生成式摘要调研
1、Coreference-Aware Dialogue Summarization
在一个经典文章上做出实验。
定义新的评价方式——很难,不要做过多讨论
看指代消解对摘要是否影响很大,问题——要自己标数据集,查找是否有相应的语料
图网络建立,节点间的重合。在这方面进行优化
看一下指代消解本身是否有意义,值不值得做。
看新的文章有没有类似的事情。
确认好:(1)有数据集 (2)目前的得分一般
分享论文时,要深入理解一篇文章。
把共指信息通过GNN融入到系统中,提升factual correctness
创新点:首次通过GNN将共指信息融入到对话摘要中(之前只有对文档进行共指消解)
可以做出改进的地方:
在GNN结构上进行改进,添加其他语义信息,定义新的评价方式…
模型受共称消解质量的影响,如果共称消解质量低,模型的效果会被影响。


摘要
目前的对话摘要存在的问题有:非结构信息、说话人之间的非正式交互、随着对话发展说话人角色的动态变化。这些问题产生了复杂的共指关系。这篇文章调查了多种方式,关于详细地融合了共指信息在神经生成式对话摘要模型中,去解决这些问题。
研究结果表明融入共指信息在对话系统中是有作用的,对事实正确性的评估结果表明,这种共指感知模型更擅长跟踪对话者之间的信息流,并将准确的状态/动作与相应的对话者和人物提及相关联。
介绍
总结
模型:用GNN提取潜在的共指信息:共指注意力层,指导预测分析
数据集:SAMSum
原文
研究历史:
Most prior work focuses on summarizing well-organized single-speaker con- tent such as news articles (Hermann et al., 2015) and encyclopedia documents (Liu* et al., 2018)
on the popular benchmark corpus CNN/Daily Mail (Hermann et al., 2015), Liu and Lapata (2019) explored fine-tuning BERT (De- vlin et al., 2019) to achieve state-of-the-art per- formance for extractive news summarization, and BART (Lewis et al., 2020) has also improved gen- eration quality on abstractive summarization.
相比文档摘要的情况,对话摘要没有收到多少的关注。Unlike documents, conver- sations are interactions among multiple speakers, they are less structured and are interspersed with more informal linguistic usage (Sacks et al., 1978). Based on the characteristics of human-to-human conversations (Jurafsky and Martin, 2008)。对话摘要的挑战包括:(1)多说话人,对话者之间的交互式信息交换意味着重要信息在说话者和对话轮次之间来回参考。(2)说话人角色的转换,多轮对话通常包含频繁的角色转换,从一种说话人的类型到另一种。(3)无处不在的指称表达:说话者除了指代自己和彼此外,还提到第三方的人、概念和对象。此外,指称也可以采用回指(anaphora)或下指(cataphora)等形式,其中使用了代词,使参考链更难以追踪。如果对共指信息没有足够的理解,基础摘要器就无法将提及与其前因联系起来,并在生成中产生不正确的描述。从上述语言特征来看,对话具有复杂共指的多个内在来源,促使我们明确地考虑对话总结的共指信息,以更恰当地建模上下文,更动态地跟踪整个对话中的交互信息流, 并实现多跳对话推理的潜力。
过去的工作在对话摘要中注意在建模对话主题和对话动作。(Goo and Chen, 2018; Liu et al., 2019; Li et al., 2019; Chen and Yang, 2020).很少明确利用来自共指信息的特征。 另一方面,大规模预训练语言模型仅用于隐式建模低级语言知识,例如词性和句法结构。(Tenney et al., 2019; Jawa- har et al., 2019). 如果没有直接训练提供特定和显式语言注释的任务,例如共指解析或语义相关推理,模型性能仍然低于语言生成任务。(Dasigi et al., 2019). 因此这篇文章提出了通过详细地融合共指信息的生成式文本摘要模型。因为实体之间通过共指链来连接,我们推测添加一个图神经网络层可以提取潜在信息,从而增强上下文表达。文章探索了两种参数有效的策略:一个是用额外的共指指导的注意力层(coreference-guided attention layer),另一种方法是通过进行探测分析来增强我们的共指注入设计,从而巧妙地增强了 BART 有限的共指解析能力。在SAMSum上数据集的表示验证了模型是有效的。此外,人类评估和错误的分析表明我们的模型产生了与事实一致的摘要。
相关工作
Rush et al. (2015) 提出了基于注意力的神经网络摘要模型,使用了s2s生成结构。proposed an attention-based neural summarizer with sequence-to-sequence generation.
指针网络,Pointer-generator network(See et al., 2017) 可以直接从原文当中直接拷贝,解决了out of vocabulary 的问题。
Liu and Lapata (2019)提出了用预训练模型BERT去解决抽取和生成式摘要。
Lewis et al. (2020) proposed BART,利用BERT的双向编码器和GPT(Radford et al., 2018) 的自回归解码器去获得很好的结果。
一些研究关注在摘要一些很有结构性的文字,比如新闻文章(Hermann et al., 2015)对话摘要已经赢得了关注。
Shang et al. (2018) 提出一个非监督多句子压缩方法对于会议的摘要unsu- pervised multi-sentence compression method
Goo and Chen (2018)引入了一个sentence-gated机制去抓住对话动作的关系。
Liu et al. (2019)提出了使用主题分段和turn-level (Liu and Chen, 2019) 信息对于对话任务。
Zhao et al. (2019)提出了一个神经网络模型有着hierarchical层级编码器和reinforced加强解码器去产生会议摘要。
Chen and Yang (2020) 是用了不同的对话结构像是主题分段topic segment和对话状态conversational stage设计一个多视角摘要,并且实现了当前SAM-Sum的sota
提升事实正确性已经收到了生成式摘要模型的热切关注
Cao et al. (2018) 应用了dependency pars- ing and open informationt extraction增强生成摘要的可靠性。
Zhu et al. (2021) 提出了一个factual corrector model基于知识图谱,极大地提升了文本摘要的factual correctness
对话共指消解
因为普通的摘要数据集没有包含共指标注,自动共指消解需要处理样本。
Neural approaches(Joshi et al., 2020) 展示了令人深刻的能力在文档共指消解上。然而他们仍然是对话场景的次选择(Chen et al., 2017),没有大规模的标注的对话预料对于迁移学习。
当采纳文本共指消解模型(Lee et al., 2018; Joshi et al., 2020) 在对话样本,没有domain adaption时,我们观察到了一些问题:
(1)每段对话的第一个token是说话人,但有时没有被识别
(2)在对话中,一个共指链中的词会被拆解为多个。
(3)可能会把不同共指链的词划归到一起。

基于观察,为了提升对话指称消解,我们对自动输出进行了数据后处理(we conducted data post-processing on the automatic output):
(1)我们应用了模型集成策略来获得更准确的划分预测
(2)然后,我们为没有包含在任何链中的说话人角色重新分配了共指集群标签;
(3)我们比较了集群并合并了那些呈现相同共指链的集群。
基于人类评估关于处理的数据表明,这个后处理减少了共指任务的错误性达到了19%
Coreference-Aware Summarization
总结
用共指特征作为辅助来提升编码器,具体做法为:
(1)构建一个GNN网络,节点表示实体,边表示相关性
(2)用GCN进行迭代更新
(3)通过注意力机制将共指信息融入进representation中
(4)将提取出的信息替换成多头注意力机制中的头,进行自回归解码。
原文
在这一个模型中,我们采纳了一个神经网络模型对于生成式摘要,并且调查了融合入不同共指信息的不同的方法对于提升它。
基础神经网络模型是一个s2s模型transformer(Vaswani et al., 2017)
给定包含n个词的对话,一个基于子注意力机制的编码器被用于提取上下文的隐向量表示,然后一个自回归解码器产生了目标序列。这里,我们使用了BART (Lewis et al., 2020)预训练语言模型基础,并进行fine-tuning
对于每一个对话,有一系列的共指簇,每一个簇包含了一些实体。拿这个多轮对话举例

有三个不同的共指簇(黄色红色和蓝色)每一个共指簇包含大量的词序列。在对话交互中,参考的代词是重要的对于上下文的语义理解 (Sacks et al., 1978), 因此我们预测合并共指信息是有效的对语声称是对话摘要。在这篇文章中,我们主要是为了用辅助的共指特征提升编码器。
4.1基于GNN的共指融合
由于共指链中的实体相互链接,图形表示可以很容易地表征底层结构并促进相互连接关系的计算建模。在过去的文章中,图卷积神经网络(Kipf and Welling, 2017) 展示了强大的建模图特征的性能。
4.1.1共指图的构建
为了建立一个共指簇的链,我们添加了每个实体和他们的mention的联系。不像过去的工作 (Xu et al., 2020),一个簇中的实体都指向第一个occurrence,在这里我们链接了相邻对去保留更多的局部信息。更具体的说法是,给定一个簇的实体,我们给每一个E添加了和他前面的连接。

然后每一个实体链被转换成一个图,输入到了GNN当中。给一个文本中包含n个字符(这里用了sub-word tokenization),一个共指图G被有n个节点和一个空的邻接矩阵初始化。迭代每个共指集群 C,每个提及(一个词或一个文本跨度)的第一个标记 ti 与其在同一集群中的先行词的第一个标记 tj 连接,具有双向边,

4.1.2 GNN Encoder
给定一个带有节点(对话中带有共指信息的词/跨度)和边(提及之间的链接)的图 G,我们使用堆叠图建模层stacked graph modeling layers来更新所有节点的隐藏表示 H。这里,我们采用了一个单边的共指网络编码层(CGE)作为一个例子:CGE层的第一个输入是Transformer编码器的输出H,我们denote第k个CGE的层为H,并且第k+1个层的表示如下。
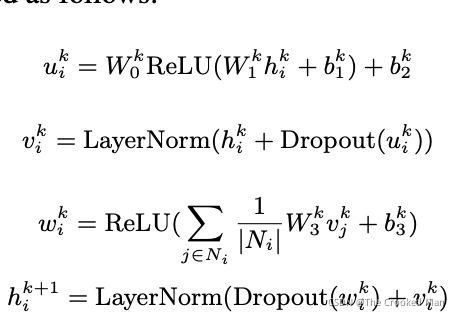
w和b表示矩阵参数
层归一化 Ni表示第i个节点的相邻节点。
在特征传递后,我们提取了最终的表示通过添加共指信息层HG用contextualized隐状态H,然后用自回归解码器去产生摘要。
4.2共指指导注意力
除了基于GNN的方法引入了一些额外的参数外,我们还探索了一个没有参数的模型。
自注意力机制(Vaswani et al., 2017),上下文信息能够被注意力加权获得。对于实体在一个上下文簇中,他们能够分享共指信息在语义的层面上。对于参考集群中的实体,它们都在语义级别共享参考信息。 因此,我们建议通过上下文表示中的一个额外注意层来融合共指信息。
给定一个具有共指簇的样本,构建一个共指引导的注意层来更新编码表示 H

