【opencv】(9) 图像识别实战:银行卡数字识别,附python完整代码和数据集
各位同学大家好,今天我和大家分享一下opencv机器视觉实战项目,识别银行卡上的数字,该方法也同样适用于车牌数字识别。
数据集免费: https://download.csdn.net/download/dgvv4/54191107
代码免费:【16】实战--银行卡数字识别.py-Python文档类资源-CSDN下载
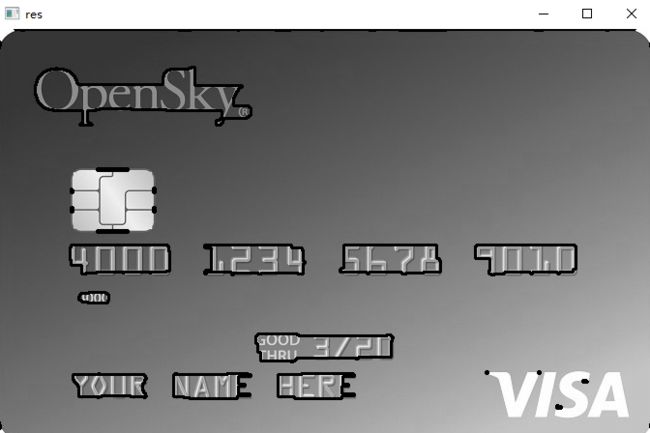
案例简介:现在有5张银行卡,1张数字模版。先对数字模板上的每个数字进行识别,再对银行卡的进行形态学处理,找出银行卡数字组合所在位置,取出每个数字组合的每一个数字,与模板进行匹配,将匹配结果输出。下面展示一张银行卡的结果,左图为灰度图,右图为结果。


开始之前,我们先导入需要的库,再定义一个画图函数,方便后续展示。为了方便大家理解,全文只有这一个自定义函数,我尽量多分成几个步骤来展示,不跳步,代码尽量写的通俗,希望大家能够掌握。如果有些函数不懂的可以看我之前的一些文章。
import cv2
import numpy as np
# 指定图片所在文件夹
filepath = 'C:\\Users\\...\\img\\card'
# 图像显示函数,全文唯一的自定义函数
def cv_show(name,img):
cv2.imshow(name,img) # (自定义图像名,图像变量)
cv2.waitKey(0) # 图像窗口不会自动关闭
cv2.destroyAllWindows() # 手动关闭窗口
1. 模板处理
1.1 模板预处理
首先我们将先前准备的数字模板读进来,注意,这个模板的数字必须要和需要识别的数字的格式差不多。使用cv2.cvtColor()函数将图像转变为灰度图。二值化处理使用图像阈值函数cv2.threshold(),参数THRESH_BINARY_INV指超过阈值的变成0没超过的变成指定的maxval。轮廓检测函数cv2.findContours()我们只检测最外层轮廓。它有两个返回值,contours保存的是检测到的所有轮廓信息,hierarchy保存的是轮廓信息分层次存放,用不到它。轮廓绘制函数cv2.drawContours(),第1个参数是画板,第2个参数是轮廓信息,"-1"代表画出轮廓信息中的所有轮廓。
# 读取模板图像
reference = cv2.imread(filepath+'\\reference.png') # 获取指定文件夹下的某张图片
cv_show('reference',reference) # 展示模板图
# 转换灰度图,颜色改变函数
ref = cv2.cvtColor(reference, cv2.COLOR_BGR2GRAY)
cv_show('gray',ref)
# 二值化处理,图像阈值函数,像素值超过127变成0,否则变成255
ret,thresh = cv2.threshold(ref,127,255,cv2.THRESH_BINARY_INV)
cv_show('threshold',thresh) # 返回值ret是阈值,thresh是二值化图像
# 轮廓检测。第1个参数是二值图。第2个参数检测最外层轮廓,第3个参数保留轮廓终点坐标
contours,hierarchy = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 返回轮廓信息和轮廓层数
# 绘制轮廓
draw = reference.copy() # 复制一份原图像作为画板,不能在原图上画,不然原图会改变
res = cv2.drawContours(draw, contours, -1, (0,0,255), 2) #"-1"是指在画板上画出所有轮廓信息,红色,线宽为2
cv_show('res',res)
print(np.array(contours).shape) # 显示有多少个轮廓 10个
下图第一张为二值化处理后的结果,第二张为绘制轮廓后的结果

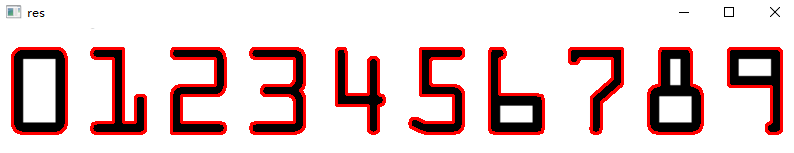
1.2 模板排序
通过模板轮廓检测函数,我们得到了10个数字的轮廓,但是这10个轮廓不一定是按顺序排列的,可能是数字"1"对应索引8。因此我们需要对轮廓的顺序进行一个排序,之后我们就可以通过下标索引直接找到数字模板的图像,即下标索引1对应数字图像"1"。
我们可以通过之前检测到的轮廓信息,计算轮廓的外接矩形,得到每一个外接矩形的左上角坐标(x, y)和矩形的宽w高h,统一保存到boxing变量中,通过x坐标的大小来对轮廓排序。我们使用最基础的冒泡排序的方法来对轮廓换位置。cv2.boundingRect()外接矩形计算函数和cv2.findContours()外接轮廓检测函数,返回的都是元组类型,在冒泡排序交换值的过程中可能会存在问题,我们将其转换为数组类型。
#(2)模板排序
# 求每一个轮廓的外接矩形,根据返回的左上坐标点,就能判断出轮廓的位置,再排序
# boxing中存放每次计算轮廓外接矩形得到的x、y、w、h,它的shape为(10,4)。cnt存放每一个轮廓
boxing = [np.array(cv2.boundingRect(cnt)) for cnt in contours]
