transformer
Attention在2014年由bengio团队提出。
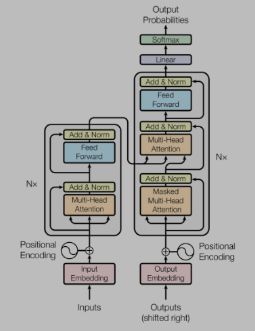
transformer本质是一种编解码结构。
Bert 基于transformer,由transformer的多个编码器组成。
transformer的编解码结构
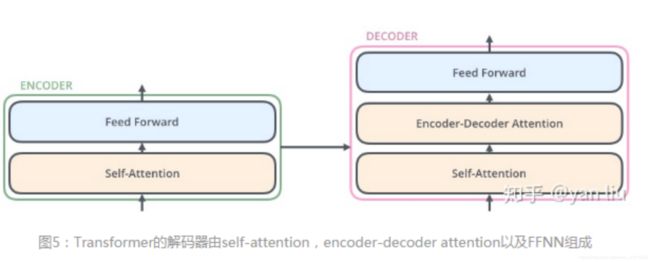
编码部分=self-Attenion + Feed Forward Neural Network
解码部分=self-Attenion + Encoder-Deccoder Attention+ Feed Forward Neural Network
self-attention:
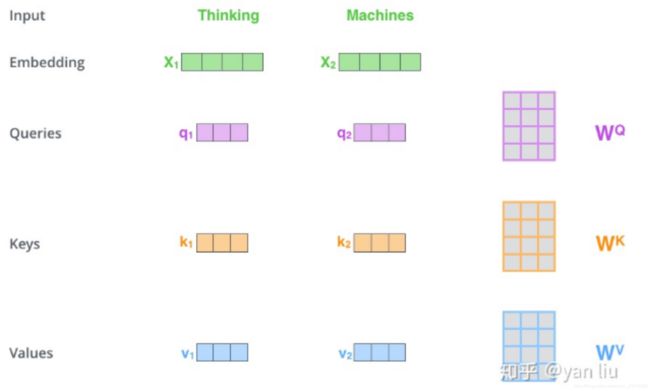
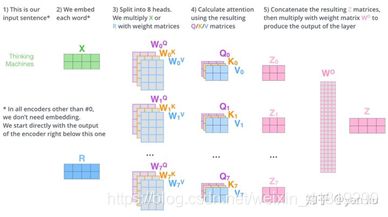
有三个不同的权值矩阵Wq、Wk、Wv
1)输入两个单词,经过embedding后(例如通过word2Vec等词嵌入方法),转换成等长的特征向量x(又称嵌入向量,均为512长度)。
2)x乘以三个权值矩阵Wq、Wk、Wv后(均为512*64维度),得到3个向量q、k、v(64维)
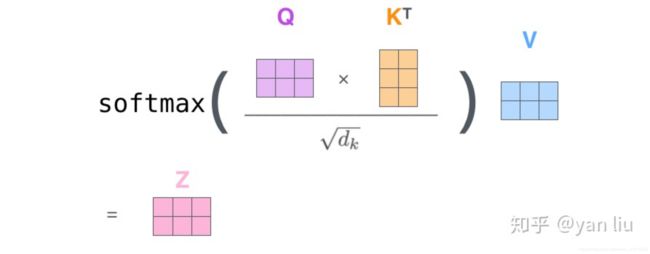
3)每个词有q、k、v共3个向量,根据q和k,计算一个score=q*k
4)为了梯度稳定,对score归一化,除k向量以维度开根号,score/![]() ,dk=64,实际就是除以8。这一步的目的是缩小softmax前的差距,进而缩小softmax后的差距。实例如下:
,dk=64,实际就是除以8。这一步的目的是缩小softmax前的差距,进而缩小softmax后的差距。实例如下:
import numpy as np
def softmax(x):
x = np.exp(x)
sum_x = np.sum(x)
return x/sum_x
a = np.array([112, 96]) # [ 9.99999887e-01 1.12535162e-07]
print(softmax(a))
a = np.array([112/8, 96/8]) # [ 0.88079708 0.11920292]
print(softmax(a))5)softmax,得到每个kv对应的权重
6)根据权重,对各个V加权求和,得到加权特征向量


Feed Forward Neural Network:
是个2层的全连接,第一层的激活函数是Relu,第二层是线性激活函数,下式中z代表self-attention的输出,FFN就是全连接结构。
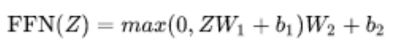
编码部分中还有位置编码position encoding和残差的设计,即
encoding=self-attentipn+feed forward+resnet+position encodding+add & Normalize

