Stata字符串函数:快捷提取字符信息
1.substr()函数的用法
语法:substr(s,n1,n2)
a. s为需要进行提取的字符串
b. n1表示提取的起始位置。
c. 对于不同编码的文本,n2代表不同含义。对于纯ASCII编码的文本,n2表示要提取字符长度为n2的字符串。而对于其他非ASCII编码的文本来说,n2表示要提取字节长度为n2的字符串。
(当然,对于那些纯ASCII编码的字符来说,上述两种说法是等价的。需要注意的是,所有utf-8编码中超出ASCII编码范围的字符都是两个字节以上。)
dis substr('abcde',1,3)
abc
//一个汉字字符占三个字节
dis substr('爬虫俱乐部',1,3)
爬n1的取值为负整数时,意味着自后向前数从第|n1|个字节的位置开始提取字符信息
dis substr("爬虫俱乐部",-6,3)
乐当n2是.(缺失值)时,意味着字符串从第n1个字节开始提取到最后一个字节。
dis substr("abcde",3,.)
cde2.usubstr()函数的用法
语法:usubstr(s,n1,n2)
usubstr()函数的大部分用法与substr()函数相同。区别在于,usubstr()函数适用于所有unicode编码的字符串,而substr()函数在使用过程中需要区分字符串是否为ASCII编码。
dis unubstr("爬虫俱乐部",2,3)
虫俱乐3. ustrleft()函数
ustrleft(s,n)
a. s为需要进行提取的字符串,s为所有unicode编码的字符;
b. n表示从字符串的最左边开始算起提取字符长度为n的字符串。其中n取值为正整数。
dis ustrleft("爬虫俱乐部",3)
爬虫俱4. ustrright()函数
语法:ustrright(s,n)
a. s为需要进行提取的字符串,s为所有unicode编码的字符;
b. n表示从字符串的最右边开始算起提取字符长度为n的字符串。其中n取值为正整数。
dis ustrright("爬虫俱乐部",3)
俱乐部example:
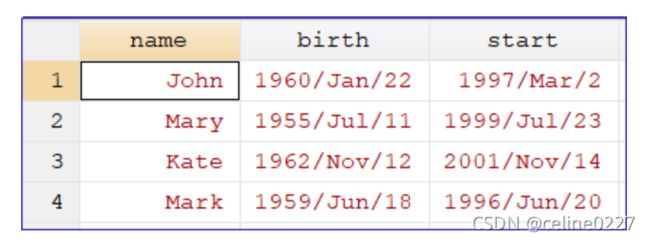
如果我们想要提取start变量中的年份,运行以下程序,结果如下图所示:
replace start = usubstr(start, 1, 4)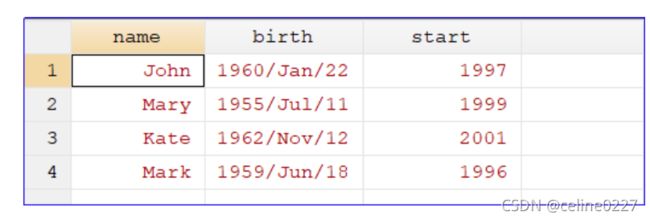
如果我们想提取birth变量下的年、月、日信息,并将对应内容放到新变量中,操作如下:
gen year = real(ustrleft(birth, 4)) //提取birth变量中前四个字符,利用 real()函数将字符型变量转换为数值型变量
gen month = substr(birth, 6, 3) //从birth变量中第 6个字符开始提取 3个字符的内容到新变量中
gen day = real(ustrright(birth, 2)) //提取birth变量中最后两个字符 
5. 用stata分离省市名称
(1)通过正则化方式
gen province=ustrregexs(0) if ustrregexm(officeaddress,".*省")
replace province=ustrregexs(0) if ustrregexm(officeaddress,".*自治区")
replace province=ustrregexs(0) if ustrregexm(officeaddress,"北京市|重庆市|天津市|上海市")
gen city=ustrregexs(0) if ustrregexm(officeaddress,".*?市")
replace city=ustrregexra(city,province,"")(2)excel帮助
A. 提取省份
公式:=LEFT(A2,MIN(FIND({"省","市","区"}, A2&"省市区")))
公式解析:通过left函数,从A2单元格(地址所在的单元格)字符串的左边开始提取字符,提取的字符个数是字符串中最早出现【省/市/区】的位置数字。
B. 提取市区
添加辅助列,公式为=SUBSTITUTE(A2,B2,""),表示拆分地址中除了省份之外,剩下的地址,并向下填充。
A2单元格(地址所在的单元格)B2单元格(提取出的省份信息单元格)
C. 接下来从剩下的地址中提取市区。
=LEFT(D2,MIN(FIND({"市","区","县"},D2&"市区县")))
B2=MID(A2,FIND("省",A2)+1,FIND("市",A2)-FIND("省",A2))
C2=MID(A2,FIND("市",A2)+1,FIND("区",A2)-FIND("市",A2))
D2=MID(A2,FIND("区",A2)+1,SUM(IFERROR(FIND({"路","街","道"},A2),0))-FIND("区",A2))