由于同一共指集群中的项目彼此相关,因此注意力权重矩阵 Ac 中的值用一个集群中所有引用提及的数量进行归一化,然后表示h就通过下面的公式更新。

4.3 已知共指信息的transformer
虽然预先训练的模型带来了显着的改进,但对于需要高级语义理解的任务(例如共指解析),它们仍然存在不足的先验知识。 在本节中,我们通过直接增强语言主干来探索另一种无参数方法。 由于我们的神经架构的编码器使用自注意力机制,我们提出了通过注意力权重操作进行特征注入。 在我们的情况下,BART(Lewis et al., 2020)的编码端包含了6个多头自注意力层,每个自注意力层有12个头,为了合并共指信息,我们选择了头并且修改他们用权重,表示共指信息。
4.3.1 注意力头检测和选择
为了尽可能多地保留语言主干提供的先验知识,我们首先进行探索任务以战略性地选择注意力头。因为不同的层和头传递不同的语义信息(Hewitt and Manning, 2019),我们的目标是找到头能够表示最多的共指信息。我们预测了注意力的头通过测量他们权重矩阵的cosine相似性,并用一个预先定义好的共指注意力矩阵。
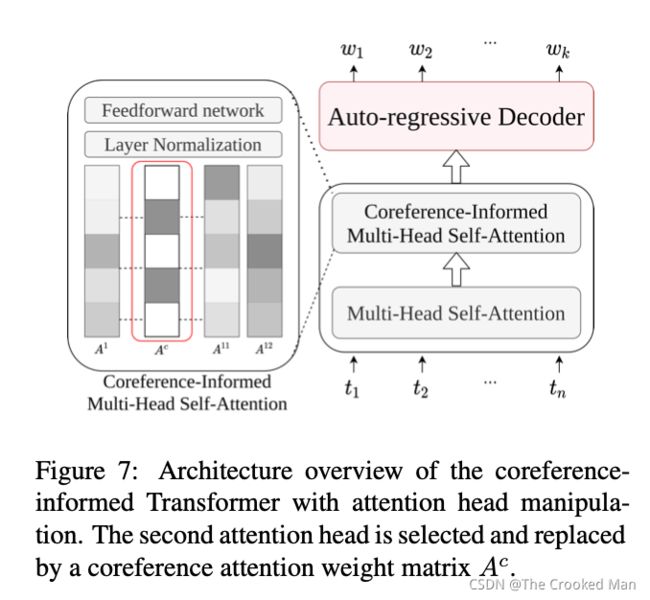
在所有测试记得样本中,我们得到了预测在所有的头上。我们观察到,在第五层,第七层的头获得了最高的相似度分数。在第六层,第五层的头获得了最高的相似性分数。
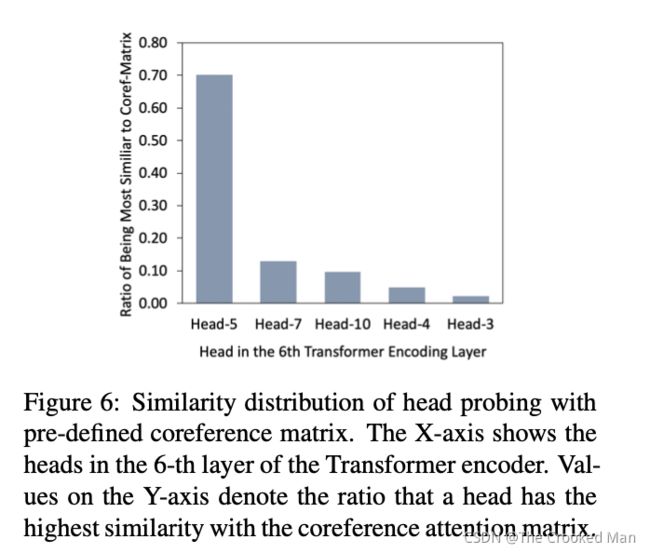
4.3.2 共指信息多头注意力机制
为了明确利用共指信息,我们用共指信息的注意力权重替换了两个主要的注意力头
2.Dialogue Discourse-Aware Graph Model and Data Augmentation for Meeting Summarization
设计了一个meeting graph 能够融合dialogue discourse信息,还加入了pseudo-summarization data
摘要
会议摘要的挑战:多说话人的动态交互,缺乏充足的训练数据。现有的研究方式把会议看作一个线性的语言序列却忽略掉了每句话之间的不同关系。此外,有限的标签数据严重阻碍了神经网络模型的能力。
这篇文章通过引入dialuge-discourse relations 来缓解这些问题。
首先提出了一个DDAMS模型,该模型建模了不同的对话关系来增强模型的表达能力。DDAMS的核心模组是一个关系图编码,该关系图编码用图交互的模式将utterance和discouse relations进行建模。
此外,改论文设计了一个DDADA策略去建立一个伪摘要预料对语现存的输入会议,比原数据集大了20倍,可以被用来预训练DDAMS。实验在AMI和ICSI会议数据集中展示了结果达到了sota,代码如下:https://github.com/xcfcode/DDAMS/
介绍
会议摘要可以让人快速的理解会议的记录内容[Gurevych and Strube, 2004],

Goo and Chen [2018]融合了utterance等级的对话动作去提升每一个utterance的表示能力 incorporate utterance-level dialogue acts to enhance the rep- resentation for each utterance.
Li et al. [2019]认为主题是一种结构信息可以丰富对话的表示。
然而,我们生成现在的研究面临两个问题。一个是sequential text modeling。一个回忆是一个动态的信息变化流,会议是一个动态的信息交换流,与传统文档[Sacks et al., 1978].相比,它是非正式的、冗长的、结构化的。但是之前的所有工作都采用顺序建模策略对会议进行编码,阻碍了对话语之间内在丰富的交互关系的探索,这使得会议建模不足。
另一个是缺少足够多的训练数据,据我们所致,语料库的规模对于训练神经网络模型有重大意义,会议摘要的数据尺寸是传统新闻摘要的千分之一。
为了解决上述问题,我们引用了dialogue discourse,一个专用于对话的结构,可以提供两句对话之间的预定义的关系。比如上图中的QA、Contrast和COntinuation,就是三种dialogue discourse relations,可以明确地表达信息流和utterance之间的交互关系。再知道这些关系后,我们就能产生更好的摘要。此外,我们发现一个问题经常会在会议中引发讨论。在图1中,关于design和cost的讨论在battery charger中很显著。因此,我们假设一个问题往往包含核心主题或关键概念,可以用作后续讨论的伪摘要。
在这篇文章中,提出了一个DDAMS对于建模对话的关系。特别的,我们首次转换会议对话用discouse relation成一个会议的图,这里话节点和关系节点交互。然后我们设计了一个graph-to-sequence结构去产生新的摘要。此外,为了解决不充足的数据问题,我们设计了一个DDADA(数据增强)策略,建立了一个伪摘要语料库从现有的输入会议中。详细上,我们是用了QA discourse relation去确认问题为假摘要,然后我们看了接下来的话用associated discouse relation作为假会议。最后,我们建立了一个假摘要语料库,比之前的大20倍。
我们把实验用于AMI [Carletta et al., 2005] and ICSI [Janin et al., 2003]数据集。这个结果表明DDAMS方法的有效性和DDADA的策略。总而言之,(1)我们第一个成功的探索了dialogue discouse去建模会议摘要的语言交互 (2)我们设计了一个 dialogue discourse aware数据增强策略去缓解数据稀疏的问题。(3)达到了SOTA
2.Preliminaries
2.1任务定义
U 为会议 Y为摘要
U包含了u个句子, Y包含了y个词
会议的第i个话剋被标示为一系列的词,ui = ui1,ui2,… uij表示第i个话的第j个词。
p表示说话人。
dialogue Discourse
Dialogue discourse表示discourse单元的关系。这个dependency-based结构,这种基于依赖的结构允许非相邻话语之间的关系,适用于多方对话[Li et al., 2021]. 有16种discourse relations[Asher et al., 2016] :comment, clarification- question, elaboration, acknowledgment, continuation, expla- nation, conditional, QA, alternation, question-elaboration, result, background, narration, correction, parallel, contrast。
3.Dialogue Discourse-Aware Meeting Summarizer
3.1Meeting Graph
给定会议预料,我们首先使用了一个SOTA dialogue discourse parser[Shi and Huang, 2019] 去得到discourse关系,一个关系从一个话语连接到另一个具有关系类型的话语。
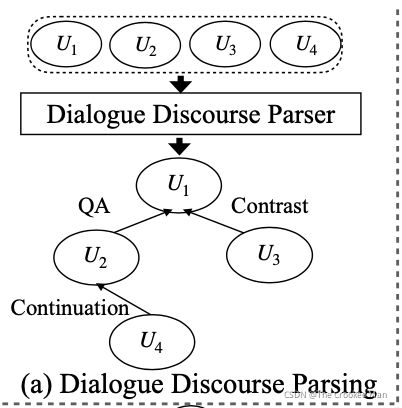
然后,我们使用了Levi图transformation,把标签边转化为额外的节点。[Gross et al., 2013].通过这样的转化,我们能够建模对话关系,同时更新utterance和discourse节点。有两种Levi图的关系边:default 和 reverse。
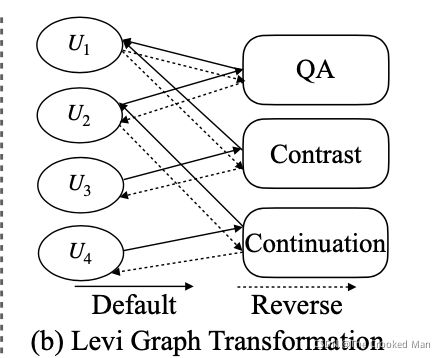
此外,为了融合非局部的信息,一个全局节点被添加到了,他链接了所有的节点通过全局边,也被用于初始化解码器。我们也添加了self边去聚合self-information
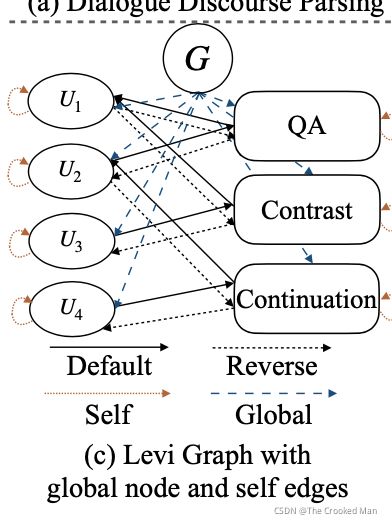
请注意,不同类型的顶点可能具有落在不同空间中的不同特征 [Beck et al., 2018]。过去的工作忽视了source资源和target节点,并且使用了相同类型的边来通过信息,这可能减少discourse information的有效性。因此,我们提出我们的会议图,把default边转化为default-in-discourse和default-out-discourse边,reverse边转化为reverse-in-discourse和reverse-out-discourse边。
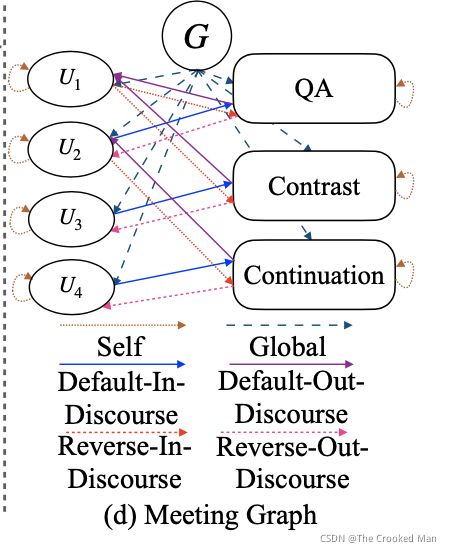
有六种不同的关系,default-in-discourse,default-out-discourse,reverse-in-discourse,reverse-out-discourse,global,self.
3.2顶点表示
顶点表示模组是为了获得三种类型节点的初始表示:global vertex, relation vertex 和utterance vertex.
对于global vertex, relation vertex从embedding table中查找。对于utterance vertices。我们使用了BiLSTM作为utterance编码器。[Qin et al., 2020]。为了加入说话人信息,我们用一个one-hot vector对说话人信息进行编码,并且通过连接word embedding和one-hot speaker embedding来得到ei,j.[Wang et al., 2020].作为最终的utterance信息表示
其中,ei,j表示词嵌入信息。
3.3Graph Encoder
在得到每个节点的初始特征后,我们把他们输入图的编码器去提取结构信息。我们使用了关系图神经网络[Schlichtkrull et al., 2018] 去捕捉高等级的隐藏特征,考虑到不同的边的类型。卷积计算的公式如下,
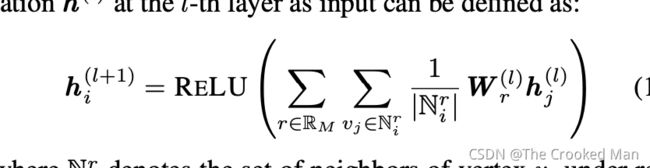
N表示v在条件r下的邻居集合,W是学习的参数。
然而,统一接受来自不同话语关系的信息并不适合识别重要话语。因此采用了门机制 [Marcheggiani and Titov, 2017] 来控制信息通过。
最后得到的卷积计算表示如下:
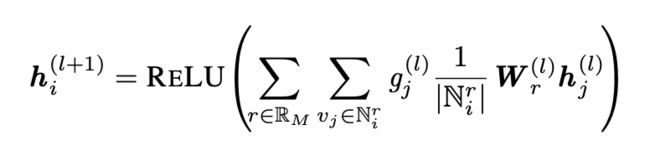
3.4 Pointer Decoder
我们使用了一个带有注意力机制和copy mechanism的标准LSTM解码器来产生摘要。全局的表示被用来初始化解码器在每一步,解码器收到了过去次的embedding和解码状态st,并计算注意力分布[Luong et al.,2015]. 我们同时考虑了word-level和utterance-level的attention。此等级的上下文向量通过如下方式计算:

