PyTorch深度学习实践笔记#7 | 循环神经网络(基础篇)
PyTorch深度学习实践笔记#7 | 循环神经网络(基础篇)

嗨,我是error。
我来记录PyTorch深度学习实践的笔记了,这会是一个系列,后面会慢慢更新。个人之前都是使用tensorflow进行深度学习实践,这是第一次学习Pytorch,若笔记有误欢迎提出纠正!课件采用自B站"刘二大人"老师的视频【传送门】
其实本质上来讲RNN也是线性计算与非线性计算,只不过是各种计算的独特组合方式而已,通过巧妙的结构设计来获取传统计算不能获取的数据之间相关联信息的反馈。同时,基于参数共享的思想,使得RNN在拥有较复杂的结构下也能保持相对小的参数量。
如下图所示是RNN的一个十分基础的模型,虽然看上去由很多RNN块组成,但实际上因为每一个RNN块内部的参数都是一样的,所以就可以简化为左边的循环模型,实际上在pytorch中RNN时也是通过for循环来实现的。

下图是一个很基础的RNN内部图展示,可以看出其本质还是我们之前学过的计算方法
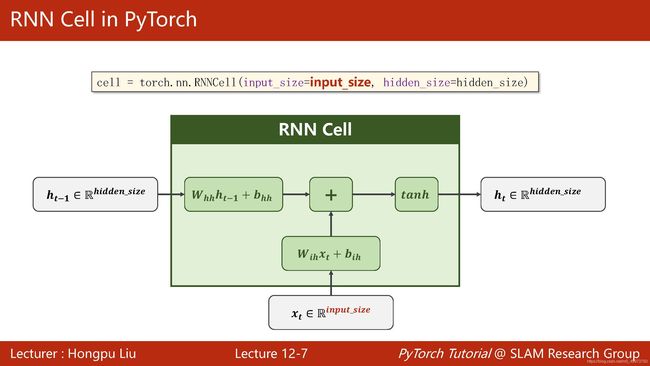
下图为pytorch中RNNCell的参数,只需输入inputsize和hiddensize即可,而在调用的时候我们是一个一个batch传进去数据的。

下面是一个实例来讲解,其实在构建神经网络中最重要的莫过于维度的匹配,在RNN中亦是如此


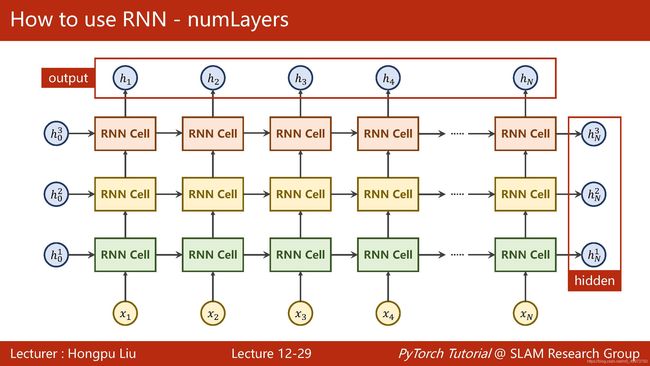
而在RNN中则还多了numlayers的参数,是的,你可以通过调节numlayers来控制模型的宽度,这时就应该注意hidden的第一维就是numlayers而不是batchsize了。同时注意这里cell输出的为两个值,out指每一块中输出的hidden,hidden指每一层最后输出的hidden


下面这一张图更直观的表示了out和hidden
当然,如果你不太习惯seq_len为第一维度,你可以将RNN中batchfirst的参数设置成true即可。

下面通过一个示例来加深我们之前所学的内容。假设我们现在要训练一个模型,使之能够学习从hello到ohlol的一个映射。
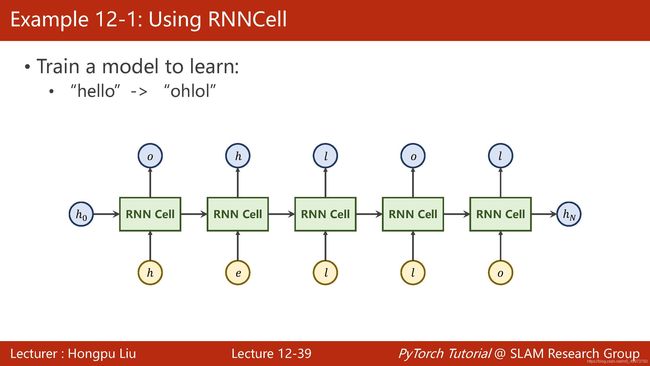
在此之前,我们要先明白在RNN中我们是通过One-Hot Vector的形式来表示每个输入的数据的。

因为最后的输出是一个预测向量,那么我们还是接上我们之前用过的CrossEntropyLoss模块。
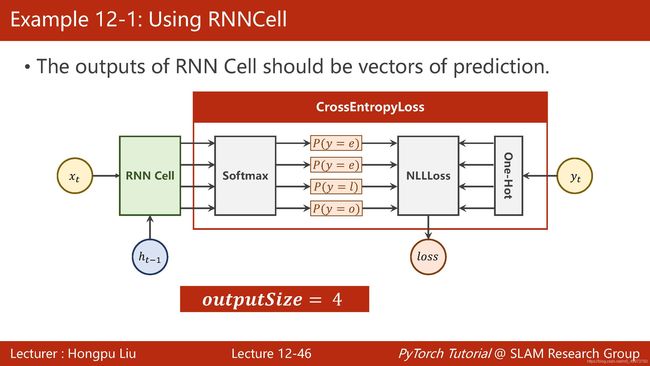
下图代码示例直接忽略了从dictionary到index的过程

