【自然语言处理】【文本生成】Transformers中使用约束Beam Search指导文本生成
原文地址:https://huggingface.co/blog/constrained-beam-search
相关博客
【自然语言处理】【文本生成】CRINEG Loss:学习什么语言不建模
【自然语言处理】【文本生成】使用Transformers中的BART进行文本摘要
【自然语言处理】【文本生成】Transformers中使用约束Beam Search指导文本生成
【自然语言处理】【文本生成】Transformers中用于语言生成的不同解码方法
【自然语言处理】【文本生成】BART:用于自然语言生成、翻译和理解的降噪Sequence-to-Sequence预训练
【自然语言处理】【文本生成】UniLM:用于自然语言理解和生成的统一语言模型预训练
【自然语言处理】【多模态】OFA:通过简单的sequence-to-sequence学习框架统一架构、任务和模态
一、简介
不同于普通的beam search,约束beam search允许对文本生成的输出施加约束。这很有用,因为有时是确切知道在输出中需要什么。举例来说,在神经机器翻译中,可以知道哪些单词必须包含在最终的翻译中的。有时,由于特定的上下文,对于语言模型来说很有可能生成不满足用于期望的非结构。这两种情况都能够通过用户告诉模型输出结果中必须包含的单词来解决。
二、为什么困难
然而,这并不是一个简单的问题。这是因为该任务需要在生成过程中的某些位置上强制生成确定的子序列。
举例来说,若希望生成一个必须包含短语 p 1 = { t 1 , t 2 } p_1=\{t_1,t_2\} p1={t1,t2}的句子 S S S。定义一个期望句子 S S S为:
S e x p e c t e d = { s 1 , s 2 , … , t 1 , t 2 , s k + 1 , … , s n } S_{expected}=\{s_1,s_2,\dots,t_1,t_2,s_{k+1},\dots,s_n\} Sexpected={s1,s2,…,t1,t2,sk+1,…,sn}
问题是beam search生成序列是token-by-token的。虽然不完全准确,可以将beam search看作是函数 B ( s 0 : i ) = s i + 1 B(\textbf{s}_{0:i})=s_{i+1} B(s0:i)=si+1,其基于已经生成的0到i的token序列来预测i+1的下一个单词。但是该函数如何才能知道,在一个任意的步骤 i < k itoken必须在未来的步骤 k k k上生成特定的token?或者当其在时间步 i = k i=k i=k时,如何能够知道当前是生成token的最佳步骤,而不是未来的时间步 i > k i>k i>k?

若是有不同需求的多个约束呢?若是希望强制生成短语 p 1 = { t 1 , t 2 } p_1=\{t_1,t_2\} p1={t1,t2}和 p 2 = { t 3 , t 4 , t 5 , t 6 } p_2=\{t_3,t_4,t_5,t_6\} p2={t3,t4,t5,t6}?若是希望模型在两个短语中选择呢?若是想强制生成短语 p 1 p_1 p1和短语列表 { p 21 , p 22 , p 23 } \{p_{21},p_{22},p_{23}\} {p21,p22,p23}中的一个短语呢?
上面的例子都是非常合理的用例,正如下面展示的那样,新的约束beam search将会解决这些用例。
三、例子一:Forcing a Word
举例来说,尝试翻译How old are you?为德语。Wie alt bist du?是在非正式场合会说的话,Wie alt sind Sie?则是正式场合会说的话。更加上下文,可能需要其中的某一种形式,那么该如何告诉模型呢?
1. 传统Beam Search
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("t5-base")
model = AutoModelForSeq2SeqLM.from_pretrained("t5-base")
encoder_input_str = "translate English to German: How old are you?"
input_ids = tokenizer(encoder_input_str, return_tensors="pt").input_ids
outputs = model.generate(
input_ids,
num_beams=10,
num_return_sequences=1,
no_repeat_ngram_size=1,
remove_invalid_values=True,
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
输出:
Output:
----------------------------------------------------------------------------------------------------
Wie alt bist du?
2. 约束Beam Search
若希望输出的是正式场合的表达,而不是非正式场合?若通过先验知识知道生成必须包含的内,能够把其注入至生成中吗?
下面是在model.generate()中参数force_words_ids来实现该功能:
tokenizer = AutoTokenizer.from_pretrained("t5-base")
model = AutoModelForSeq2SeqLM.from_pretrained("t5-base")
encoder_input_str = "translate English to German: How old are you?"
force_words = ["Sie"]
input_ids = tokenizer(encoder_input_str, return_tensors="pt").input_ids
force_words_ids = tokenizer(force_words, add_special_tokens=False).input_ids
outputs = model.generate(
input_ids,
force_words_ids=force_words_ids,
num_beams=5,
num_return_sequences=1,
no_repeat_ngram_size=1,
remove_invalid_values=True,
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
输出:
Output:
----------------------------------------------------------------------------------------------------
Wie alt sind Sie?