以上是word-level向量的计算过程,utterance-level的计算过程与之相似。最终得到的上下文向量是word-level和utterance-level的向量拼接起来,然后被用来计算生成的概率和最后的概率分布[See et al., 2017].
3.5 Training Objective
我们使用最大似然函数来训练模型,给出ground truth对于输入的meeting。最小化目标词序列的negative log-likelihood
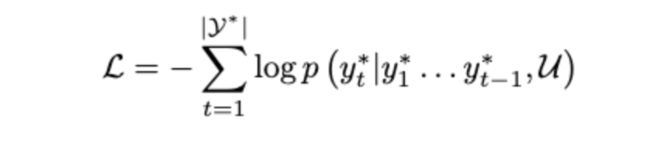
4 Dialogue Discourse-Aware Data Augmentation(IJCAI)

4.1假摘要语料库的构建
给定一个会议和他的相关discourse relations,我们发现一个“问题”通常可以引发一段讨论。
因此,我们可以将讨论的内容视为伪会议,将问题视为此次伪会议的伪摘要
QA 话语识别的问题作为伪摘要,问题后的 N 个话语及其相关的话语关系作为伪会议
请注意,有一些信息量不足且正常的问题,例如“what is this here这里是什么”,不适用于伪摘要语料库构建。 因此,我们过滤掉不包含名词和形容词的问题,使伪数据更加真实。
Multi-View Sequence-to-Sequence Models with Conversational Structure for Abstractive Dialogue Summarization
摘要
对话摘要没有像文档摘要那么受重视。这篇文章第一个建立了一个multi-view s2s模型通过从不同的视图中提取非结构化日常聊天的对话结构来表示对话,然后利用多视图解码器合并不同的视图来生成对话摘要。
介绍
对话摘要中包含 turns, informal words abbreviation emotion等信息,使文档摘要不可以直接应用于对话摘要中。
directly deploying existing document summarization models (Gliwa et al., 2019) and exploring multi-sentence compres- sion (Shang et al., 2018),然而大多数的他们还没有完全利用对话的结构。
一段对话包含有多个不同的视角,我们提出了组合这些multiple,分散对话的视角,为了生成更精确的摘要。
我们的主要工作是(1)提出了丰富对话结构,例如结构观点,以及普遍观点用于生成对话摘要。(2)我们设计了一个多视角的s2s模型,包含一个对话编码器去编码不同的观点和一个多视角解码器有不同的观点注意去产生对话摘要。
(3)在数据集上进行了验证
Dialogue Summarization When it comes to the summarization of dialogues, Shang et al. (2018) proposed a simple multi-sentence compression technique to summarize meetings. Zhao et al. (2019); Zhu et al. (2020b) introduced turn-based hierarchical models that encoded each turn of ut- terance first and then used the aggregated repre- sentation to generate summaries. A few studies have also paid attention to utilizing conversational analysis for generating dialogue summaries, such as leveraging dialogue acts (Goo and Chen, 2018), key point sequence (Liu et al., 2019a) or topics (Liu et al., 2019b; Li et al., 2019). However, they either needed a large amount of human annotation for dialogue acts, key points or visual focus (Goo and Chen, 2018; Liu et al., 2019a; Li et al., 2019), or only utilized topical information in conversations (Li et al., 2019; Liu et al., 2019b).
These prior work also largely ignored diverse conversational structures in dialogues, for instance, reply relations among participants (Mayfield et al., 2012; Zhu et al., 2019), dialogue acts (Ritter et al., 2010; Paul, 2012), and conversation stages (Al- thoff et al., 2016). Models that only utilized a fixed topic view of the conversation (Galley et al., 2003; Joty et al., 2010) may fail to capture its comprehen- sive and nuanced conversational structures, and any amount of information loss introduced by the con- versation encoder may lead to larger error cascade in the decoding stage. To fill these gaps, we pro- pose to leverage diverse conversational structures
including topic segments, conversational stages, di- alogue overview, and utterances to design a multi- view model for dialogue summarization.
method
对话可以从不同的视图进行解释,每个视图都使模型能够关注对话的特定方面。
3.1conversation view 提取(数据处理部分)
对话摘要模型可能很容易在各种说话者和话语的各种信息中出现偏差,尤其是当对话变得很长时。 自然地,如果可以从长对话中显式提取小块形式的信息结构,模型可能能够以更有条理的方式更好地理解它们。 因此,我们首先从对话中提取不同的结构视图。
Topic View
对话它们大多以粗粒度结构围绕主题进行组织,例如,一个电话闲聊可以由这样的方式组成:greetings invitation arty details rejection从主题角度。这样详细的视觉和对话流能够帮助模型解释对话更加精确,并且产生摘要覆盖重要的主题。下面我们组合经典的主题片段算法,C99(Choi, 2000),片段对话基于内部句子的相似度,用BERT提取出对话主题。特别的是在每一个C中的话首先被编码成隐响亮,然后对话C被分为多个块,通过C99,,每一个块包含了不同的连续话语。
Stage View
通过HMM,给状态设置一个固定的顺序,并且只让当前的状态传递到下一个状态。HMM中的观察状态由BERT来编码,最后提取出了每一个state中最常用的几个状态。
Global View and Discrete View
全局信息把所有的话集中在一个大的block中,discrete view把每一个话分散成了一个不同的block
3.2Multi-view Sequence-to-Sequence Model(模型部分)
conversation Encoder
一个viewk分为n个block,每个字符属于一个block。然后进行编码
Multi-view decoder
战略性地结合不同观点的能力至关重要。 为此,我们提出了一种基于transformer的多视图解码器来集成来自不同视图的编码表示并生成如图 1 所示的摘要。
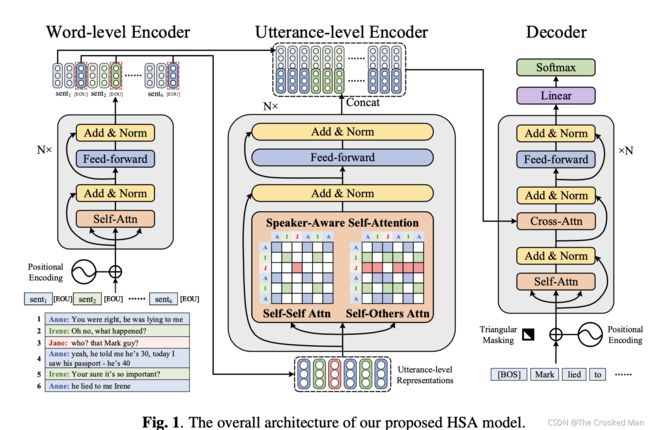
HIERARCHICAL SPEAKER-AWARE SEQUENCE-TO-SEQUENCE MODEL FOR DIALOGUE SUMMARIZATION
将每一句话开头的人名作为说话人的标签,将其编码至模型中。HSA(所提到的模型)用层级方法将语言从token-level到utterance-level,然后HSA再经过一个Speaker-Aware Self-attention获得一个speaker-level的表示。
摘要
对话摘要中包含多个说话人和复杂的人称代词。被预测的摘要总是包含人称代词的困惑。在这篇文章中,提出了一个用于对话摘要的层级transformer的模型。它编码的对话从词语到句子,并且区分了说话人和他们相关的代词。
MODEL
作者观察到了,每一句话的开头都有人名,为了更好的利用这些名字,解决人称代词的问题,而提出了一个SASA(Speaker-Aware Self-attention)模型,加强utterance-level的表达。特别的是,SASA包含了两个模组,SSA和SOA(self-self attention 和 self-others attention)
Hierachical Encoder
对于一个多轮对话中,有m个句子U,每个U有n个单词。编码一句话中的每个词用一个word-level的编码器,然后编码每个句子用utterance-level的编码器
word-level Encoder
用一个可训练的矩阵表示单词,第j句话的第i个词为eij
然后用一个6层的transformer编码器来编码
用一个特殊的标记被添加到每句话的末尾
根据多轮和说话人缠绕的对话特征,输入的文字可以被轻松地分成许多话,对我们的word-level编码器,去独立的表示每句话。(就是输入的word-level经过WE可以变成utterance-level的初始值)
Utterance-level Encoder
utterance-level编码器建模所有m轮谈话的内容。为了得到每个第j轮说话的表示,我们用了每个utterance的最后一个符号的word-level表示,即,并且把她们通过这个utterance-level encoder进行编码。
SSA
模型不能理解说话人的名字和人称代词的关系,如 A:…,因此这样做简单的拼接起来输入没有什么用。为了帮助模型理解理解A和后面句子的关系,SSA创建了一个特殊的MASKssa,根据说话人的名字A\B。对每一句话,SSA都创建了一个mask。
最后得到了:
![]()
最后的idn 就是说话人A或B
mask序列被用来创建一个矩阵,到注意力机制中。