contours = np.array(contours)
# 都变成数组类型,为了下面冒泡排序能相互交换值。上面默认返回的是元组类型,它只能读不能写
# 把x坐标最小轮廓的排在第一个
for i in range(9): #冒泡排序
for j in range(i+1,10):
if boxing[i][0]>boxing[j][0]: #把x坐标大的值放到后面
# 给boxing中的值换位置
boxing[i],boxing[j] = boxing[j],boxing[i]
# 给轮廓信息换位置
contours[i],contours[j] = contours[j],contours[i]
1.3 模板数字区域对应具体数字
在完成模板数字排序后,就可以使用每一个下标索引来对应一个模板数字图像。enumerate()函数返回变量中的值的下标,和下标所对应的值。ref是之前输入的模板的灰度图,我们现在有每一个轮廓外接矩形的左上坐标(x,y)宽w高h,就可以在灰度图上把这个矩形区域挖出来。i=0时,有图像0的外接矩形的坐标和高宽,挖出这个图像0,使用变量roi保存这个区域的数据。把值赋给字典,字典的key是0,value就是图像0。完成了下标对应模板数字的任务。
#(3)遍历每一个轮廓,给每一个轮廓对应具体数字
# 定义一个字典,具体数字对应具体框
dic = {}
for i,cnt in enumerate(contours): #返回轮廓下标和对应的轮廓值
x,y,w,h = boxing[i] # boxing中存放的是每个轮廓的信息
roi = ref[y:y+h,x:x+w] # ref是灰度图像,ref中依次保存的是高和宽,即(y,x)
# 将每个区域对应一个数字
roi = cv2.resize(roi,(25,30)) # roi区域统一大小,根据自己需求来定
dic[i] = roi
cv_show('roi',roi) # 单独显示每张图片
# 组合在一起看一下
plt.subplot(2,5,i+1)
plt.imshow(roi,'gray'),plt.xticks([]),plt.yticks([]) #不显示xy轴刻度
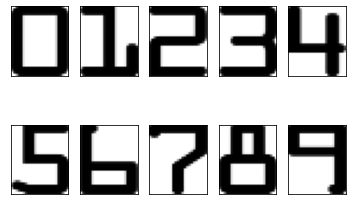
在挖图像的时候可以留一点空间,不至于那么挤,比如roi = ref[y-5 : y+h+5, x-5 : x+w+5]。根据个人需要。下图为我们取出来的每一个数。
2. 银行卡处理
这里是重点,比较困难,我分了很多步,尽量写的通俗,都可以单独运行,希望大家能理解
2.1 银行卡读取
我们有5张银行卡,需要进行批量处理,注意图片保存时的命名格式,一定要统一。我对五张卡的命名分别是card1、card2...、card5,使用f'\\card{i+1}.png',随着i的变化会自动读入需要的图片。
#(1)读入银行卡数据,转换灰度图
img = [] # 存放5张银行卡数据
for i in range(5): # 使用循环读取,注意图片名一定要统一
img_read = cv2.imread(filepath+f'\\card{i+1}.png',0) # 0表示灰度图
img.append(img_read)
cv_show('card1',img[0])
2. 形态学处理--礼帽
为了使这些数字部分能更突出,我们进行形态学处理cv2.morphologyEx(),定义一个卷积核,也可以使用numpy的方法构建卷积核。使用礼帽方法:原始图像减开运算结果。用来获取原图像中比周围亮的区域,取出白色重叠部分。对每一张图片都进行礼帽操作。将处理后的图像保存到img_treated。
#(2)形态学处理,使用礼帽操作,获取原图像中比周围亮的区域
img_treated = [] # 存放处理后的图片数据
for img_treat in img:
# 定义一个卷积核,MORPH_RECT矩形,size为9*3
rectkernel = cv2.getStructuringElement(cv2.MORPH_RECT, (9,3)) #每一组数字的长宽比是9*3
# 礼帽,突出更明亮的区域
tophat = cv2.morphologyEx(img_treat,cv2.cv2.MORPH_TOPHAT,rectkernel)
img_treated.append(tophat)
# 绘图看一下
cv_show('hat',img_treated[0])
3. 边缘检测--canny
对礼帽处理后的每一张图像进行边缘检测,使用canny方法cv2.Canny(),也可以使用sobel方法。自定义双阈值,阈值指定的小,对边缘的要求没那么高,能检测出尽可能多的边界。检测结果存放在img_cannyed中。
#(3)边缘检测,canny边缘检测
img_cannyed = [] #存放处理后的数据
for img_canny in img_treated:
