Pytorch01—Tensors相关函数—Numpy和Tensor的转化—实现简单的神经网络
1.什么是PyTorch?
- PyTorch是一个基于Python的科学计算库,它有以下特点:
- 类似于NumPy,但是它可以使用GPU
- 可以用它定义深度学习模型,可以灵活地进行深度学习模型的训练和使用
2.基本函数
-
torch.empty—返回一个未初始化数据的张量.

-
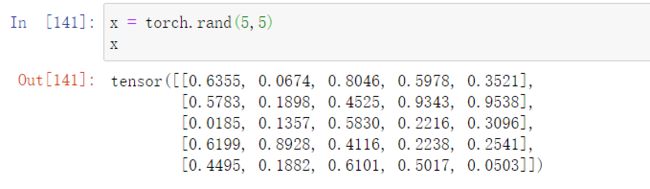
torch.rand—返回一个由[0,1)随机数填充的张量
-
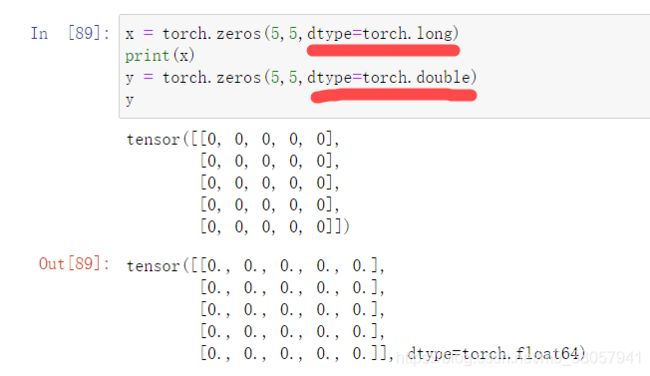
torch.zeros—构建一个全为0填充的张量
-
x.dtype—返回张量的数据类型

-
torch.tensor([数据])—从数据直接直接构建tensor:

-
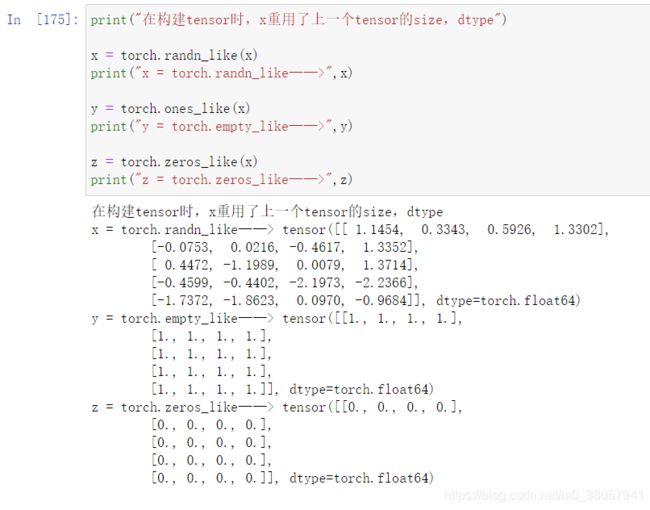
torch.xxxx_like(x)—在构建tensor时,重用了上一个x张量的size、dtype等参数
7. x.shape—得到tensor的形状:(返回的是一个tuple)

-
tensor_x + tensor_y 等同于 torch.add(x, y) 等同于 torch.add(x, y, out=result)