SOA
和刚才那个差不多。文中也没有写清楚是怎么得来的。

最后将两个公式融合在一起,得到最终结果。
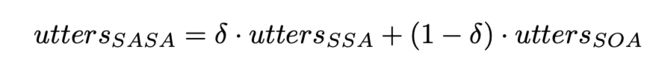
其中,delta是手动确定的。
最后将word-level和utterance-level组合在一起
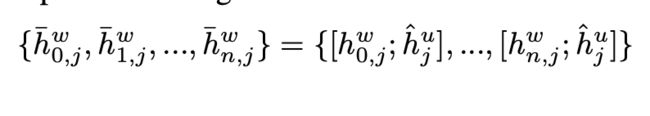
图画的挺好的
最后通过了一个普通的解码器

Incorporating Commonsense Knowledge into Abstractive Dialogue Summarization via Heterogeneous Graph Networks
融入了常识知识、把speakers也当做了heterogeneous节点,用HGN来建模。
摘要
提出了一个multi-speaker dialogue summarization,解释大规模的常识知识如何使对话更容易理解、摘要更容易产生。在细节上,认为utterance和常识是两种不同类型的数据,设计一个Dialogue Heterogeneous Graph Network用来建模两类知识。与此同时,我们也可以添加说话人作为heterogeneous节点,使信息流更加丰富。实验室围绕着SAMSum数据集展开的,并且进行了零样本实验在Argumentative Dialogue Summary Corpus。
Introduction
Recent works that incorporate additional commonsense knowledge in the dialogue generation (Zhou et al., 2018) and dialogue context representation learning (Wang et al., 2020) show that even though neural models have strong learning capabilities, explicit knowledge can still improve response generation quality.近期的工作证明了常识融入模型的有效性。这是因为对话系统如果能够访问和充分利用大规模的常识知识,就可以更好地理解对话,从而更正确地做出反应。
However, current dialogue summarization systems (Ganesh and Dingliwal, 2019; Li et al., 2019; Liu et al., 2019a; Zhu et al., 2020) ignore the exploration of commonsense knowledge, which may limit the performance.然而近期的摘要模型却忽视了常识性知识的重要性。

粉色的即是常识部分。常识知识可以当作一个桥梁连接两个不相邻的话。
本文引入的常识知识库为:previous setting (Zhou et al., 2018) and also use ConceptNet (Speer and Havasi, 2012) as a large-scale commonsense knowledge base。我们把知识和utterance看作一个真实多人对话中的heterogeneous 数据。我们建立了一个DHGN,包含utterance和knowledge nodes以及说话人节点(被证明是有用的)。
为了融合这些知识,我们建立了两个模型:
一个是 message fusion,专门为utterance node话语节点设计,以更好地聚合来自说话者speaker和知识knowledge的信息。
另一个是node embedding,能够帮助utterance nodes理解position information。
Compared to homogeneous graph network in related works (Ganesh and Dingliwal, 2019; Li et al., 2019; Liu et al., 2019a; Zhu et al., 2020), we claim that the heterogeneous graph network can effectively fuse information and contain rich semantics in nodes and links, and thus more accurately encode the dialogue representation.和HGN的相关工作相比,我们生成该网络可以有效的融合信息,使节点和连接包含了更丰富的语义,并且因此更有效的对对话进行编码。
本文的贡献:
- We are the first to incorporate commonsense knowledge into dialogue summa- rization task. (2) We propose a D-HGN model to encode the dialogue by viewing utterances, knowledge and speakers as heterogeneous data. (3) Our model can outperform various methods第一个融合常识信息到对话系统,提出了D-HGN模型。
HDG的建立
图表示和图建立过程,包括三个部分:
(1) utterance-knowledge bipartite graph construction.
utterance knowledge双方图建立
(2)speaker-utterance bipartite graph construction
speaker utterance双方图建立
(3)heterogeneous dialogue graph construction.
heterogeneous dialogue图建立
Graph Notation
Utterance-Knowledge Bipartite Graph Construction
目前的对话摘要语料库没有知识表示。将每个对话都以常识为基础,我们利用了ConceptNet (Speer and Havasi, 2012) 去合并知识。ConceptNet是一个语义网络,包含了34种关系以及每一个知识三元组表示:h表示头实体 t表示尾实体 r表示有权重的关系。它包含了不仅仅是真实世界的信息,例如巴黎是法国的首都,以及属于日常知识一部分的非正式关系,例如“电话用于联系”。
我们使用对话中的每个词用做查询去检索一个one-hop的网络。Guan et al. (2018)
我们只考虑名词、动词、形容词、副词。我们过滤掉了如下三元组:r 位于无用关系的预定义列表中。例如 “number” is antonym of “letter”“数”是“信”的反义词。r的权重小于1:“文本”与“重构”相关。最终我们得到了对话中的关系概念。
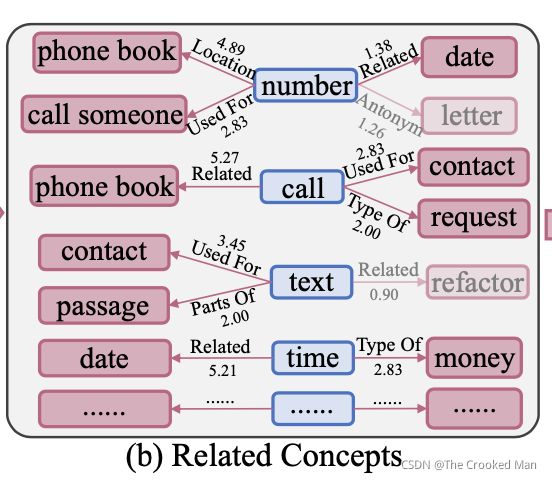
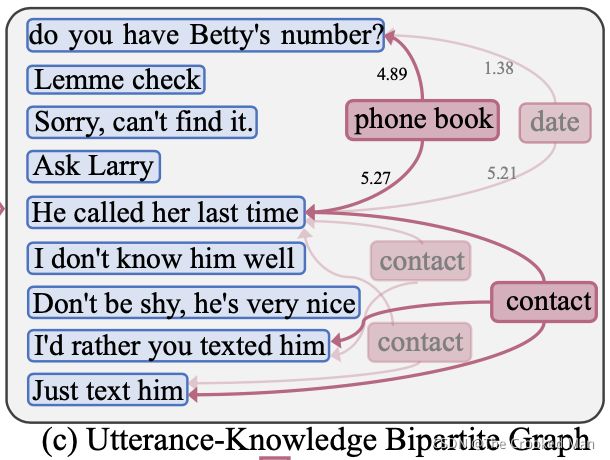
如果两个话语都具有相同的尾部概念 t,则我们使用边缘知识将两个话语连接到一个尾部概念 t。 请注意,两个话语可能连接到多个尾概念,我们选择关系平均权重最高的一个。如果有多个相同的知识节点,我们也将它们合并为一个(两个contact,合并成为一个)
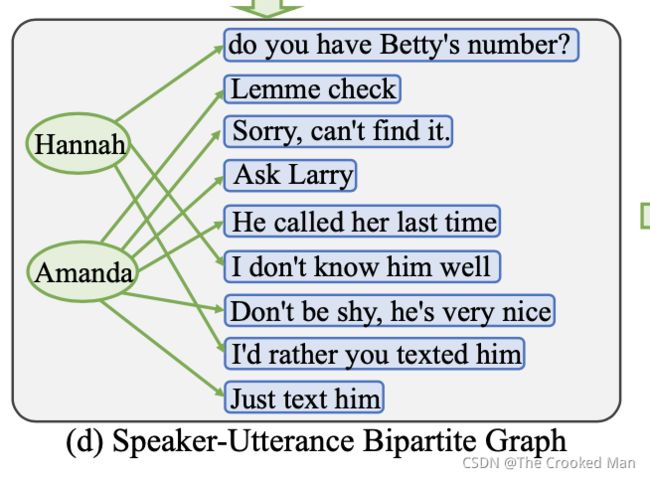
Speaker-Utterance Bipartite Graph Construction
给定对话中的多个说话者和相应的话语,我们通过将说话者和话语视为不同类型的节点来构建说话者-话语图。
Heterogeneous Dialogue Graph Construction
我们将话语-知识二分图和说话者-话语二分图结合起来作为我们的异构对话图
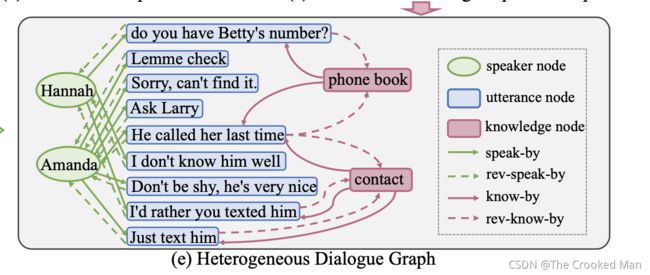
Dialogue Heterogeneous Graph Network
Node Encoder
节点编码器的作用:给每一个节点一个初始表示,节点是由词所组成的。注意:说话人和知识可能有多个词。我们将Bi-LSTM作为节点编码器:
(1)输入节点通过前向和后向的方式得到了两个隐状态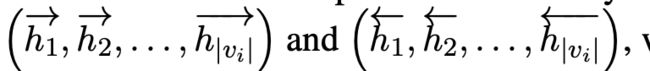
其中,h n为每一个词的embedding x和前一个隐状态h n-1经过LSTM形成的。
前向和后向的隐状态串联起来,作为初始节点表示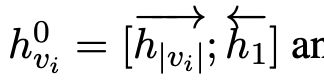
初始词表示
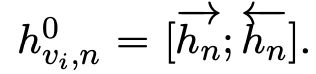
随后经过多重训练得到最终的表示结果。
graph encoder
图编码器被用来摘要结构信息,并且更新节点表示。我们使用HGTransformer(Hu et al., 2020)作为我们的图编码器,通过依赖于类型的参数对异质性建模,并且可以很容易地应用于我们的图中。包括:heterogeneous交互注意力,计算了原节点和目标节点的注意力分数。heterogeneous信息传递,将信息向量Msg用来给每一个原节点,target-specific aggregation,融合了aggregates messages从源节点到目标节点,使用attention scores作为权重。
特别的,我们设计了两个模组,名字叫做message fusion 和node embedding让学习更有效。
Heterogeneous Mutual Attention
Heterogeneous Message Passing
Target-Specific Aggregation
Message Fusion
Node Embedding
Pointer Decoder
使用了类似指针生成网络的方式产生摘要。每一个解码器的步种,LSTM读去了过去的词向量和上下文向量作为输入去计算隐状态。
实例

