基于Aidlux平台的智慧交通AI安全算法实战
一、
通常来说,智慧交通行业主要是对交通场景内的行人,机动车,非机动车进行识别分析。
行人识别分析包括对行人的姿态,方向,外观,以及基于行人的交通事件识别分析,(行人闯红灯等)。
机动车识别分析包括对机动车的外型,颜色,车灯,车窗,驾驶员安全事件分析(是否在打电话,是否系安全带等),车牌,车辆方向以及基于机动车的交通事件识别分析(超速检测,违停判定等)。
非机动车识别分析包括对非机动车的细分类别识别,运动状态识别,驾驶员安全事件分析(是否戴头盔等),以及基于非机动车的交通事件识别分析(非机动车闯红灯等)。

智慧交通的场景主要划分为:十字路口,交通卡口,交通出入口,停车场等场景。不同公司的业务领域、覆盖范围都不一样。有些会做交通场景的整体解决方案,有些会做算法提供商,还有一些会做交通细分领域的解决方案或者算法提供商。
在智慧交通的的场景中,每个场景都对应了不同的算法业务功能,每个算法业务功能则是由不同应用技术如目标检测,图像分割,图像分类,目标追踪,OCR识别等组合而成。

应用场景,AI算法功能,Ai算法模型这三者有机结合,形成了面对不同需求的整体算法解决方案。在上图里的AI算法功能中:车辆识别功能其底层的算法技术主要是车辆检测+车牌检测+车牌字符识别+业务功能判断等组成。这里的业务功能,包括车辆框矫正,车牌框矫正,车牌字符后处理等逻辑;行人识别算法功能,其底层的算法技术主要是行人检测+人脸识别+行人重识别等组成;车辆属性识别算法功能,其底层主要是车辆检测+车标识别+车系识别+驾驶员行为识别等组成。交通事件检测算法功能则更为复杂,其需要大量的交通规则作为约束,并且在检测机动车,行人以及非机动车的同时,要准确感知当前的背景环境条件。比如检测交通指示牌,检测交通道路指示线等来对交通事件的判定进行支持。行人闯红灯,车辆闯红灯,机动车超速,超时停车,机动车违停等都属于上述所说的交通事件中的典型细分功能。
二、
# aidlux相关
from cvs import *
import aidlite_gpu
from utils import detect_postprocess, preprocess_img, draw_detect_res #extract_detect_res
import time
import cv2
# AidLite初始化:调用AidLite进行AI模型的加载与推理,需导入aidlite
aidlite = aidlite_gpu.aidlite()
# Aidlite模型路径
model_path = '/home/lesson3_codes/yolov5_code/models/yolov5_car_best-fp16.tflite'
# 定义输入输出shape
in_shape = [1 * 640 * 640 * 3 * 4]
out_shape = [1 * 25200 * 6 * 4]
# 加载Aidlite检测模型:支持tflite, tnn, mnn, ms, nb格式的模型加载
aidlite.ANNModel(model_path, in_shape, out_shape, 4, 0)
# 读取图片进行推理
# 设置测试集路径
source = "/home/yolov5_code/data/tests"
images_list = os.listdir(source)
print(images_list)
frame_id = 0
# 读取数据集
for image_name in images_list:
frame_id += 1
print("frame_id:", frame_id)
image_path = os.path.join(source, image_name)
frame = cvs.imread(image_path)
# 预处理
img = preprocess_img(frame, target_shape=(640, 640), div_num=255, means=None, stds=None)
# 数据转换:因为setTensor_Fp32()需要的是float32类型的数据,所以送入的input的数据需为float32,大多数的开发者都会忘记将图像的数据类型转换为float32
aidlite.setInput_Float32(img, 640, 640)
# 模型推理API
aidlite.invoke()
# 读取返回的结果
pred = aidlite.getOutput_Float32(0)
# 数据维度转换
pred = pred.reshape(1, 25200, 6)[0]
# 模型推理后处理
pred = detect_postprocess(pred, frame.shape, [640, 640, 3], conf_thres=0.25, iou_thres=0.45)
# 绘制推理结果
res_img = draw_detect_res(frame, pred)
cvs.imshow(res_img)
# 测试结果展示停顿
time.sleep(5)
# 图片裁剪,裁剪区域[Ly:Ry,Lx:Rx]
# cut_img = extract_detect_res(frame, pred)
# cvs.imshow(cut_img)
# cap.release()
# cv2.destroyAllWindows()