可以看到,能够使用先验知识来指定生成。先前,必须生成一堆可能的输出,然后过滤出满足我们需求的。现在可以在生成阶段直接进行。
四、例子二:Disjunctive Constraints
在上面的例子中,我们是知道最终想要包含的单词。该场景的例子是在神经机器翻译中使用字典查找。
但是如果不知道单词的具体形式,希望等可能的输出 [ raining, rained, rains, … ] [\text{raining, rained, rains,}\dots] [raining, rained, rains,…]呢? 在更通用的场景中,总会存在一些情况不希望逐词、逐字的准确单词,并且可能需要考虑其他相关的可能。允许这种行为的约束称为Disjunctive Constraints,其允许用户输入单词列表并指导最终的输出必须包含单词列表中的至少1个词。
下面是一个混合了两种类型约束的例子:
from transformers import GPT2LMHeadModel, GPT2Tokenizer
model = GPT2LMHeadModel.from_pretrained("gpt2")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
force_word = "scared"
force_flexible = ["scream", "screams", "screaming", "screamed"]
force_words_ids = [
tokenizer([force_word], add_prefix_space=True, add_special_tokens=False).input_ids,
tokenizer(force_flexible, add_prefix_space=True, add_special_tokens=False).input_ids,
]
starting_text = ["The soldiers", "The child"]
input_ids = tokenizer(starting_text, return_tensors="pt").input_ids
outputs = model.generate(
input_ids,
force_words_ids=force_words_ids,
num_beams=10,
num_return_sequences=1,
no_repeat_ngram_size=1,
remove_invalid_values=True,
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
print(tokenizer.decode(outputs[1], skip_special_tokens=True))
输出:
Output:
----------------------------------------------------------------------------------------------------
The soldiers, who were all scared and screaming at each other as they tried to get out of the
The child was taken to a local hospital where she screamed and scared for her life, police said.
可以看到,第一个输出使用了screaming,第二个输出使用了screamed,并且两个输出都使用了scared。待选择的列表不一定是单词的形式,其可以是任何需要从单词列表中至少选择一个的。
五、传统Beam Search
不同于greedy search,beam search需要保存一个较长的hypotheses列表。下面是在num_beams=3的情况下,展示的beam search第一步:
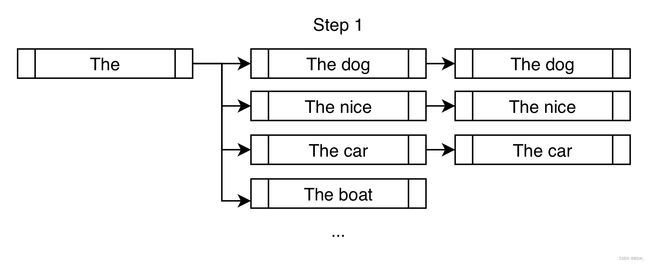
相比于greedy search仅选择The dog,beam search允许进一步考虑The nice和The car。在下一步中,将在上个步骤的三个分支上考虑接下来可能的tokens。

虽然最终考虑的输出远不止num_beams,但是在最后的时间步中缩减至num_beams。beam search不能一直往外延伸,beams的数量在 n n n个时间步为 beams n \text{beams}^n beamsn,其会非常快就达到非常大的情况。
对于生成的其余部分,重复上面的步骤直至满足结束标准,例如生成max_length。延伸、排序、缩减、重复。
六、约束Beam Search
约束beam search通过在每个生成步上注入期望的tokens来实现约束。
若要求在生成的输出中强制包含短语is fast。在传统的beam search设置中,在每个分支中寻找最可能的 k k k个下一个toekens,并且将其附近在末尾用于后续的考虑。在约束设置中,在做同样操作的同时,通过追加特定的token来逐步实现约束。
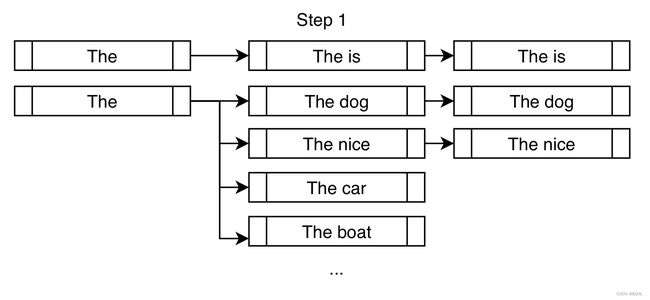
在常见的高概率下一个词dog和nice上方,强制添加is来使得更加接近实现约束is fast。
对于下一个步骤,扩展的候选与传统的beam search基本相同。就像上面的例子一样,约束beam search通过在每个分支上添加约束来添加新的候选:
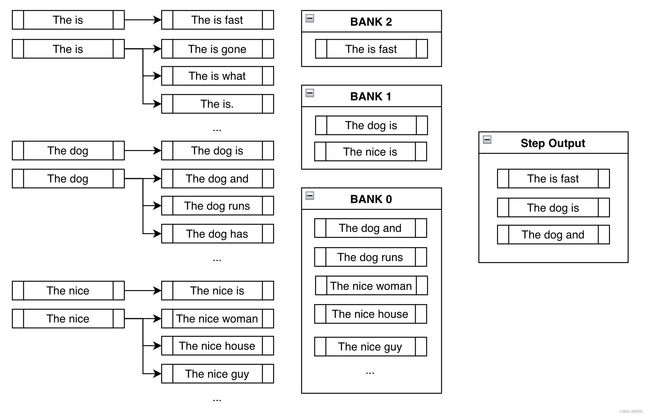
Banks