可以看到,其他两种方法都存在输入单词错误的情况,而D-HGN没有,更接近于Golden
Multi-View Sequence-to-Sequence Models with Conversational Structure for Abstractive Dialogue Summarization
摘要
这项工作提出了一种多视图序列到序列模型,首先从不同视图中提取非结构化日常聊天的对话结构来表示对话,然后利用多视图解码器合并不同的视图来生成 对话摘要。
Introduction
直接把document summarization应用于dialogue summarization中 (Gliwa et al., 2019)
探索多句子压缩(Shang et al., 2018)
然而这些研究没有考虑到对话的结构。推断出utterances被阻止为了让对话有意思。在对话中,一个关键因素是把对话和结构文档进行区分。对话有着自己组织句子的方式。尽管有一些例外:topic segmentation (Liu et al., 2019b; Li et al., 2019), dialogue acts (Goo and Chen, 2018) or key point sequence (Liu et al., 2019a),
他们也需要扩展对话动作的研究(Goo and Chen, 2018; Liu et al., 2019a),
或者只编码对话基于他们的主题(Liu et al., 2019b),没有成功地捕捉对话中丰富的结构信息。
一个单独的对话可以被看作不同的方面,导致多对话或discourse patterns.
基于对话的主题(topic view),可以被分为:greetings, today’s plan, plan for tomorrow, plan for Saturday and pick up time (Galley et al., 2003; Liu et al., 2019b; Li et al., 2019)
从对话进程角度(stage view)相同的对话可以被分为openings intention discussion 和 conclusion
从粗略的角度(全局视图),可以将对话视为一个整体,也可以将每个话语视为一个片段(离散视图)。
仅利用对话的固定主题视图的模型(Joty 等人,2010 年;Liu 等人,2019b)可能无法捕捉其全面和细微的对话结构,并且对话编码器引入的任何数量的信息丢失都可能导致 在解码阶段有更大的错误级联。
为了填补这些空白,我们建议将这些多种不同的对话观点结合起来,以生成更精确的摘要。
总结:
(1)提出了一个利用丰富对话结构信息的,例如观点结构(topic view and stage view)和普遍结构(global view and discrete view)
(2)我们设计了一个多视角s2s模型,包含了一个对话编码器来编码不同的视角,和一个多视角解码器用multi-view attention去生成对话摘要。
(3)在SAMSum上做实验
(4)我们进行彻底的错误分析并讨论当前方法在此任务中面临的具体挑战。
Related Work
Document Summarization
Rush et al. (2015) introduced to use sequence-to-sequence models for abstractive text summarization.
See et al. (2017) proposed a pointer-generator network to allow copying words from the source text to handle the OOV issue and avoid generating repeated content.
Paulus et al. (2018); Chen and Bansal (2018) further utilized reinforcement learning to select the correct content needed by summarization.
Large-scale pre-trained language models (Liu and Lapata, 2019; Raffel et al., 2019; Lewis et al., 2019) have also been intro- duced to further improve the summarization perfor- mance.
Other line of work explored long-document summarization by utilizing discourse structures in text (Cohan et al., 2018)
introducing hierarchical models (Fabbri et al., 2019) or modifying atten- tion mechanisms (Beltagy et al., 2020).
There are also recent studies looking at the faithfulness in document summarization (Cao et al., 2018; Zhu et al., 2020a), in order to enhance the information consistency between summaries and the input.
Dialogue Summarization
Shang et al. (2018) proposed a simple multi-sentence compression technique to summarize meetings.
Zhao et al. (2019); Zhu et al. (2020b) introduced turn-based hierarchical models that encoded each turn of ut- terance first and then used the aggregated repre- sentation to generate summaries.
A few studies have also paid attention to utilizing conversational analysis for generating dialogue summaries, such as leveraging dialogue acts (Goo and Chen, 2018), key point sequence (Liu et al., 2019a) or topics (Liu et al., 2019b; Li et al., 2019).
they either needed a large amount of human annotation for dialogue acts, key points or visual focus (Goo and Chen, 2018; Liu et al., 2019a; Li et al., 2019)
only utilized topical information in conversations (Li et al., 2019; Liu et al., 2019b)
reply relations among participants (Mayfield et al., 2012; Zhu et al., 2019), dialogue acts (Ritter et al., 2010; Paul, 2012), and conversation stages (Al- thoff et al., 2016).
仅利用对话的固定主题视图的模型(Galley 等人,2003 年;Joty 等人,2010 年)可能无法捕捉到其全面和细微的对话结构,以及由习惯性引入的任何数量的信息丢失。 版本编码器可能会在解码阶段导致更大的错误级联。
为了填补这些空白,我们建议利用不同的对话结构,包括主题段、对话阶段、对话概述和话语来设计用于对话摘要的多视图模型。
对话可以从不同的视图进行解释,每个视图都使模型能够关注对话的特定方面。为了利用这些丰富的对话视图,我们设计了一个多视图序列到序列模型(见图 1),首先提取对话的不同视图(第 3.1 节),然后对它们进行编码以生成摘要(第 3.2 节)。
对话摘要模型可能很容易在各种说话者和话语的各种信息中出现偏差,尤其是当对话变得很长时。 自然地,如果可以从长对话中显式提取小块形式的信息结构,模型可能能够以更有条理的方式更好地理解它们。 因此,我们首先从对话中提取不同的结构视图。
Topic View 例如,一个电话交流可以有如下的状态:greetings/invitation/party details/rejection
基于句子内部的相似性,用BERT。
每一个句子首先用BERT编码,通过C99模型把对话C分为不同的模块,b是一个block包含多个连续的话,然后提取出topic view。b是语义块。
Stage View
对话被分为这样的情况:introductions/problem exploration/problem solving/wrap up
这种对话阶段视图提供了关于对话中不同部分的功能或目标的高级草图,这可以帮助模型专注于具有关键信息的阶段。
我们遵从HMM去提取阶段。我们对阶段施加了固定的顺序,并且只允许从当前阶段过渡到下一个阶段。我们定性地解释推断的阶段,并进一步可视化表 2 中每个阶段出现的前 6 个频繁词。
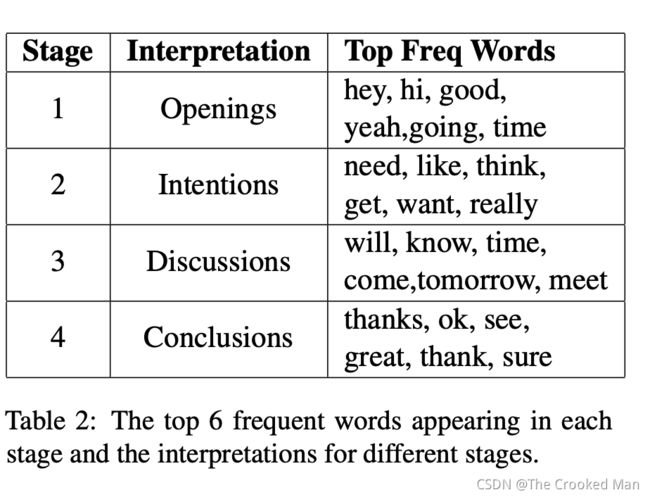
Global View and Discrete View
除了上述两种结构化视图之外,还可以从相对粗略的角度自然地查看对话,即一种将所有话语串联成一个巨大块的全局视图(Gliwa et al., 2019 ),以及将每个话语分成不同块的离散视图(Liu 和 Chen,2019 年;Gliwa 等人,2019 年)。
Conversation Encoder
对每一块b,用BART进行编码
Multi-view Decoder
不同的观点可以为模型学习提供不同类型的对话方面,并进一步确定哪组话语应该得到更多关注,以生成更好的对话摘要。因此,战略性地结合不同观点的能力至关重要。 为此,我们提出了一种基于变换器的多视图解码器,以集成来自不同视图的编码表示并生成如图 1(b) 所示的摘要。
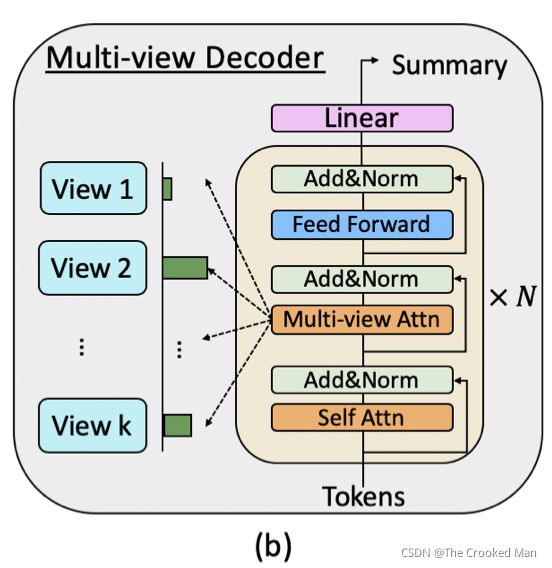
我们提出了一种基于变换器的多视图解码器来集成来自不同视图的编码表示并生成摘要。


