。与完全卷积网络相比,这些属性允许密集视觉转换器提供更细粒度和更全局一致的预测finer-grained and more globally coherent predictions。我们的实验表明,该体系结构在密集的预测任务中产生了实质性的改进,特别是当有大量训练数据可用时。对于单目深度估计,我们观察到与最先进的全卷积网络相比,其相对性能提高了28%。
Introduction
几乎所有现有的密集预测体系结构都是基于卷积网络的。密集预测体系结构的设计通常遵循这样一种模式,即在逻辑上将网络分离为一个编码器和一个解码器。编码器通常基于图像分类网络,也称为主干,它是在一个大型语料库(如ImageNet)上进行预训练的。解码器聚合来自编码器的特征,并将其转换为最终的密集预测 。 密集预测的体系结构研究经常关注解码器及其聚合策略,然而普遍认为,骨干架构的选择对整个模型的能力有很大的影响,因为在编码器中丢失的任何信息都不可能在解码器中恢复。
卷积骨干逐步向下采样输入图像,提取多尺度特征。下采样使接收野逐渐增加,将低级特征分组为抽象的高级特征,同时确保网络的内存和计算需求保持易于处理。然而,下采样有明显的缺点,在密集的预测任务中尤其突出:特征分辨率和粒度在模型的更深阶段丢失,因此很难在解码器中恢复。虽然特征分辨率和粒度对于某些任务(如图像分类)可能无关紧要,但它们对于密集预测至关重要,在理想情况下,体系结构应该能够在输入图像的分辨率上或接近于输入图像的分辨率上分辨特征。
减少特性粒度损失的各种技术已经被提出。包括更高的输入分辨率(如果计算预算允许),膨胀卷积在不进行下采样的前提下快速增大感受野,从编码器的多个阶段适当放置跳跃连接到解码器,或者,最近,通过在网络中连接并行的多分辨率特征表示。虽然这些技术可以显著改进预测质量,但是网络的瓶颈仍是它们的基本构造块:卷积。卷积与非线性模块一起构成了图像分析网络的基本计算单元。卷积,根据定义,是有限制感受野的线性算子。单个卷积的有限的接受域和有限的表达能力需要序列叠加到非常深的架构中,以获得足够广泛的背景和足够高的表征能力。然而,这需要生产许多中间表征,消耗大量的内存。为了使内存消耗保持在现有计算机体系结构可行的水平上,降低中间表示的采样是必要的。
在本工作中,我们引入了密集预测变压器(DPT)。DPT是一种密集的预测体系结构,它基于编码器-解码器设计,利用转换器作为编码器的基本计算构建块。具体来说,我们使用最近提出的视觉转换器(ViT)作为主干架构。我们将由ViT提供的bag-of-words representation重组为各种分辨率下的类图像特征表示,并使用卷积解码器逐步将这些特征表示组合到最终的密集预测中。与完全卷积网络不同的是,视觉转换器主干在计算初始图像嵌入后放弃显式的降采样操作,并在所有处理阶段中保持不变的维数表示。此外,它在每个阶段都有一个全局接受域。我们表明,这些属性对于密集预测任务尤其有利,因为它们自然会导致细粒度和全局一致的预测fine-grained and globally coherent predictions。
Architecture
架构整体保持了过去成功用于密集预测的编码器-解码器结构。我们利用视觉转换器作为主干,展示了该编码器产生的表示如何有效地转化为密集的预测,并为该策略的成功提供了依据intuitition。完整架构的概述如图所示:
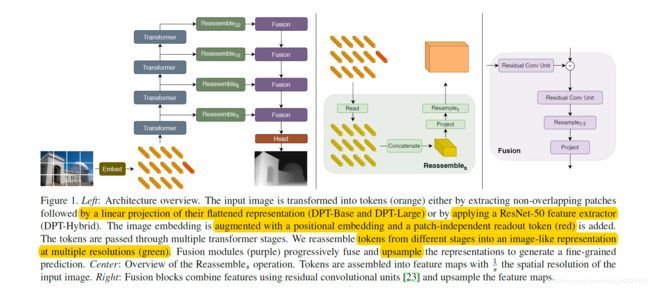