而防御者最直接了当的使用对抗攻击的形式是对抗训练。 使用对抗样本在模型训练过程中进行对抗训练,我们在训练时将对抗样本加入训练集一起训练,即为对抗训练。 进行对抗训练能扩充训练集的可能性,使得数据集逼近我们想要的数据分布,训练后的模型鲁棒性和泛化性能也大大增强。
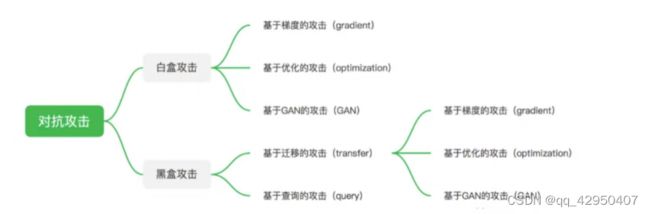

使用对抗攻击算法:
使用PGD攻击算法进行白盒攻击,将原模型model作为受攻击模型,eps代表对抗扰动的范围,eps_iter代表一次攻击的步长,nb_iter代表攻击次数,rand_init代表是否在一开始生成一个随机的对抗扰动。

等待一段时间,攻击就完成了,此时会输出对抗样本advimg。
对抗攻击效果验证:


 了解了上面的实验结果,可以看到,PGD对抗攻击的效果还是非常好的,只是添加了人眼系统一时无 法分辨的微小对抗扰动,就可以使得AI模型出现严重的误判,这在智慧交通场景中,可能会引起很多 不确定风险。
了解了上面的实验结果,可以看到,PGD对抗攻击的效果还是非常好的,只是添加了人眼系统一时无 法分辨的微小对抗扰动,就可以使得AI模型出现严重的误判,这在智慧交通场景中,可能会引起很多 不确定风险。
对抗攻击代码如下:
import os
import torch
import torch.nn as nn
from torchvision.models import mobilenet_v2
from advertorch.utils import predict_from_logits
from advertorch.utils import NormalizeByChannelMeanStd
from robust_layer import GradientConcealment, ResizedPaddingLayer
from advertorch.attacks import LinfPGDAttack
from advertorch_examples.utils import ImageNetClassNameLookup
from advertorch_examples.utils import bhwc2bchw
from advertorch_examples.utils import bchw2bhwc
device = "cuda" if torch.cuda.is_available() else "cpu"
### 读取图片
def get_image():
img_path = os.path.join("E:/AidLux2/Lesson4_code/adv_code/images", "cab.png")
img_url = "https://farm1.static.flickr.com/230/524562325_fb0a11d1e1.jpg"
def _load_image():
from skimage.io import imread
return imread(img_path) / 255.
if os.path.exists(img_path):
return _load_image()
else:
import urllib
urllib.request.urlretrieve(img_url, img_path)
return _load_image()
def tensor2npimg(tensor):
return bchw2bhwc(tensor[0].cpu().numpy())
### 展示攻击结果
def show_images(model, img, advimg, enhance=127):
np_advimg = tensor2npimg(advimg)
np_perturb = tensor2npimg(advimg - img)
pred = imagenet_label2classname(predict_from_logits(model(img)))
advpred = imagenet_label2classname(predict_from_logits(model(advimg)))
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 5))
plt.subplot(1, 3, 1)
plt.imshow(np_img)
plt.axis("off")
plt.title("original image\n prediction: {}".format(pred))
plt.subplot(1, 3, 2)
plt.imshow(np_perturb * enhance + 0.5)
plt.axis("off")
plt.title("the perturbation,\n enhanced {} times".format(enhance))
plt.subplot(1, 3, 3)
plt.imshow(np_advimg)
plt.axis("off")
plt.title("perturbed image\n prediction: {}".format(advpred))
plt.show()
normalize = NormalizeByChannelMeanStd(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
### GCM模块
robust_mode = GradientConcealment()
### 常规模型+GCM模块
class Model(nn.Module):
def __init__(self, l=290):
super(Model, self).__init__()
self.l = l
self.gcm = GradientConcealment()
# model = resnet18(pretrained=True)
model = mobilenet_v2(pretrained=True)
#替身模型加载
# pth_path = "/Users/rocky/Desktop/训练营/model/mobilenet_v2-b0353104.pth"
# print(f'Loading pth from {pth_path}')
# state_dict = torch.load(pth_path, map_location='cpu')
# is_strict = False
# if 'model' in state_dict.keys():
# model.load_state_dict(state_dict['model'], strict=is_strict)
# else:
# model.load_state_dict(state_dict, strict=is_strict)
normalize = NormalizeByChannelMeanStd(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
self.model = nn.Sequential(normalize, model)
def load_params(self):
pass
def forward(self, x):
x = self.gcm(x)
# x = ResizedPaddingLayer(self.l)(x)
out = self.model(x)
return out
### 常规模型+GCM模块 加载
model_defense = Model().eval().to(device)
### 数据预处理
np_img = get_image()
img = torch.tensor(bhwc2bchw(np_img))[None, :, :, :].float().to(device)
imagenet_label2classname = ImageNetClassNameLookup()
### 测试模型输出结果
pred_defense = imagenet_label2classname(predict_from_logits(model_defense(img)))
print("test output:", pred_defense)
pre_label = predict_from_logits(model_defense(img))
### 对抗攻击:PGD攻击算法
adversary = LinfPGDAttack(
model_defense, eps=8 / 255, eps_iter=2 / 255, nb_iter=80,
rand_init=True, targeted=False)
### 完成攻击,输出对抗样本
advimg = adversary.perturb(img, pre_label)
### 展示源图片,对抗扰动,对抗样本以及模型的输出结果
show_images(model_defense, img, advimg)
五、