Improving Abstractive Dialogue Summarization with Graph Structures and Topic Words
提取结构信息
摘要
在本文中,我们提出了一个主题词引导对话图注意(TGDGA)网络,根据主题词信息将对话建模为交互图。
掩码图自注意力机制用于集成跨句信息流,并更多地关注相关话语,从而更好地理解对话。 此外,还引入了主题词特征来辅助解码过程。
Introduction
虽然抽象对话摘要任务取得了一些进展,但以前的方法没有为对话开发专门设计的解决方案,并且都依赖于序列到序列模型,无法处理句子级的长距离依赖并捕获 跨句关系。
为了缓解这些问题,一种直观的方法是使用图结构对句子的关系进行建模,这可以打破对话的顺序位置并直接连接相关的长距离话语。
在本文中,我们提出了一个 Topic-word Guided Dialogue Graph Attention (TGDGA) 网络,该网络通过图神经网络发现句内和句间关系,并根据图到序列框架和主题词生成摘要。
不同粒度级别的节点分别表示主题词特征和话语序列特征。 图中的边由节点之间的语言信息关系初始化。图自注意力层中操作的掩码机制仅利用相关话语并过滤掉冗余话语。 对话图聚合了有用的对话历史并有效地捕获了跨句关系。此外,我们将主题词编码为主题信息表示并将其集成到解码器中,以指导生成过程。
这篇文章的主要工作如下:
1、我们是第一个将整个对话构建为抽象对话摘要图的人。 适当的图结构允许更容易地分析对话中的各种关键信息并分离可用的话语。 图神经网络避免了长距离依赖的问题,可以提取跨句关系,使得对话的信息流更加清晰。
2.我们设计了一个主题词引导的图到序列网络,以端到端的方式生成对话摘要。 通过图注意力机制、覆盖机制和指针机制利用主题词信息,使摘要更加集中,关键元素。 实验表明,在没有预训练语言模型的情况下,我们的模型在两个基准数据集上的表现优于所有基线。
Methodology
(1)Dialogue Graph Construction
(2)Graph Encoder
(3)Sequential Context Encoder
(4)Topic-word Guided Decoder
Dialogue Graph Construction
Node initialization
引用了LDA model (Hoffman et al., 2010)主题建模。引用了Gibbs sampling al- gorithm (Zhao et al., 2011)
此外,在对话历史中被提到的说话人的名字也被添加到了topic word的序列里。
我们用了CNN(不同大小的卷积核)去捕捉每句话的局部特征表示
为了更新utterance表示节点,我们引入了一个共向图注意力机制shared graph attention mechanism (Velicˇkovic ́ et al., 2018)可以特征花上下文关联性的强弱(utterance和他们相邻的主题之间)。
此外,它还可以减少不恰当的话题词的反响,强调与话语相关的话题。
Edge initialization
如果我们假设每个话语节点在上下文中都依赖于对话中的所有其他节点,那么将构建一个完全连接的图。 然而,这会导致大量的计算。 因此,我们采用一种策略来构建图的边,根据主题词信息关联对话的话语。如果节点i和节点j分享至少一个主题词,eij = 1
Graph Encoder
在我们得到带有话语节点特征 x 和边集 E 的构造图 G 后,我们将它们输入到图编码器中以表示对话。
Graph Encoder包括两层结构:masked graph self-attention layer和feed forward layer
Masked graph self-attention layer:
对话历史的不同部分具有不同的重要性级别,可能会影响摘要生成过程。 我们选择使用掩蔽注意力机制来更多地关注显着的话语。一般的自注意力操作捕获单个序列的两个任意位置之间的交互 (Vaswani et al., 2017).
然而,我们的masked self-attention operation只计算了途中两个相邻节点的相似性关系,掩盖住不相关的边。相似关系被认为是模型可以以端到端的方式学习的边权重。
经过这一层,和feed forward layer之后,得到输出。
Sequential Context Encoder
由于对话本质上是顺序的,因此部分上下文信息也将沿着顺序流动。
符号是一个接一个的输入到LSTM单元中的,产生一个序列的编码器隐状态h
最终,我们把图编码器最后一层的表示和最后一个状态序列上下文编码器的状态表示拼接在一起,作为解码器的初始状态。
Topic-word Guided Decoder
大多数编码器-解码器模型仅使用源文本作为输入,这导致生成的摘要中缺少主题词信息。 我们提出了一种主题词引导解码器,从两个方面增强主题词信息:the coverage mechanism and pointer mechanism
具体来说,我们将对话的所有主题词节点表示的均值池化作为主题信息表示,来表示解码阶段的先验知识。
coverage mechanism:
重复是生成任务中的一个常见问题,特别是说话人的名字和重要动作。传统的coverage mechanism很难分别主题词信息,仅仅包括了解码器的状态和编码器的隐状态。这里重新设置了注意力机制
Pointer mechanism:
由于固定词汇表的限制,一些主题词信息也许在摘要中被丢失。因此,我们修改了指针机制可以扩展词汇表到包含主题的词。得到了产生概率。
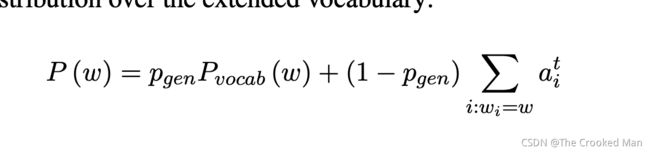
IMPROVING ABSTRACTIVE DIALOGUE SUMMARIZATION WITH CONVERSATIONAL STRUCTURE AND FACTUAL KNOWLEDGE(还在盲审中)
摘要
至少两个对话者之间对话交换的信息流,这导致捕获长距离交叉句子关系的必要性。此外,生成的摘要通常会受到虚假事实的影响,因为对话的关键元素通常分散在多个话语中。 然而,现有的序列到序列模型很难解决这些问题。 因此,有必要探索隐含的对话结构,以确保生成内容的丰富性和真实性。
在这篇文章中,提出了一个知识图谱提升Dual-Copy网络 KGEDC,一个引入了对话结构和虚假知识的对话摘要。我们使用序列编码器绘制局部特征,使用图编码器通过稀疏关系图自注意力网络集成全局特征,相互补充。此外,在解码过程中还设计了双重复制机制,以强制生成以源文本和提取的事实知识为条件的生成。
Methodology
我们的模型包含了四个模组:
(1)sequence encoder
(2)graph encoder
(3)factual knowledge graph
(4)dual-copy decoder
即,缺少了之前处理别的知识的部分。
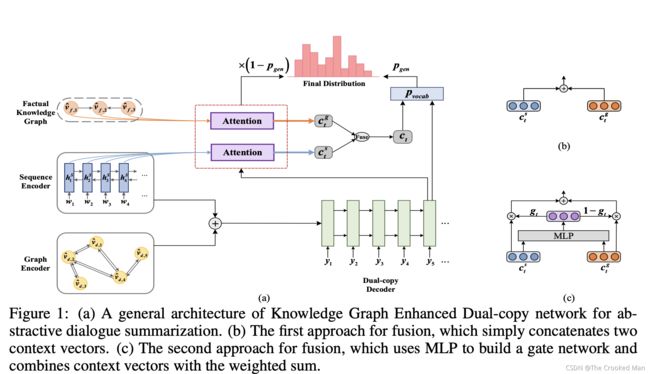
3.1 SEQUENCE ENCODER(和上一篇论文的一样)
考虑到对话的上下文信息通常沿着序列流淌,输入文本的序列方面也具有丰富的意义。把对话D看作一个例子,我们把符号一个挨着一个的送入BiLSTM。
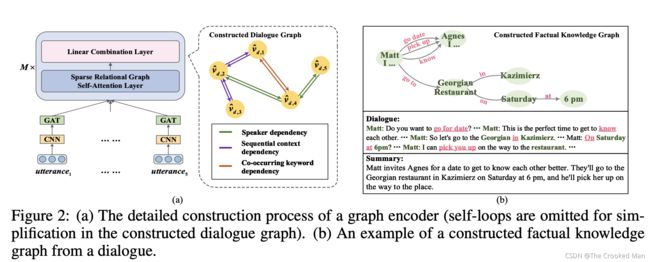
Graph Encoder
eji表明有一个边在第i句话和第j句话。我们然后使用图神经网络更新所有话的表示去捕捉长距离交叉句子的依赖关系。
3.2.1 节点初始化
我们用不同大小的卷积核去获取utterance。然后对对话做pos tagging,用off-the-shelf工具,例如Stanford CoreNLP (Manning et al., 2014) ,并且选择名次、数字、形容词、副词和符号动词作为关键词。每一个关键词被转换成真实值向量表示,通过查找词表矩阵(也是一个随机初始化过程)。然后设计注意力机制来表征话语和关键字之间的上下文相关性的强度。
3.2.2边初始化
如果我们假设每个话语在上下文中都依赖于对话中的所有其他话语,那么将构建一个完全连接的图。 然而,这会导致大量的计算。 因此,我们采用一种策略来构建图的边,该策略依赖于话语之间的各种语义关系。 我们定义了三种类型的边缘标签:说话者依赖、顺序上下文依赖、共现关键字依赖
说话人依赖:如果两句话属于同一个说话人,我们将给他们设置一条边
顺序上下文依赖:该关系描述了在固定大小的滑动窗口内发生的顺序话语。在这个场景中,每一个说话的节点有一个边和过去p个时刻的说话节点,f个未来时刻的说话节点。
共现关键字依赖:这个关系意味着所有的话包含相同的关键词被连接。
3.2.3迭代操作
为了模块化架构设计,多个块都由稀疏关系图自注意力层和线性组合层组成,堆叠在一起以捕获序列编码器遗漏的长距离依赖关系,以便更好地总结。
Sparse Relational Graph Self-Attention Layer
Linear Combination Layer
3.3FACTUAL KNOWLEDGE GRAPH CONSTRUCTION
为了建立真实知识图谱,我们利用了开源信息抽取器(OpenIE)去获得关系三元组。要注意的是:关系三元组不总是可以提取的。我们进一步采用依赖解析器dependency parser,从句子的解析树中挖掘出一些二元元组来补充事实描述。给定一个知识图谱G,节点V表示主题和目标三元组,E表示他们之间的关系。我们然后获得mention通过 coreference resolution tool and collapse 同一实体的共指提及合并到一个节点中。节点表示被使用
sparse relational graph self-attention network 更新。
3.4DUAL-COPY DECODER
解码器由LSTM和Pointer network合并成的。为了获得高faithfulness的摘要,我们也设计了一个dual copy mechanism去集中在输入符号和真实知识上。在解码的每一步,我们计算了序列上下文向量用注意力机制。