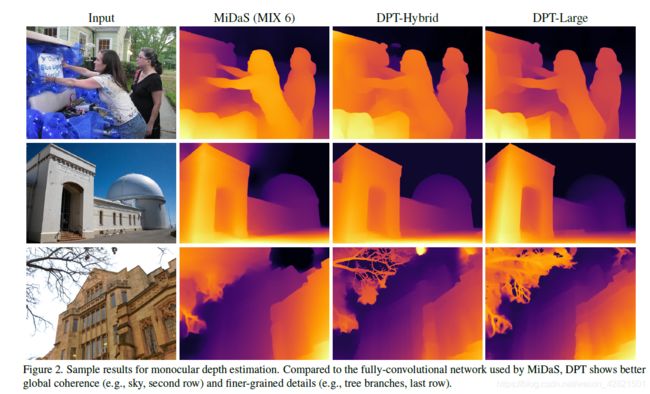
左:体系结构概述。输入图像被转换为标记(橙色),要么通过提取非重叠的patch,然后对其扁平表示进行线性投影(DPT-Base和DPT-Large),要么通过应用ResNet-50特征提取器(DPT-Hybrid)。图像嵌入用位置嵌入增强,并添加一个patch独立的读出标记(红色)。token通过多个转换器阶段传递。我们将不同阶段的标记重新组合成具有多种分辨率(绿色)的类图像表示。融合模块(紫色)逐步融合并上采样表示以生成细粒度预测。(还是用到了多尺度特征和上采样。。。)
中心:重组操作概述。token以1/s的输入图像空间分辨率组合成特征地图。
右:融合块使用残差卷积单元对特征进行组合,并对特征映射进行上采样。
Transformer encoder
在高层次上,视觉转换器(ViT)对图像的bag-of-words representation进行操作。image patch被单独嵌入特征空间,或者从图像中提取深度特征,充当文字word的角色。在接下来的工作中,我们将把嵌入的word称为token。变形器使用串联的**多头自注意(MHSA)**转换token集合,token彼此关联以转换表示。
对于我们的应用来说,重要的是,转换器在所有计算中维护的token的数量。由于令牌与图像patch具有一对一的对应关系,这意味着ViT编码器在所有变压器阶段都保持初始嵌入的空间分辨率。此外,MHSA本质上是一个全局的操作,因为每一个token都可以关注并影响每一个其他token。因此,在初始嵌入后的每一阶段,转换器都有一个全局的接受场。这与卷积网络形成了鲜明的对比,后者随着特征经过连续的卷积和下采样层而逐渐增加其接受域。
更具体地说,ViT通过处理图像中所有大小为p2像素的非重叠正方形patch,从图像中提取一个patch嵌入。这些patch被压平成矢量,并使用线性投影分别嵌入。另一种更高效的ViT变体通过对图像应用ResNet50来提取嵌入,并使用生成的特征映射的像素特征作为token。因为转换器是集合到集合的函数,它们本质上不保留单个标记的空间位置信息。因此,图像嵌入与可学习的位置嵌入相连接,以将该信息添加到表示中。在NLP工作之后,ViT还添加了一个特殊的token,它不是基于输入图像,而是作为用于分类的最终全局图像表示。我们将这个特殊的标记称为读出标记。对H*W大小的图像使用嵌入程序输出的结果是一组token组成的set,数量是HW/p^2, D是每个token的特征维度。

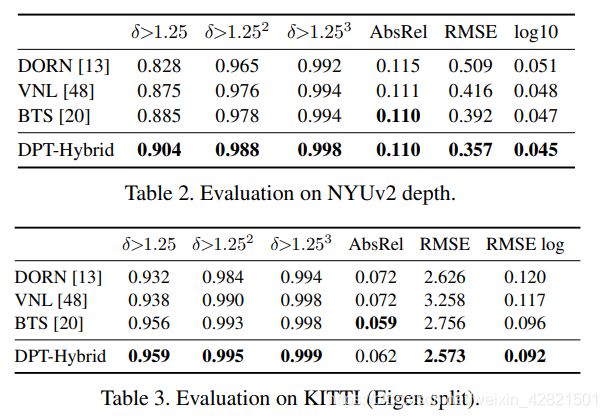
输入令牌使用L个变压器层转换为新的表示t^l,其中l表示第l个转换器层的输出。Dosovitskiy等人定义了这个基本蓝图的几种变体。我们在工作中使用了三种变体:ViT -base,它使用了基于patch的嵌入程序,具有12个转换器层;ViT-Large,采用相同的嵌入程序,有24个转换器层,特征尺寸D更宽;以及Vit - hybrid,它使用ResNet50来计算图像嵌入,然后使用12个转换器层。我们在所有实验中使用patch大小p = 16。有兴趣的读者可以参考原始著作[11]以获得关于这些架构的更多细节—>An image is worth 16x16 words: Transformers for image recognition at scale。