img_canny = cv2.Canny(img_canny,80,200) #自定义最小和最大阈值
img_cannyed.append(img_canny)
# 绘图看一下
cv_show('canny',img_cannyed[0])
4. 形态学处理--闭操作
对边缘检测后的所有图像进行闭操作cv2.MORPH_CLOSE,先膨胀后腐蚀。用于填补内部黑色小空洞,填充图像。使用的卷积核还是上面礼帽操作定义的卷积核rectkernel,也可以重新定义。迭代3次,进行三次闭操作iterations=3。处理后的结果保存在img_closed中。
#(4)通过闭操作(先膨胀后腐蚀),将轮廓连在一起
img_closed = [] #存放闭操作之后的结果
for img_close in img_cannyed:
img_close = cv2.morphologyEx(img_close, cv2.MORPH_CLOSE, rectkernel,iterations=3) #使用第(3)步定义的9*3的卷积核
img_closed.append(img_close)
# 绘图看一下
cv_show('closed',img_closed[0])
5. 计算轮廓
对闭操作之后的每张图像计算轮廓,使用轮廓检测函数cv2.findContours(),指定参数cv2.RETR_EXTERNAL获取最外层轮廓,cv2.CHAIN_APPROX_SIMPLE只返回轮廓的终点坐标信息。在绘制轮廓时将原图像先复制一份作为画板draw,不然原图像会改变。使用轮廓绘制函数cv2.drawContours(),"-1"代表绘制所有的轮廓信息contours
#(5)计算轮廓
img_cnted = [] # 存放处理后的结果
num = 0 # 原图像的索引号
for img_cnt in img_closed:
# 轮廓检测,只绘制最外层轮廓
contours,hierarchy = cv2.findContours(img_cnt, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 返回轮廓信息和轮廓层数
# 绘制轮廓
draw = img[num].copy() ;num += 1 # 复制一份原图像作为画板,不能在原图上画,不然原图会改变
res = cv2.drawContours(draw, contours, -1, (0,0,255), 2) #在画板上画出所有轮廓信息"-1",红色线宽为2
cv_show('res',res)
img_cnted.append(contours)展示2张银行卡的轮廓线

6. 轮廓筛选
只使用一张图片img_cnted[0]来演示,方便大家理解,在外面套一层循环就可以实现多张图片处理
如上图,我们得到了很多个轮廓,只有中间的数字轮廓是需要的,因此我们可以根据轮廓外接矩形的宽高比来筛选轮廓,具体的比例数值根据需求来选。这里只保留比例在[2.5, 4]之间的矩形,并且宽度w和高度h需要满足一定的要求,才将它进行保留。对保留的轮廓信息,根据外接矩形的左上角坐标的x轴大小来排序,使用最基础的冒泡排序。这样就将四个数值轮廓按顺序选出来了。
#(6)筛选轮廓,排序
# ==1== 筛选轮廓
loc = [] # 存放img_cnted[0]图片排序后的轮廓要素
mess = [] # 每img_cnted[0]图片排序后的轮廓信息
for (i,c) in enumerate(img_cnted[0]): #返回下标和对应值
# 每一个轮廓的外接矩形要素
(x,y,w,h) = cv2.boundingRect(c)
ar = w/float(h) # 计算长宽比
# 选择合适的长宽比
if ar>2.5 and ar<4:
if (w>90 and w<100) and (h>25 and h<35):
# 符合要求的留下
loc.append((x,y,w,h))
mess.append(c)
# ==2== 轮廓排序
# 将符合的轮廓从左到右排序
# 把x坐标最小轮廓的排在第一个
for i in range(len(loc)-1): #冒泡排序
for j in range(i+1,len(loc)):
if loc[i][0]>loc[j][0]: #把x坐标大的值放到后面
# 交换轮廓要素信息
loc[i],loc[j] = loc[j],loc[i]
# 交换对应的轮廓信息
mess[i],mess[j] = mess[j],mess[i]
7. 轮廓内数字提取
接下来会使用一个大循环,内容知识点较多,为了大家能理解,我只使用一张图片img_cnted[0]来演示,看懂了以后直接在外面再套一层循环就行。为了运行效果,我就不打断循环了,具体注释已经在文中标注,每一步的运行结果图在下方。不明白的可以评论,随时回答。
output = [] # 保存最终数字识别结果
#(7)根据轮廓提取每一组数字组合
for (i, (x,y,w,h)) in enumerate(loc): # loc中存放的是每一个组合的xywh
groupoutput = [] #存放取出来的数字组合