ABSTRACTIVE DIALOG SUMMARIZATION WITH SEMANTIC SCAFFOLDS
seq2seq : Pointer-Generator
hierachical transformer
改进了Pointer-Generator
摘要
propose an abstractive dialog summarization dataset based on MultiWOZ提出了一个新的数据集。
诸如餐厅名称之类的信息实体很难保留,并且来自不同对话域的内容有时会不匹配。
为了解决这两个缺点,我们提出了Scaffold Pointer Network网络(SPNet)来利用现有的关于说话者角色、语义槽和对话域的注释.SPNet 将这些语义支架合并到对话摘要中。此外,本文还提出了一个新的评价矩阵,考虑到了文本中所含有的主要信息实体。
Introduction
提取方法从对话中合并选定的重要话语以形成摘要。 由于对话高度依赖于它们的历史,因此很难用一组非连续的对话轮次产生连贯的话语。 因此,抽取式摘要并不是总结对话的最佳方法。
然而,由于缺乏对话摘要语料库,大多数现代抽象方法专注于单人文档而不是对话。
Popular abstractive summarization dataset like CNN/Daily Mail (Hermann et al., 2015) is on news documents. AMI meeting corpus (McCowan et al., 2005) is the common benchmark, but it only has extractive summary.
将新闻摘要应用在对话中会有两个缺点:地名等信息实体难以准确捕捉,不同领域的内容汇总不均。为了解决这些问题,我们提出了SPNet网络,SPNet融合了三种语义scaffolds:speaker role 、semantic slot和dialog domain。
首先,SPNet使单独的编码器适应注意力 Seq2Seq 框架,为不同的说话者角色产生不同的语义表示。 然后,我们的方法输入去词法化的话语以产生去词法化的摘要,并填充槽值以生成完整的摘要。 最后,我们通过联合优化对话域分类任务和摘要任务来合并对话域支架。
起初,SPNet 使单独的编码器适应注意力 Seq2Seq 框架,为不同的说话者角色产生不同的语义表示。 然后,我们的方法输入 delexicalized utterances 以产生 delexicalized summary,并填充 slot 值以生成完整的摘要
最后,我们通过联合优化对话域分类任务和摘要任务来合并对话域支架。
Related Work
Rush et al. (2015) first applied modern neural models to abstractive summarization. Their approach is based on Seq2Seq framework (Sutskever et al., 2014) and attention mechanism (Bahdanau et al., 2015), achieving state-of-the-art results on Gigaword and DUC-2004 dataset. 第一个将神经网络模型用于生成式摘要
Gu et al. (2016) pro- posed copy mechanism in summarization, demonstrating its effectiveness by combining the advan- tages of extractive and abstractive approach.
提出了复制机制在摘要中,表明了合并提取和生成摘要的有效性
See et al. (2017) applied pointing (Vinyals et al., 2015) as copy mechanism and use coverage mechanism (Tu et al., 2016) to discourage repetition.
把指针应用在了复制机制中,并且使用coverage mechanism去消除重复
Most recently, reinforcement learning (RL) has been employed in abstractive summarization. RL-based approaches directly optimize the objectives of summarization (Ranzato et al., 2016; Celikyilmaz et al., 2018). However, deep reinforcement learning approaches are difficult to train and more prone to exposure bias (Bahdanau et al., 2017).强化学习应用在摘要中,体现出了一定的错误。
BERT (Devlin et al., 2018) and GPT (Radford et al., 2018) have achieved state-of-the-art performance in many tasks, including sum- marization.
For instance, Zhang et al. (2019) proposed a method to pre-train hierarchical document encoder for extractive summarization. 提出了预训练分层文档编码器用于抽取式摘要
Hoang et al. (2019) proposed two strategies to incorporate a pre-trained model (GPT) to perform the abstractive summarizer and achieved a better performance.提出了两种策略合并GPT去表示生成式摘要
然而,还没有研究表明应用与训练模型到对话摘要的作用
对话摘要:
Galley (2006) used skip-chain conditional random fields (CRFs) as a rank- ing method in extractive meeting summarization.
Wang & Cardie (2013) compared support vector machines (SVMs) (Cortes & Vapnik, 1995) with LDA-based topic models (Blei et al., 2003) for producing decision summaries. 支持向量机和LDA主题建模
然而,由于缺乏合适的基准,抽象对话摘要的探索较少。
Recent work (Wang & Cardie, 2016; Goo & Chen, 2018; Pan et al., 2018) created abstractive dialog summary benchmarks with existing dialog corpus. Goo & Chen (2018) annotated topic descriptions in AMI meeting corpus as the summary.
创建了生成式对话摘要benchmarks用现存的语料库。以及主题标注信息在AMI会议语录中。
但是,他们定义的主题很粗略,例如“工业设计师演示”。 他们还提出了一个具有句子门控机制的模型,该模型结合了对话行为来执行抽象摘要。
Li et al. (2019)首先建立了一个模型,用抽象的方法总结视听会议数据。然而,之前的工作并没有研究对话中语义模式的利用,因此我们在我们的工作中对其进行了深入探索。
Proposed Method
这篇文章集于Pointer-Generator (See et al., 2017)提出了Scaffold Pointer Network.
SPNet结合了三种类型的语义支架来改进抽象对话摘要:说话者角色、语义槽和对话域。
3.1 BACKGROUND(介绍了s2s模型和PG)
Pointer-Generator是一种Seq2seq attention模型和pointer network融合而成的。
seq2seq框架编码了源序列,并且用decoder产生了目标序列。
decoder产生一个分布来决定这一步的目标元素。在P-G中,注意力分布可以被按照如下方式计算Bahdanau
最后使用注意力机制和上下文信息得到了上下文的向量。
Pointer-Generator和seq2seq attention的区别在于产生过程。Pointing mechanism指向机制将直接从源文本复制单词与从固定词汇表生成单词相结合。计算出产生的可能性需要用到这个模型的输出。
从复制和生成中进行选择的能力对应于动态词汇表。指针网络为复制的标记形成扩展词汇表,包括源文本中出现的所有词汇外(OOV)词。
3.2 SCAFFOLD POINTER NETWORK (SPNET)
SPN是基于PG所提出的模型。SPNet的贡献有三种:不同角色的单独编码,结合语义槽脚手架和对话域脚手架。
3.2.1 说话人角色SCAFFOLD
我们的编解码模型使用对话中不同说话者的单独编码。说话人的话语和系统的话语被输入进user encoder,system encoder,从而得到他们的隐向量。注意力分布和上下文向量被分别计算如3.1中所描述的那样。为了合并这两个编码器在我们的模型中,解码器的初始状态由他们的隐向量合并而成。
我们模型中的指针机制如下式琐事,最后得到了上下文向量。
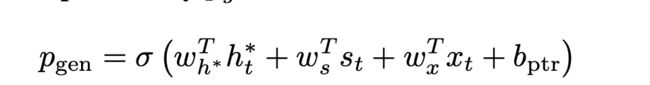
3.2.2 semantic slot scaffold
我们通过对原始对话执行去词法化来集成语义槽脚手架。去词法化是对话建模中常见的预处理步骤。具体来说,去词法化用其语义槽名称替换槽值,比如把18:00换成[time]。
对于语言模型来说,处理去词法化,因为他们有一个被削减的词汇尺寸。但是这些被生成的句子缺少语义信息,由于去词法化。一些对话系统忽视掉了这个问题 (Wen et al., 2015) ,或者完成了单个去词法化的话语(Sharma et al., 2017) 作为被生成的回应。我们建议在对话摘要中执行去词法化,因为去词法化的话语可以简化对话建模。 我们用复制和指向机制用插槽填充生成的模板。
我们首先使用去词法化的话语训练模版。源标记上的注意力分布指示解码器用词法化值填充槽。请注意,w 指定了代表插槽名称的标记(例如 [hotel place]、[time])。 解码器直接复制以注意力分布 ai 为条件的词法化值。
3.2.3 dialogue domain scaffold
我们通过多任务框架集成对话域脚手架。 对话域表示不同的对话任务内容,例如在 MultiWOZ 数据集中预订酒店、餐厅和出租车。 通常,不同领域的内容不同,因此多领域任务概括比单领域更困难。我们将域分类作为辅助任务,以结合不同域具有不同内容的先验。 来自域分类任务的反馈为编码器提供了特定于域的信息,以学习更好的表示。
对于域分类,我们通过具有两个线性层的二元分类器将级联编码器隐藏状态馈送,产生域概率 d。
d中的第i个元素di表示第i个域的可能性。我们把摘要的损失函数定义为loss1,域分类的结果作为loss2.估计第t个时间步的目标词是w,loss1是负对数似然的算术平均值。
域分类任务是一个多标签二进制分类任务。我们使用二进制交叉上损失,并且预测概率d对于这个任务。

4 实验设定
4.2 评价指标
ROUGE是摘要的标准指标,被设计用来预测surface word alignment在一个生成摘要和一个手写摘要之间,我们评估我们的模型用 ROUGE-1 ROUGE-2 和 ROUGE-L。他们评价了word-overlap,bigram-overlap以及参考摘要和生成摘要的最长公共序列。我们计算ROUGE分数使用files2rouge package。然而,ROUGE不足以衡量摘要表现。下面的例子展示了这个缺陷:
Reference: You are going to [restaurant name] at [time].
Summary: You are going to [restaurant name] at.
在这种情况下,摘要有了一个很高的ROUGE分数,因为他们的word-overlap比率很高。然而,他却有着很糟糕的相关性和可读性,特别是忽略掉了最重要的信息:time。
ROUGE 在计算 n-gram 重叠时平等对待每个单词,而信息量实际上各不相同:常用单词或短语(例如“You are going to”)对 ROUGE 分数和可读性有显着贡献,但它们几乎与基本内容无关。
semantic slot value比起摘要中的其他词更重要。然而ROUGE却没有把这些词纳入考虑。为了解决ROUGE的这些确定,我们提出了一个新的评价方式:关键信息完整度(CIC)。通常情况下而言,形式上,CIC 是对候选摘要和参考摘要之间语义槽信息的召回。
Controllable Abstractive Dialogue Summarization with Sketch Supervision
模型基于BART-xsum。
移除一些不重要的信息可以让模型更好的关注重要的部分。
用预定义的疑问代词类别以编程方式标记每一轮的对话。生成的意图和压缩的对话一起构成了作为弱监督信号的摘要草图。
再加入一个控制信息去选择长度。(用dialogue-turn-level的二进制分类器来学习去设置分割的点)
用这两个来训练。
摘要
一个两阶段的生成策略,生成一个初步的概要草图,作为最终概要的基础。
1) 这个概要草图以伪标记(psudo-labeld)的疑问代词类别(interrogative pronoun categories)和使用选区解析器提取(constituency parser)的关键短语(key phrases)的形式提供了一个弱监督信号(weakly supervised signal)。 即, 提出了一个弱监督模型。
2) 一种控制最终摘要粒度的简单策略,因为我们的模型可以通过预测和突出显示源文本的不同文本跨度来自动确定或控制给定对话的生成摘要句子的数量。 即,可以控制摘要的长度。
Introduction
生成式摘要需要高级的语义理解,因为输出的词不必要出现在源文档上。这更有挑战性,他给了摘要更多的灵活性比起抽取式摘要。大量的研究集中在单说话人文档摘要,比如文本摘要(Liao et al., 2018)和新闻摘要(Hermann et al., 2015; Nal- lapati et al., 2016; See et al., 2017) 或者是科研杂志摘要 (Qazvinian and Radev, 2008; Nikolov et al., 2018)。然而对话摘要没有收到很多的关注,尽管对话十分普遍(text messages, email, social media, etc.) 。
对话摘要有很多不同的挑战:
1)跨多个说话者的分布式信息。 最重要的信息通常分散在不同说话者的几个会话中,而在文章中,它主要出现在标题或前几句话中。
2)边界检测。 在每一轮中,停顿并不总是与语言合理的片段相匹配; 由于周围的非内容噪音和不流畅,很难跨轮次识别各种关键信息。
3) 建模说话者之间的交互。 说话者交互起着重要作用,因为它暗示了当前对话状态和下一个说话者的状态。
如果我们直接应用主要将整个输入编码为源序列的神经抽象摘要模型,对话的流程将被忽略。(Pan et al., 2018).
过去的方法(Goo and Chen, 2018; Liu et al., 2019) 依赖于详细的标注去捕捉对话的逻辑性,然而,这样的标注不总是能在数据集当中起作用的,并且添加额外的标签很笨拙。
为了解决这些挑战,我们提出了一个CODS,a COntrollable abstractive Dialogue Summariza- tion model equipped with sketch generation.我们首个自动的创建了一个summary sketch 包含了使用者注意信息和可能出现在摘要中关键的词段落。它表明了每轮中说话人和显著信息之间的交互。这个摘要sketch是human-annotated摘要的前缀,在fine-tuning一个生成器,提供了弱监督作为最终摘要。此外,我们提出了一个可控长度的生成方法。合适的摘要长度强烈的依赖于源摘要和使用者想要理解的信息粒度中所包含的信息的数量(Kikuchi et al., 2016)。我们首先把对话分为不同的部分通过线性地匹配每一个摘要的句子和他相关的对话上下文。然后我们训练模型用来产生只有一句话对于每个摘要的片段。这样的策略里用了对话的分布信息并且让生成的摘要更加可跟踪。
我们的模型基于BART-xsum(Lewis et al., 2019),首先使用无监督去噪目标进行预训练,并在新闻摘要语料库 XSUM 上进一步微调 (Narayan et al., 2018)。然后我们把我们的步骤应用在了SAMSum (Gliwa et al., 2019),,最大的对话摘要数据库。
我们的工作有:
1)提出了一个two-stage strategy 使用人工摘要sketch作为weak supervision
2)引入了一个基于text-span的条件生成方法去控制生成对话摘要的细粒度,没有人们手写摘要在不同的细节登记。即控制输出对话的长度
3)我们引入了综合情况研究和人们评估去表明CODS能够实现一致性和信息性的摘要,特别是对于可控摘要,存在着现有模型要么做不到,要么做不好。
Methodology
Generative Pre-trained Language Models
没有研究表明半监督学习语言任务可以应用在dialogue summarization,人们已经认为有一个内部的语言图案的不同在人类对话和写作文字上。我们想回答哪个生成语言模型是对话摘要任务的最佳基础模型的问题。
Sketch Construction
与新闻或科学出版物不同,会话数据包括许多非事实的句子,例如闲聊和问候。在对话中删除这些最不重要的信息可能有助于模型更好地关注主要内容。基于这个假说,我们结合了一个syntax-driven句子压缩方式用神经内容选择。
另外一个帮助是,每一个对话的轮次内部编码使用者的意图。然而,不想任务驱动的对话系统,有着详细的标注内容。例如(book flight 和 check account),对话摘要数据几乎没有这样的标签。因此,我们使用 Snorkel 的一些启发式方法(Ratner et al., 2019)用预定义的疑问代词类别以编程方式标记每一轮的对话。生成的意图和压缩的对话一起构成了作为弱监督信号的摘要草图。
据我们所知,一般来说,没有非面向任务的既定标签集。 因此,我们借鉴了新闻和研究调查中经常提到的五个 W 原则,因为一篇文章只有在回答这些问题时才被认为是完整的。(Hart)我们将这一原则应用于对话场景,并确定一组疑问代词以支持所有话语的足够多样化的用户意图,作为对话的逻辑。why, what, where, confirm, and abstain等等。
为了压缩和去除对话中的嘈杂子句,我们首先使用经过训练的constituency parser (Kitaev 和 Klein,2018 年)来解析每个话语。然后我们将解析的短语与真实摘要进行比较以找到它们的最长公共子序列(lcs),我们设置了一个阈值来过滤和删除 lcs 中无意义的词(例如,停用词)。请注意,在某些情况下,整个话语都是嘈杂且可移除的。
总而言之,我们建立了一个summary sketch通过连接对话标签,使用者意图标签和被压缩的话,将整个对话历史中的话语压缩成一个字符串,以特殊标记结尾“LD;DR”。我们训练模型,第一不是生成这个summary sketch,然后产生最终的摘要用一个自回归的方式。我们使用TD;DR标志去区分sketch和最后的摘要。
Controllability
由于可控语言建模的成功(Keskar et al., 2019),在新闻领域控制文本摘要的能力逐渐受到关注(Fan et al., 2018; Liu et al., 2018) 。我们解决方案的高级直觉是,如果我们可以控制一个生成模型只为部分突出显示的输入生成一个句子作为输出,我们可以通过选择如何突出显示输入来控制输出句子的数量。我们使用符号来突出每个对话的分隔符。比如根据前几轮去形成一个摘要,这样子。这样以来,我们不仅可以对摘要进行控制也可以让生成更具有可解释性。
下一个挑战是,在训练期间,我们必须在参考摘要中的每个句子与其对应的对话拆分之间找到映射。换句话是,怎么找到在哪里看到HL?我们通过训练一个对话-轮 级别的二进制分类器(将在下面详细解释)预测是否一轮对话应该用一个切点来切分。我们的观察是,参考摘要中的句子通常具有很强的时间依赖性,即人们几乎线性地总结对话。 我们使用一种简单的方法来找到切入点:对话和每个摘要句子之间的最高相似度得分。