Vit-base和Vit-large的嵌入过程分别将压平的patch投射到维度D = 768和D = 1024。由于这两个特征维度都大于输入patch中像素的数量,这意味着如果对任务有益,嵌入过程可以学会保留信息。从输入patch中得到的特征原则上可以以像素级的精度处理。类似地,ViT-Hybrid架构在输入分辨率为1/16时提取特征,这是通常使用卷积主干的最低分辨率特征的两倍(同样有信息损失)。
Convolutional decoder
我们的解码器将一组标记组合成各种分辨率下的类似图像的特征表示。特征表示逐渐融合到最终的密集预测中。我们提出了一个简单的三阶段重组操作,从transformer编码器的任意层的输出标记恢复类似图像的表示:

我们首先将Np + 1标记映射到一组Np标记,这些标记可以被空间连接成类图像表示:
![]()
这个操作基本上负责适当地处理读出标记。由于读取标记没有为密集预测任务提供明确的目的,但可能仍然对捕获和分发全局信息有用,我们评估了这种映射的三种不同的变体:

通过将readout连接到所有其他token,将信息传递给其他token,然后使用线性层和GELU非线性将表示投射到原始特征维度D。
在read block之后,通过根据初始patch在图像中的位置放置每个token,可以将产生的Np标记重塑为类似图像的表示。形式上,我们应用一个空间连接操作,得到大小为HpWp的D通道特征映射。
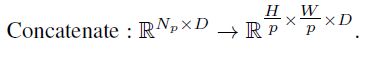
我们最终将此表示传递到一个空间重采样层,该层将表示缩放为大小HsWs,每像素具有D个特征:
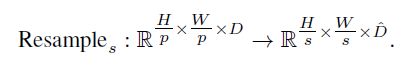
我们首先使用1个11卷积来实现这个操作将输入表示投影到D,然后是strided 33卷积时或转置卷积实现空间下采样和上采样操作。
不管使用哪种确切的transformer主干,我们在四个不同的阶段和四种不同的分辨率重新组合特征。我们以较低的分辨率聚合来自变压器较深层的特征,而以较高的分辨率聚合来自较浅层的特征。当使用Vit-large时,我们从层l = 5 12 18 24重新集合token;而对于Vit-base,我们使用层l = 3 6 9 12。我们使用来自嵌入网络的第一个和第二个ResNet块的特征,使用ViT-Hybrid时阶段l = 9 12 。我们的默认架构使用投影作为readout操作,并生成D= 256维的特征映射。我们将分别将这些架构称为DPT-Base、DPT-Large和DPT-Hybrid。
最后,我们利用基于refine-net的特征融合,将连续阶段提取的特征映射结合起来,,并在每个融合阶段逐步向上取样2倍。最终的表示尺寸只有输入图像分辨率的一半。我们附加一个特定于任务的输出头来产生最终的预测。
Handling varying image sizes
类似于完全卷积网络,DPT可以处理不同大小的图像。只要图像大小能被p整除,就可以应用嵌入程序,产生不同数量的图像标记Np。作为一种set-to-set的体系结构,transformer编码器可以简单地处理不同数量的令牌。但是,位置嵌入依赖于图像的大小,因为它对输入图像中的patch的位置进行编码。我们遵循ViT中提出的方法,将位置嵌入线性插值到适当的大小。上述操作可以在每个图像上动态完成。
在嵌入过程和转换阶段之后,只要输入图像与卷积解码器(32像素)的步幅对齐,重组和融合模块都可以简单地处理不同数量的标记。