group = img[0][y-5:y+h+5,x-5:x+w+5] # 每个组合的坐标范围是[x:x+w][y:y+h],加减5是为了给周围留点空间
cv_show('group',group)
#(8)每次取出的轮廓预处理,二值化
# THRESH_OUT会自动寻找合适的阈值,合适的双峰(两种主体),把阈值参数置为0
ret,group = cv2.threshold(group,0,255,cv2.THRESH_BINARY | cv2.THRESH_OTSU) #二值化处理
cv_show('group',group) #ret是返回的阈值,group是返回的二值化后的图像
#(9)每个数字的小轮廓检测,只检测最外层轮廓RETR_EXTERNAL,返回轮廓各个终点的坐标CHAIN_APPROX_SIMPLE
contours,hierarchy = cv2.findContours(group, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 返回轮廓信息和轮廓层数
# 对轮廓排序,boxing中存放每次计算轮廓外接矩形得到的x、y、w、h
boxing = [np.array(cv2.boundingRect(cnt)) for cnt in contours]
contours = np.array(contours) # 都变成数组类型,下面冒泡排序能相互交换值,元组类型只读不能写
# 把x坐标最小轮廓的排在第一个
for i in range(3): #冒泡排序
for j in range(i+1,4):
if boxing[i][0]>boxing[j][0]: #把x坐标大的值放到后面
# 给boxing中的值换位置
boxing[i],boxing[j] = boxing[j],boxing[i]
# 给轮廓信息换位置
contours[i],contours[j] = contours[j],contours[i]
#(10)给排序后的轮廓分别计算每一个数字组合中的每一个数字
for c in contours: # c代表每一个数字小轮廓
(gx,gy,gw,gh) = cv2.boundingRect(c) # 计算每一个数字小轮廓的x,y,w,h
roi = group[gy:gy+gh,gx:gx+gw] # 在数字组合中扣除每一个数字区域
roi = cv2.resize(roi,(25,30)) # 大小和最开始resize的模板大小一样
cv_show('roi',roi) # 扣出了所有的数字
#(11)开始模板匹配,对每一个roi进行匹配
score = [] # 定义模板匹配度得分变量
# 从模板中逐一取出数字和刚取出来的roi比较
for (dic_key, dic_value) in dic.items(): # items()函数从我们最开始定义的模板字典中取出索引和值
# 模板匹配,计算归一化相关系数cv2.TM_CCOEFF_NORMED,计算结果越接近1,越相关
res = cv2.matchTemplate(roi,dic_value,cv2.TM_CCOEFF_NORMED)
# 返回最值及最值位置,在这里我们需要的是最小值的得分,不同的匹配度计算方法的选择不同
min_val,max_val,min_loc,max_loc = cv2.minMaxLoc(res)
score.append(max_val)
# 当roi与模板中的10个数比较完以后,score中保存的是roi和每一个数字匹配后的结果
# score中值最小的位置,就是roi对应的数字
score = np.abs(score) # 有负数出现,统一成正数,相关系数都变成正数
best_index = np.argmax(score) # score最大值的下标,匹配度最高
best_value = str(best_index) # 下标就是对应的数字,在字典中,key是0对应的是值为0的图片
groupoutput.append(best_value) # 将对应的数字保存
# 打印识别结果
print(groupoutput)
#(12)把我们识别处理的数字在原图上画出来,指定矩形框的左上角坐标和右下角坐标
cv2.rectangle(img[0],(x-5,y-5),(x+w+5,y+h+5),(0,0,255),1)
# 在矩形框上绘图
cv2.putText(img[0], ''.join(groupoutput), (x,y-10), cv2.FONT_HERSHEY_SIMPLEX, 0.65, (0,0,255), 2)
# 将得到的数字结果保存在一起
output.append(groupoutput)
#(13)循环结束,展示结果
cv_show('img',img[0])
print('数字为:',output)第(7)步提取的数字组合的结果图
![]()
第(8)步二值化后的图像
![]()
第(9、10)步数字小轮廓检测,并通过外接矩形把数字从原图中抠出来
![]()
第(11)步模板匹配,每次print(groupoutput)的结果如下

最后,展示结果