使用此启发式提供的伪标签 ™,我们将对话分割问题公式化为二元分类问题。 具体来说,我们训练了一个分类器 C,它以对话历史作为输入并预测每个对话回合是否是一个切入点。 我们在每个对话轮前加上一个分离标记作为分类器的输入。
这种预测意味着我们的模型可以自动确定在最终摘要中应该生成多少句子。 如果没有触发切割点,我们会生成一个句子摘要。 如果触发一个切割点,我们将有一个两句话的摘要,依此类推。
最终,我们能够控制输出摘要句子的数量通过控制对话间隙。特别的,我们首先确定输出句子的期望数量(K),然后我们选择可能性最高的前K-1个索引。我们用着K-1个索引作为切分点。我们也能产生一句话的摘要。
Overall Generation
ABSTRACTIVE DIALOGUE SUMMARIZATION WITH SENTENCE-GATED MODELING OPTIMIZED BY DIALOGUE ACTS
seq2seq 结构
摘要
1、生成式神经网络模型变得越来越普遍,现在的工作专注于单说话人文档。对话中有很多和单说话人文档不同的地方,比如XXX(这里是dialogue acts)信息会对对话摘要有帮助。
2、这篇文章提出了利用dialogue acts作为神经网络摘要模型,使用了sentence-gated mechanism用来建模dialogue acts和summary之间的关联性。
3、实验在哪些数据集(这里是AMI meeting)上取得了重大的成果。
Introduction

对话行为的分类和概括通常是独立处理的,用于不同的目标。 在本文中,我们利用对话行为信息来改进对话摘要。 假设对话行为,表明交互信号,可能对更好的总结很重要,如何有效地将信息整合到神经总结模型中是本文的主要重点。 先前的工作尝试对话语信息进行建模,并提出了使用分层 RNN [37] 的话语感知摘要模型,其中话语间线索以隐式方式建模。 此外,他们在出版物摘要任务中执行该模型,其中输入文档相对结构化,并且此类文档中没有交互行为。
即,把对话行为信息融合进模型
因此,这项工作的重点是如何有效地对对话行为等交互信号进行建模以更好地进行对话摘要,我们引入了一个句子门控机制来联合建模对话行为和摘要之间的显式关系。 据我们所知,以前没有类似想法的研究,我们将我们的贡献总结为三方面:
• The proposed model is the first attempt for dialogue summarization using dialogue acts as explicit interac- tive signals.
• We benchmark the dataset for abstractive summariza- tion in the meeting domain, where the summaries de- scribe the high-level goals of meetings. 建立了数据集——AMI
• Our proposed model achieves the state-of-the-art per- formance in dialogue summarization and helps us ana- lyze how much each utterance and its dialogue act af- fect the summaries.
PROPOSED APPROACH
1)a dialogue history encoder
2) a dialogue act labeler
3) an attentional summary
4) a sentence gate
3.1 Dialogue History Encoder
用BiLSTM获取输入表示
3.2 Dialogue Act Labeler
为了利用dialogue act信息,这个模组专注于预测dialogue acts对于所有的说话人。特别的是,s映射他的相关dialogue act label。
使用了注意力机制+softmax
3.3 Attentional Summary Decoder
3.4 Sentence-Gated Mechanism
门控机制能够模拟两种类型信息之间的显式关系,提出的句子门控模型引入了一个额外的门,该门利用摘要上下文向量对对话行为和摘要之间的关系进行建模.
Full attention
模型认为对话动作和摘要的关系使用dialogue act attention和summary attention。
Summary attention
模型只用summary attention建立门机制,他的参数大小比full attention要小。
Full Attention
首先,一个摘要动作的上下文向量和一个平均摘要上下文向量被结合,通过一个门。
g很大,表明dialogue act上下文向量和摘要上下文向量对输入序列的相同部分很关注,也表示对话动作的关联性,摘要很强壮,上下文信息很可靠对于预测结果的贡献。
Summary Attention
为了深入研究句子门机制的力量,我们消除了架构中的对话行为注意模块
该版本允许对话行为和摘要共享注意力机制,因此与完整注意力版本相比,这两种信息将以更直接的方式相互改进。
Joint End-to-End Training
为了学习由对话行为信息优化的摘要模型,我们制定了一个联合目标:
把dialogue action和summarization进行联合训练。
Do Boat and Ocean Suggest Beach? Dialogue Summarization with External Knowledge
摘要
建立了CODC模型
引用了外部知识,背景信息。
提出了evaluation metric based on CODC
introduction
- We address the problem of out-of-context inference in dialogue summarization for the first time, and provide an elaborative definition into the problem.
- We design a related metric based on Concepts Out-of Dialogue Context (CODC) to evaluate neural models’ ability of inferencing plausible novel concepts.
- We proposed Trans-KnowAttn, an abstractive dialogue summarization approach that incorporates an out-of-context inference (missing-link inference) module and a knowledge attention module to improve the inference capability in dialogue summarization.
有问题、有图片,似乎属于多模态问题
DIALOGSUM: A Real-Life Scenario Dialogue Summarization Dataset
一个数据集
Language Model as an Annotator: Exploring DialoGPT for Dialogue Summarization
将DialoGPT 应用在对话摘要中(相当于用transformer是如何进行对话摘要的)
摘要
当前的对话摘要系统通常使用许多通用语义特征(例如,关键字和主题)对文本进行编码,以获得更强大的对话建模能力。 然而,这些功能是通过开放域工具包获得的,这些工具包与对话无关或严重依赖人工注释。 在本文中,我们展示了 DialoGPT (Zhang et al., 2020b)(一种用于生成对话响应的预训练模型)如何开发为无监督对话注释器,它利用了 DialoGPT 中编码的对话背景知识。 我们应用 DialoGPT 在两个对话摘要数据集 SAM-Sum 和 AMI 上标记三种类型的特征,并使用预训练和非预训练模型作为我们的摘要器。 实验结果表明,我们提出的方法可以在两个数据集上获得显着的改进,并在 SAMSum 数据集上实现了新的最先进的性能。
Introduction
关键词提取旨在自动识别对话中的重要单词(如图1(a)所示)。 我们的 DialoGPT 注释器将不可预测的单词提取为关键字。 我们假设关键字包含大量信息,考虑到 DialoGPT 中编码的背景知识和对话上下文的上下文信息,这些信息很难预测。
冗余检测旨在检测对对话的整体含义没有核心贡献的冗余话语(如图 1(b)所示)。 我们的 DialoGPT 注释器将对于对话上下文表示无用的话语检测为冗余。 我们假设如果添加一个新的话语不会改变对话上下文表示,那么这个话语对预测响应没有影响,所以它是多余的。这种思想值得学习
主题分割旨在将对话分成主题连贯的部分(如图 1(c)所示)。 如果一个话语是不可预测的,我们的 DialoGPT 注释器会在一个话语之前插入一个主题分割点。 我们假设如果一个话语很难从基于 DialoGPT 的对话上下文中推断出来,那么这个话语可能属于一个新的话题。
Restructuring Conversations using Discourse Relations for Zero-shot Abstractive Dialogue Summarization
对话摘要具有不正式、无结构性等特点,而且数据比较少。
这篇文章提出了一个zero-shot合成摘要,使用discourse relations提供结构信息给对话.