我们在使用白盒攻击的基础上,进行迁移攻击,形成基于迁移的黑盒攻击。具体来说,上面我们已经将车辆目标区域提取出来,在实际AI项目中,攻击者一般难以获得算法模型的参数,白盒攻击难以展开。这时,可以选择另外一个模型作为替身模型,比如我们知道他后面会进行车辆分类,但是不知道用的什么分类模型(实际上系统方用的Mobilenetv2),这时我们可以使用一个已有的分类模型(ResNet18)作为替身。使用攻击算法对替身模型进行攻击,这样生成的车辆目标区域对抗样本一定程度上也会使得业务模型产生错误的输出。

import os
import torch
import torch.nn as nn
import torchvision.utils
from torchvision.models import mobilenet_v2,resnet18
from advertorch.utils import predict_from_logits
from advertorch.utils import NormalizeByChannelMeanStd
from robust_layer import GradientConcealment, ResizedPaddingLayer
from timm.models import create_model
# PGD攻击算法
from advertorch.attacks import LinfPGDAttack
#FGSM攻击算法
from advertorch.attacks import FGSM
#L1PGD攻击算法
from advertorch.attacks import L1PGDAttack
#L2PGD攻击算法
from advertorch.attacks import L2PGDAttack
#LinfMomentumIterative攻击算法
from advertorch.attacks import LinfMomentumIterativeAttack
from advertorch_examples.utils import ImageNetClassNameLookup
from advertorch_examples.utils import bhwc2bchw
from advertorch_examples.utils import bchw2bhwc
device = "cuda" if torch.cuda.is_available() else "cpu"
### 读取图片
def get_image():
img_path = os.path.join("/home/Lesson5_code/adv_code/adv_results", "adv_image.png")
img_url = "https://farm1.static.flickr.com/230/524562325_fb0a11d1e1.jpg"
def _load_image():
from skimage.io import imread
return imread(img_path) / 255.
if os.path.exists(img_path):
return _load_image()
else:
import urllib
urllib.request.urlretrieve(img_url, img_path)
return _load_image()
def tensor2npimg(tensor):
return bchw2bhwc(tensor[0].cpu().numpy())
### 展示攻击结果
def show_images(model, img, advimg, enhance=127):
np_advimg = tensor2npimg(advimg)
np_perturb = tensor2npimg(advimg - img)
pred = imagenet_label2classname(predict_from_logits(model(img)))
advpred = imagenet_label2classname(predict_from_logits(model(advimg)))
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 5))
plt.subplot(1, 3, 1)
plt.imshow(np_img)
plt.show()
plt.axis("off")
plt.title("original image\n prediction: {}".format(pred))
plt.subplot(1, 3, 2)
plt.imshow(np_perturb * enhance + 0.5)
plt.show()
plt.axis("off")
plt.title("the perturbation,\n enhanced {} times".format(enhance))
plt.subplot(1, 3, 3)
plt.imshow(np_advimg)
plt.axis("off")
plt.title("perturbed image\n prediction: {}".format(advpred))
plt.show()
normalize = NormalizeByChannelMeanStd(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
### 常规模型加载
model = mobilenet_v2(pretrained=True)
model.eval()
model = nn.Sequential(normalize, model)
model = model.to(device)
### 替身模型加载
model_su = resnet18(pretrained=True)
model_su.eval()
model_su = nn.Sequential(normalize, model_su)
model_su = model_su.to(device)
### 数据预处理
np_img = get_image()