-
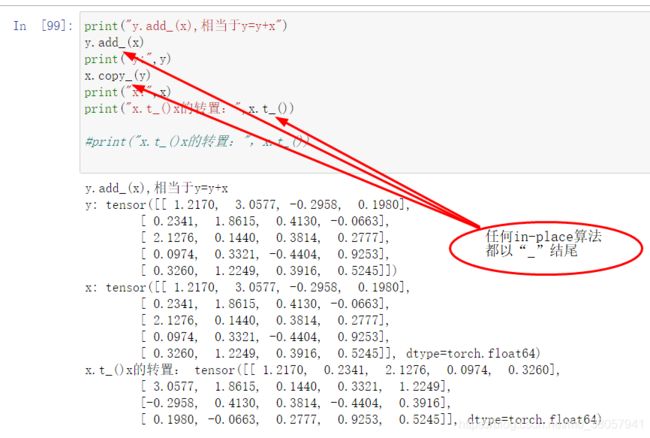
原地算法(in-place algorithm)基本上不需要额外辅助的数据结构
- 任何in-place的运算都会以
_结尾。 举例来说:x.copy_(y),x.t_(), 会改变x。
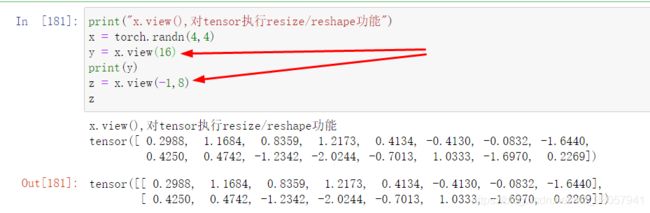
- torch.view:resize/reshape一个tensor
- 图中:y是16 × 1 张量
z:是2 × 8 张量——(-1,8),系统会自动把-1改为2。 - 不能2个位置都是-1,否则报错。
此例中除-1外,其他参数必须要可被16整除。
-
x.item()方法可以把1×1维的张量或者多维张量的某1个value变成Python数值

-
a.tolist(),能执行多维张量的“多个元素或某一个元素的"value的转换

2.Numpy和Tensor之间的转化
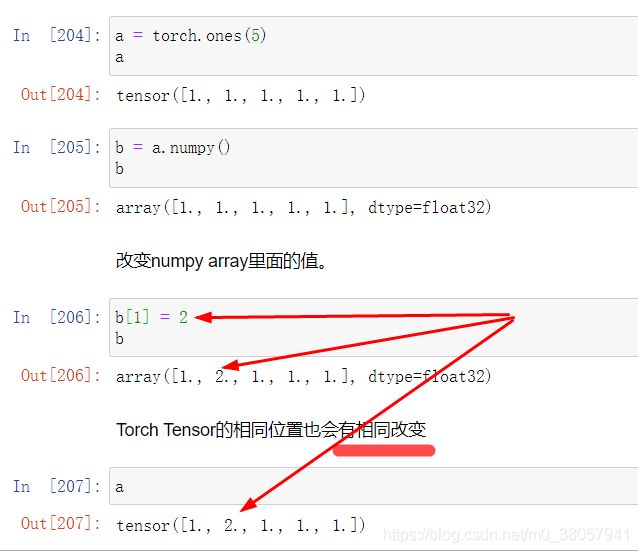
- 注意:Torch Tensor和NumPy array会共享内存,所以改变其中一项也会改变另一项。
2.1.Torch Tensor —变为—> NumPy array
-
b = a.numpy() //Torch Tensor ——> NumPy array
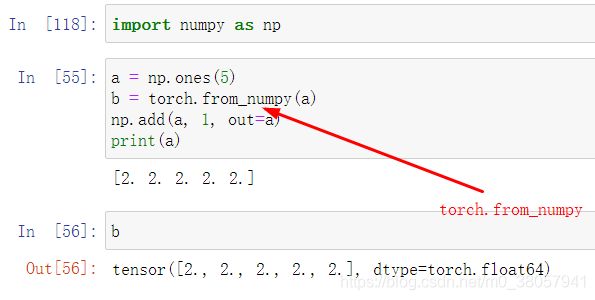
2.2.NumPy array—变为—>Torch Tensor
-
b = torch.from_numpy(a)
3.使用.to方法,Tensor可以被移动到别的device上

