基于CNN的表情识别(FER)pytorch实现
Report for FER
Jian Tang
Abstract
我们使用卷积神经网络(CNN)实现了baby的面部表情识别(FER)。
工程代码: https://github.com/JianTang2000/FER2013
数据上,我们获取了开源FER数据集FER2013[1],besides我们使用爬虫获取了baby相关的人脸图片,进行了手工分类标注以形成一个全新的baby FER数据集。
模型上,我们首先复现了Luan[2]的工作,即参考Kuo[3]在CVPR 2018上的工作并实现一个轻量的CNN网络,在FER2013上进行训练并得到了 54% 的平均分类准确率(avg acc on valSet);然后我们将模型应用在baby FER数据集并得到avg acc 65%;我们将网络直接应用在baby FER数据集并进行训练,得到的新的avg acc为XXXX%;我们更改了模型的结构以更好的适应三通道,大分辨率的baby FER数据集,最后我们得到的avg acc是XXXX%。(数据没存,有时间再跑一次)
Data
FER2013
FER2013数据集是一个开源的,带标签的,划分好Train/Val的,含7类表情的,含多种族多性别多年龄段的人脸表情灰度图集,且通过对图片的观察我们发现图片存在带水印,卡通图,标签不准确等可能影响分类精度的问题。具体的表情类别和图片数量如下
FER2013 TrainSet数据类别和数量
class anger has img number: 3995
class disgust has img number: 436
class fear has img number: 4097
class happy has img number: 7215
class neutral has img number: 4965
class sad has img number: 4830
class surprised has img number: 3171
FER2013 ValSet数据类别和数量
class anger has img number: 491
class disgust has img number: 55
class fear has img number: 528
class happy has img number: 879
class neutral has img number: 626
class sad has img number: 594
class surprised has img number: 416
baby FER数据集
工作1。数据集的构建。首先我们爬取了baby的多种表情的图片;考虑到人工圈出人脸框是高人工消耗的,于是接着我们使用了Opencv的CascadeClassifier+Haar分类器[4]对人脸框进行自动寻找并裁剪;然后我们手工对裁剪后的人脸进行了分类标注,考虑到研究并不需要过多的表情类别,这里我们仅分了happy,peace,sad三类,同时,为了提高分类准确率,我们去掉了表情难以区分,带水印,灰度图,分辨率过小的图片;最后我们对数据进行2/8划分以得到TrainSet/ValSet。
最终的baby FER数据集是一个自建的,带标签的,划分好Train/Val的,含3类表情的,含多种族多性别的,年龄段均为baby的人脸表情非灰度图集。
其中valSet数量如下:
====> class happy has img number: 97
====> class peace has img number: 148
====> class sad has img number: 256
CNN Model
Luan给出了如下图1和图2的模型结构。具体的,因为FER2013只包含7类表情,为了适配模型的8类输出,Luan在FER数据集读入内存的时候增加了一列全0的虚拟数据,并给这类虚拟数据一个标签。
图1 CNN模型结构
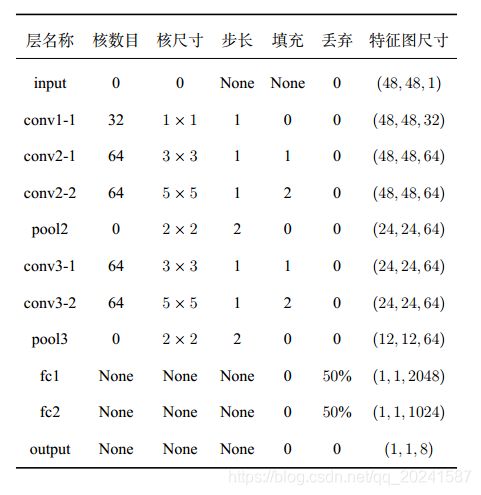