主体代码如下,注意输入层和隐藏层第一个维度都是batchsize

优化器我们选择adam算法
这里的Training Cycle也注意别忘了清零梯度,而loss这里则采用加法,原因是我们这里遍历的是sqlen,每一步算出来的loss都是单个RNN模块的,最后自然要加起来才是完整一个数据的损失值。

因为最后的hidden输出的是概率矩阵,故我们将其概率最大的字母作为其预测值输出
下面贴上代码:
import torch
input_size = 4
hidden_size = 4
num_layers = 1
batch_size = 1
seq_len = 5
idx2char = ['e', 'h', 'l', 'o']
x_data = [1, 0, 2, 2, 3]
y_data = [3, 1, 2, 3, 2]
one_hot_lookup = [[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]]
x_one_hot = [one_hot_lookup[x] for x in x_data]
inputs = torch.Tensor(x_one_hot).view(-1, batch_size, input_size)
labels = torch.LongTensor(y_data).view(-1, 1)
class Model(torch.nn.Module):
def __init__(self, input_size, hidden_size, batch_size, num_layers=1):
super().__init__()
self.batch_size = batch_size
self.input_size = input_size
self.hidden_size = hidden_size
self.rnncell = torch.nn.RNNCell(input_size=self.input_size,
hidden_size=self.hidden_size)
def forward(self, input, hidden):
hidden = self.rnncell(input, hidden)
return hidden
def init_hidden(self):
return torch.zeros(self.batch_size, self.hidden_size)
net = Model(input_size, hidden_size, batch_size)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.1)
for epoch in range(30):
loss = 0
optimizer.zero_grad()
hidden = net.init_hidden()
print('Predicted string:', end='')
for input, label in zip(inputs, labels):
hidden = net(input, hidden)
loss += criterion(hidden, label)
_, idx = hidden.max(dim=1)
print(idx2char[idx.item()], end='')
loss.backward()
optimizer.step()
print(', Epoch [%d/30] loss=%.4f' % (epoch+1, loss.item()))
上面的代码是通过自己构造RNNCell来实现训练,其实也可以直接调用RNN模块来实现,思路一样,整体代码大同小异,就不再赘述。


因为one-hot encoding存在高维度、离散、硬编码的问题,我们一般采用一个更流行、更高效的方式——embedding。

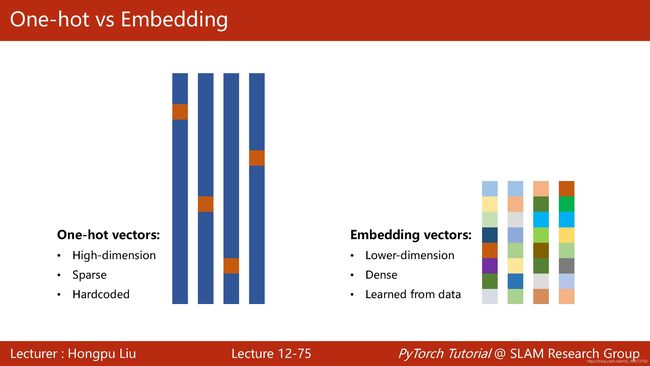
即加在输入层与RNN层之中
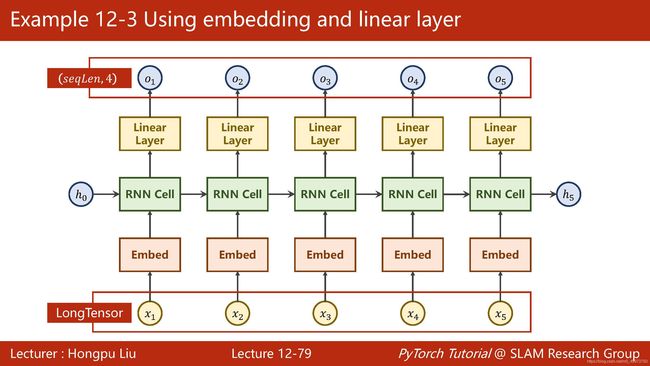
最头疼的是要去查看官方文档,注意各个维度的匹配问题
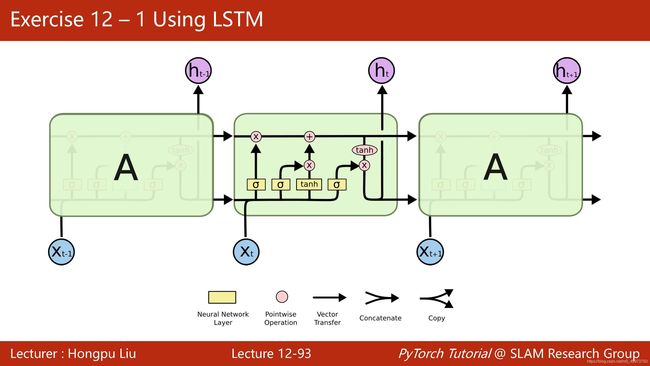
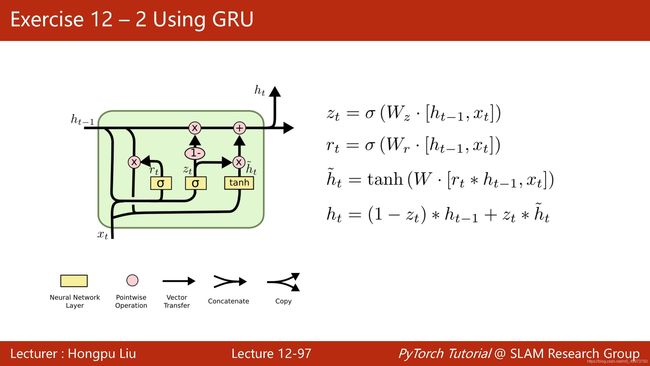
在此基础上还可以构建更为复杂的LSTM和GRU模块