4.热身: 用numpy实现两层神经网络
一个全连接ReLU神经网络,一个隐藏层,没有bias。用来从x预测y,使用L2 Loss。
-
ℎ=1
-
=(0,ℎ)
-
ℎ=2
这一实现完全使用numpy来计算前向神经网络,loss,和反向传播。 -
forward pass
-
loss
-
backward pass
4.1.使用NumPy实现
numpy ndarray是一个普通的n维array。它不知道任何关于深度学习或者梯度(gradient)的知识,也不知道计算图(computation graph),只是一种用来计算数学运算的数据结构。
N, D_in, H, D_out = 64, 1000, 100, 10
# 随机创建一些训练数据
x = np.random.randn(N, D_in)
y = np.random.randn(N, D_out)
w1 = np.random.randn(D_in, H)
w2 = np.random.randn(H, D_out)
learning_rate = 1e-6
for it in range(500):
# Forward pass
h = x.dot(w1) # N * H
h_relu = np.maximum(h, 0) # N * H
y_pred = h_relu.dot(w2) # N * D_out
# compute loss
loss = np.square(y_pred - y).sum()
print(it, loss)
# Backward pass
# compute the gradient
grad_y_pred = 2.0 * (y_pred - y)
grad_w2 = h_relu.T.dot(grad_y_pred)
grad_h_relu = grad_y_pred.dot(w2.T)
grad_h = grad_h_relu.copy()
grad_h[h<0] = 0
grad_w1 = x.T.dot(grad_h)
# update weights of w1 and w2
w1 -= learning_rate * grad_w1
w2 -= learning_rate * grad_w2
执行结果:
4.2.PyTorch tensors来创建前向神经网络
一个PyTorch Tensor很像一个numpy的ndarray。但是它和numpy ndarray最大的区别是,PyTorch Tensor可以在CPU或者GPU上运算。如果想要在GPU上运算,就需要把Tensor换成cuda类型。
N, D_in, H, D_out = 64, 1000, 100, 10
# 随机创建一些训练数据
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
w1 = torch.randn(D_in, H)
w2 = torch.randn(H, D_out)
learning_rate = 1e-6
for it in range(500):
# Forward pass
h = x.mm(w1) # N * H
h_relu = h.clamp(min=0) # N * H
y_pred = h_relu.mm(w2) # N * D_out
# compute loss
loss = (y_pred - y).pow(2).sum().item()
#print(it, loss)
print("迭代次数:",it, "——损失:",loss)
# Backward pass
# compute the gradient
grad_y_pred = 2.0 * (y_pred - y)
grad_w2 = h_relu.t().mm(grad_y_pred)
grad_h_relu = grad_y_pred.mm(w2.t())
grad_h = grad_h_relu.clone()
grad_h[h<0] = 0
grad_w1 = x.t().mm(grad_h)
# update weights of w1 and w2
w1 -= learning_rate * grad_w1
w2 -= learning_rate * grad_w2
4.3.autograd——计算了loss之后,自动求导计算模型所有参数的梯度
执行结果:
x = torch.tensor(1., requires_grad=True)
w = torch.tensor(2., requires_grad=True)
b = torch.tensor(3., requires_grad=True)
y = w*x + b # y = 2*1+3
y.backward()
# dy / dw = x
print(w.grad)
print(x.grad)
print(b.grad)
4.4.PyTorch: Tensor和autograd
-
PyTorch的一个重要功能就是autograd,也就是说只要定义了forward pass(前向神经网络),计算了loss之后,PyTorch可以自动求导计算模型所有参数的梯度。
-
一个PyTorch的Tensor表示计算图中的一个节点。如果x是一个Tensor并且x.requires_grad=True那么x.grad是另一个储存着x当前梯度(相对于一个scalar,常常是loss)的向量。
N, D_in, H, D_out = 64, 1000, 100, 10
# 随机创建一些训练数据
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
w1 = torch.randn(D_in, H, requires_grad=True)
w2 = torch.randn(H, D_out, requires_grad=True)
learning_rate = 1e-6
for it in range(500):
# Forward pass
y_pred = x.mm(w1).clamp(min=0).mm(w2)
# compute loss
loss = (y_pred - y).pow(2).sum() # computation graph
# print(it, loss.item())
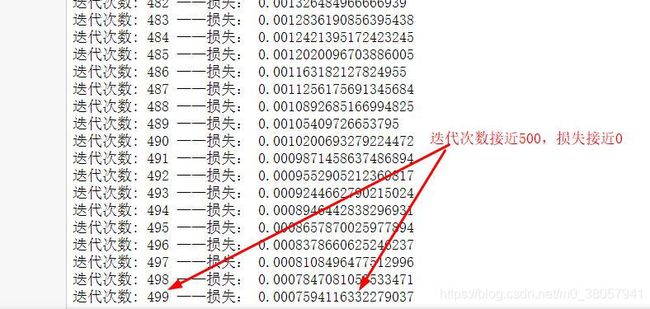
print("迭代次数:",it, "——损失:",loss)
# Backward pass
loss.backward()
# update weights of w1 and w2
with torch.no_grad():
w1 -= learning_rate * w1.grad
w2 -= learning_rate * w2.grad
w1.grad.zero_()
w2.grad.zero_()
4.5.PyTorch: nn,使用PyTorch中nn这个库来构建网络
- 用PyTorch autograd来构建计算图和计算gradients, 然后PyTorch会帮我们自动计算gradient。