Multi-Head Attention
多头注意力机制,transformer使用了8头,初始化8个Q、K、V矩阵,将得到的8个zi进行concat连接后,经过一个全连接层,得到最终的z
Encoder-Decoder Attention
编解码注意力层,为解码器独有,接收上一层输出的Q和编码器输出的K、V
Masked Multi-Head Attention
掩码多头注意力机制,在解码过程中,只能获取当前位置前面的输出,后面位置信息是masked掩码的。
两种mask:padding mask、 sequence mask
padding mask:将不同长度的序列处理成一样长度,进行对齐,短的补0,长的截断。做法是把这些位置的值加上一个非常大的负数(负无穷),经过 softmax,这些位置的概率就会接近0。
a = np.array([112, -96]) # 较大的负数经过softmax接近于0
print(softmax(a)) # [ 1.00000000e+00 5.10908903e-12]sequence mask:
t的时刻解码器的输出只能依赖于前面的时刻。做法是产生一个上三角矩阵,上三角的值全为0,把这个矩阵作用在每一个序列上,就可以达到目的。
在需要2种mask效果叠加的场合,2个mask相加即可。
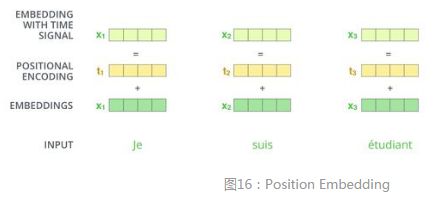
位置编码position embedding
有别于词袋模型,transformer对位置信息敏感,位置信息可以通过设计或学习得到。位置编码需要和嵌入向量相同维度,使2者可以相加。 在设计中,偶数位置,使用正弦编码,在奇数位置,使用余弦编码。


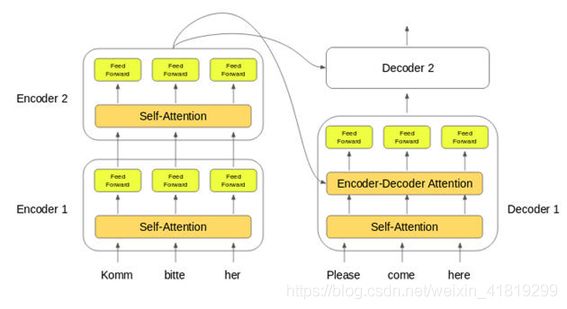
transformer完整结构图
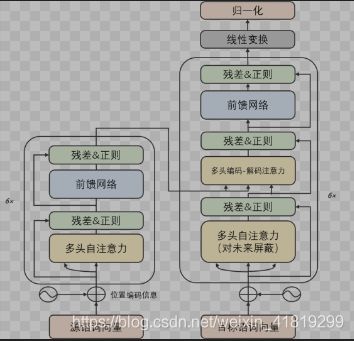
当需要多个编解码器形成堆栈时,将词嵌入(word embeddings)传递给第一个编码器。输出传递给下一个编码器,最后一个编码器的输出K、V传给所有解码器。
transformer是有别于cnn和rnn的一种新的结构,
优点:
- 并行能力,不依赖前一时刻的计算结果
- lstm等存在长期依赖问题,即便有门的设计也会出现信息丢失
缺点:
注意力只能处理固定长度的文本字符串。在输入系统之前,文本必须被分割成一定数量的段或块。这种文本块会导致上下文碎片化。例如,如果一个句子从中间分隔,那么大量的上下文就会丢失。换言之,在不考虑句子或任何其他语义边界的情况下对文本进行分隔。例如只能处理512长度的信息,有312个box时,切1段补0,;有600个box时,切2段补0。
针对这个切断问题,提出了Transformer-XL,将上一段的信息传递到下一段。
常见问题:
1、归一化除以根号dk的目的
参考transformer中的attention为什么scaled? - 知乎
有很多说法,包括:
1)减小softmax前的差距,不会过度关注于大的q*k,如softmax前差距过大,最大的q*k进行softmax后趋近1,softmax形成一个近似one-hot的向量,会造成梯度消失。1)减小softmax前的差距可减小softmax后的差距,使梯度正常传递。
2)选择根号dk的原因:softmax前方差控制为1
2、多头的目的及前后处理
学习到不同特征空间的信息,concat后通过全连接层融合
3、残差的目的
防止梯度消失,使网络更深,bert-base12层,bert-large24层
4、为什么要用LN代替BN
BN对整个batch中的样本在同一维度做处理。缺点:1)文本序列的特征在同一位置不在同一空间,如‘天气真好’和‘我喜欢吃西瓜’,‘天’和‘我’不能按照同一空间的思想进行归一化;2)不同长度的文本序列,较长的文本后面没有可靠的均值方差进行归一化,如按‘天’和‘我’进行归一化...多出来的‘西瓜’只能和padding的部分进行归一化了,在batch_size较小时尤为明显
LN是在单个样本内做缩放,如‘天气真好’内部进行归一化
5、解码器mask的目的
保持训练和测试时情况一致,测试时不能看到未来的输入输出
6、编码器信息如何传输到解码器中
多个编码器堆叠,最后一个编码器输出K、V矩阵,传输到每个解码器的交互层,与Q结合
参考文献:
https://zhuanlan.zhihu.com/p/48508221
https://www.infoq.cn/article/QBloqM0Rf*SV6v0JMUlF
Transformer各层网络结构详解!面试必备!(附代码实现) - mantch - 博客园