在讨论下一步之前,需要思考在上一步中所看到的不期望的行为。若单纯的强制在输出中包含is fast,大多数时候仅会得到像The is fast这样没有意义的输出。这个问题不容忽视。
Banks通过在实现约束和创造合理输出之间取得平衡来解决这个问题。Bank n在实现约束时已经进行了 n n n步的beamns列表。在各自对应的banks中对所有可能的beams进行排序,然后做循环筛选。在上面的例子中,从Bank 2选择最可能的输出,从Bank 1选择最可能的输出,从Bank 0选择最可能的输出,从Bank 2选择第二可能的输出,从Bank 1选择第二可能的输出,以此类推。由于上面的例子中num_beams=3,那么仅需要重复上面的过程三次就可以得到The is fast、The dog is和The dog and。
通过这种方式,即使我们强制模型考虑人工添加的分支,但是仍然可以追踪其他更有意义的高概率序列。即使The is fast完成的实现了约束,其也不是一个合理的短语。幸运的是,仍然有The dog is和The dog and能够在未来的时间步中使用,其在后面可能会带来更加合理的输出。
下面是该行为在第3个时间步的结果示例:

注意,The is fast不需要人工添加任何约束token,因为其已经实现了约束。此外,The dog is slow或者The dog is mad实际上在Bank 0,虽然其包含token is,但其必须从头开始生成is fast。通过在is后追加slow,能够有效的重置进度。
盲目的追加期望的token会导致像The is fast这样无意义的短语。然而,从banks中使用循环选择,最终可以摆脱无意义的输出,而选择更加合理的输出。
七、约束类和常用约束
上面的结论可以总结如下。在每个时间步,我们不断的催促模型来考虑能够实现约束的tokens,同时跟踪不满足约束的beams,直至最终得到包含期望短语的合理高概率序列。
因此,设计这种实现的一个准则是将每个约束表示为一个Constraint对象,其目的是跟踪进度并告诉beam search下一个生成的tokens。尽管已经在model.generate()中添加了关键字参数force_words_ids,下面是在后端实际发生的情况:
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, PhrasalConstraint
tokenizer = AutoTokenizer.from_pretrained("t5-base")
model = AutoModelForSeq2SeqLM.from_pretrained("t5-base")
encoder_input_str = "translate English to German: How old are you?"
constraints = [
PhrasalConstraint(
tokenizer("Sie", add_special_tokens=False).input_ids
)
]
input_ids = tokenizer(encoder_input_str, return_tensors="pt").input_ids
outputs = model.generate(
input_ids,
constraints=constraints,
num_beams=10,
num_return_sequences=1,
no_repeat_ngram_size=1,
remove_invalid_values=True,
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
输出:
Output:
----------------------------------------------------------------------------------------------------
Wie alt sind Sie?
你也可以自己定义约束,并将其输入至constraints关键字参数中。你必须创建一个Constraint抽象接口类的子类,并遵循其要求。
一些独特的想法,包括像OrderedConstraints、TemplateConstraints等后续会被添加。目前,生成是通过包含输出中任何位置的序列来实现的。举例来说,先前的例子中有一个序列具有scared->screaming和另一个序列screamed->scared。OrderedConstraints能够允许用户指定约束实现的顺序。
TemplateConstraints可以允许更加小众的功能,其目标类似于:
starting_text = "The woman"
template = ["the", "", "School of", "", "in"]
possible_outputs == [
"The woman attended the Ross School of Business in Michigan.",
"The woman was the administrator for the Harvard School of Business in MA."
]
或者
starting_text = "The woman"
template = ["the", "", "", "University", "", "in"]
possible_outputs == [
"The woman attended the Carnegie Mellon University in Pittsburgh.",
]
impossible_outputs == [
"The woman attended the Harvard University in MA."
]