注意:下面这条语句是清0本次计算出的梯度,因为,如果不清楚,它会累加
-
model.zero_grad()
import torch.nn as nn
N, D_in, H, D_out = 64, 1000, 100, 10
# 随机创建一些训练数据
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
model = torch.nn.Sequential(
#设置w1为1000*100
torch.nn.Linear(D_in, H, bias=False), # w_1 * x + b_1
torch.nn.ReLU(),
#设置w2为100*10
torch.nn.Linear(H, D_out, bias=False),
)
#初始化 w1
torch.nn.init.normal_(model[0].weight)
#初始化 w2
torch.nn.init.normal_(model[2].weight)
# model = model.cuda()
#(y_pred - y)的平方和
loss_fn = nn.MSELoss(reduction='sum')
learning_rate = 1e-6
for it in range(500):
# Forward pass
y_pred = model(x) # model.forward()
# compute loss
loss = loss_fn(y_pred, y) # computation graph
# print(it, loss.item())
print("迭代次数:",it, "——损失:",loss)
# Backward pass
loss.backward()
# update weights of w1 and w2
with torch.no_grad():
for param in model.parameters(): # param (tensor, grad)
#参数更新
param -= learning_rate * param.grad
#对模型本次迭代的 梯度 进行清0
model.zero_grad()
4.6.PyTorch: optim,使用optim包来更新参数,不再手动更新模型的weights
- optim这个package提供了各种不同的模型优化方法,包括SGD+momentum, RMSProp, Adam等等。
import torch.nn as nn
N, D_in, H, D_out = 64, 1000, 100, 10
# 随机创建一些训练数据
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
model = torch.nn.Sequential(
torch.nn.Linear(D_in, H, bias=False), # w_1 * x + b_1
torch.nn.ReLU(),
torch.nn.Linear(H, D_out, bias=False),
)
torch.nn.init.normal_(model[0].weight)
torch.nn.init.normal_(model[2].weight)
# model = model.cuda()
loss_fn = nn.MSELoss(reduction='sum')
# learning_rate = 1e-4
# optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
learning_rate = 1e-6
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
for it in range(500):
# Forward pass
y_pred = model(x) # model.forward()
# compute loss
loss = loss_fn(y_pred, y) # computation graph
# print(it, loss.item())
print("迭代次数:",it, "——损失:",loss)
#Clears the gradients of all optimized torch.Tensor
#每次反向传播前都清0一次
optimizer.zero_grad()
# Backward pass
loss.backward()
# update model parameters
optimizer.step()
4.7.PyTorch: 自定义 nn Modules,
- 自定义一个模型,这个模型继承自nn.Module类。如果需要定义一个比Sequential模型更加复杂的模型,就需要定义nn.Module模型。
import torch.nn as nn
N, D_in, H, D_out = 64, 1000, 100, 10
# 随机创建一些训练数据
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
class TwoLayerNet(torch.nn.Module):
def __init__(self, D_in, H, D_out):
super(TwoLayerNet, self).__init__()
# define the model architecture
self.linear1 = torch.nn.Linear(D_in, H, bias=False)
self.linear2 = torch.nn.Linear(H, D_out, bias=False)
def forward(self, x):
#执行预测
y_pred = self.linear2(self.linear1(x).clamp(min=0))
return y_pred
#初始化模型
model = TwoLayerNet(D_in, H, D_out)
loss_fn = nn.MSELoss(reduction='sum')
learning_rate = 1e-4
#选择梯度优化方法
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
for it in range(500):
# Forward pass
y_pred = model(x) # model.forward()
# compute loss
loss = loss_fn(y_pred, y) # computation graph
#print(it, loss.item())
print("迭代次数:",it, "——损失:",loss)
optimizer.zero_grad()
# Backward pass
loss.backward()
# update model parameters
optimizer.step()