图1 CNN模型具体参数
工作2。考虑到Luan使用TensorFlow 2.3.1 Keras[5]实现网络结构,我们对keras的修改不算熟悉,且我们后期要对结构进行一些修改,于是我们选择使用pytorch[6]复现Luan的工作,但我们将模型输出改成7类,且并没有增加虚拟类数据,且加上了卷积层的padding,最后的模型输出结果如下
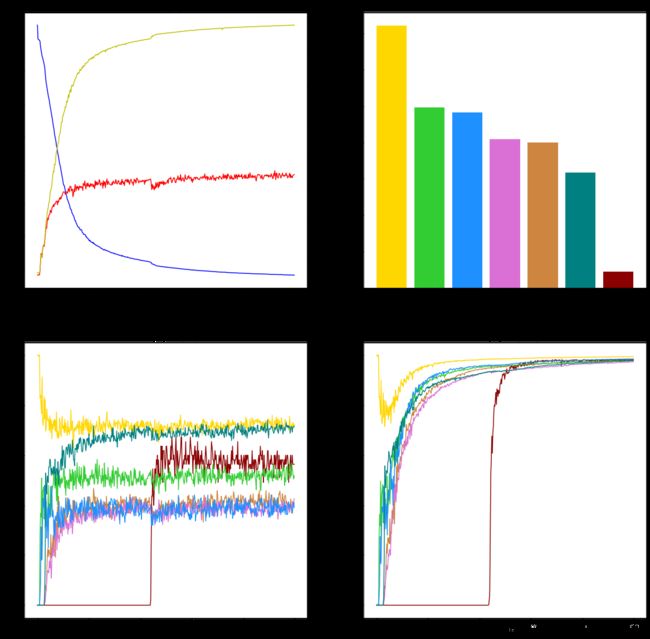
我们的输出和Luan的工作略有差别,我们在TrainSet的平均准确率达到了90%+,但在ValSet只达到了50%+,低于Luan的69%,我们猜测这可能是因为其增加的第八个虚拟类别导致的。
工作3。我们将模型应用在baby FER数据集,模型输出包括7种表情,但baby FER数据集的金标签只有3类,所以我们进行了一个映射。具体的,我们将模型输出进行映射,即将happy映射到happy,neutral映射到peace,其他映射到sad。我们得到的准确率如下:
acc for 3 classes (happy peace sad):
0.6804
0.723
0.6094
avg acc:
0.6567
工作4。我们更改了模型的结构以更好的适应baby FER数据集,具体的,我们将单通道的灰度图改成3通道图片然后送入模型,调大了模型的输入,从48*48调整为96*96,增加了conv的padding,最后我们得到的模型表现如下: (数据没保存,有空再做一次)
工程代码除了github,也可以在下面链接找到
链接:https://pan.baidu.com/s/10WxYg-0fdEkuXwgaMtOUbw
提取码:932n
[1] Challenges in Representation Learning: A report on three machine learning contests." I Goodfellow, D Erhan, PL Carrier, A Courville, M Mirza, B Hamner, W Cukierski, Y Tang, DH Lee, Y Zhou, C Ramaiah, F Feng, R Li, X Wang, D Athanasakis, J Shawe-Taylor, M Milakov, J Park, R Ionescu,M Popescu, C Grozea, J Bergstra, J Xie, L Romaszko, B Xu, Z Chuang, and Y. Bengio. arXiv 2013.
[2] https://github.com/luanshiyinyang/FacialExpressionRecognition
[3] Kuo C M, Lai S H, Sarkis M. A compact deep learning model for robust facial expression recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition workshops. 2018: 2121-2129.
[4] Soo S. Object detection using Haar-cascade Classifier[J]. Institute of Computer Science, University of Tartu, 2014, 2(3): 1-12.
[5] Ketkar N. Introduction to keras[M]//Deep learning with Python. Apress, Berkeley, CA, 2017: 97-111.
[6] Paszke A, Gross S, Massa F, et al. Pytorch: An imperative style, high-performance deep learning library[J]. arXiv preprint arXiv:1912.01703, 2019.