img = torch.tensor(bhwc2bchw(np_img))[None, :, :, :].float().to(device)
imagenet_label2classname = ImageNetClassNameLookup()
### 测试模型输出结果
pred = imagenet_label2classname(predict_from_logits(model(img)))
print("test output:", pred)
### 输出原label
pred_label = predict_from_logits(model_su(img))
### 对抗攻击:FGSM攻击算法(eps = 0.5 / 255, 2 /255, 8 /255)
# adversary = FGSM(
# model_su, eps=8/255, eps_iter=2/255, nb_iter=80,
# rand_init=True, targeted=False)
### 对抗攻击:PGD攻击算法
adversary = LinfPGDAttack(
model_su, eps=8/255, eps_iter=2/255, nb_iter=80,
rand_init=True, targeted=False)
# ### 对抗攻击:L1PGD攻击算法
# adversary = L1PGDAttack(
# model_su, eps=1600, eps_iter=2/255, nb_iter=80,
# rand_init=True, targeted=False)
# ### 对抗攻击:L2PGD攻击算法
# adversary = L2PGDAttack(
# model_su, eps=8, eps_iter=2/255, nb_iter=80,
# rand_init=True, targeted=False)
# ### 对抗攻击:L1PGD攻击算法
# adversary = LinfMomentumIterativeAttack(
# model_su, eps=8/255, eps_iter=2/255, nb_iter=80,
# rand_init=True, targeted=False)
### 完成攻击,输出对抗样本
advimg = adversary.perturb(img, pred_label)
### 展示源图片,对抗扰动,对抗样本以及模型的输出结果
show_images(model, img, advimg)
### 迁移攻击样本保存
save_path = "/home/Lesson5_code/adv_code/adv_results/"
torchvision.utils.save_image(advimg.cpu().data, save_path + "adv_image.png")
### 对抗攻击监测模型
class Detect_Model(nn.Module):
def __init__(self, num_classes=2):
super(Detect_Model, self).__init__()
self.num_classes = num_classes
#model = create_model('mobilenetv3_large_075', pretrained=False, num_classes=num_classes)
model = create_model('resnet50', pretrained=False, num_classes=num_classes)
# self.multi_PreProcess = multi_PreProcess()
pth_path = os.path.join("/home/Lesson5_code/model", 'track2_resnet50_ANT_best_albation1_64_checkpoint.pth')
#pth_path = os.path.join("/Users/rocky/Desktop/训练营/Lesson5_code/model/", "track2_tf_mobilenetv3_large_075_64_checkpoint.pth")
state_dict = torch.load(pth_path, map_location='cpu')
is_strict = False
if 'model' in state_dict.keys():
model.load_state_dict(state_dict['model'], strict=is_strict)
else:
model.load_state_dict(state_dict, strict=is_strict)
normalize = NormalizeByChannelMeanStd(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
# self.model = nn.Sequential(normalize, self.multi_PreProcess, model)
self.model = nn.Sequential(normalize, model)
def load_params(self):
pass
def forward(self, x):
# x = x[:,:,32:193,32:193]
# x = F.interpolate(x, size=(224,224), mode="bilinear", align_corners=True)
# x = self.multi_PreProcess.forward(x)
out = self.model(x)
if self.num_classes == 2:
out = out.softmax(1)
#return out[:,1:]
return out[:,1:]
model = Model().eval().to(device)
detect_model = Detect_Model().eval().to(device)当对抗攻击监测模型,监测到对抗样本或者对抗攻击后。一般在实际场景的AI项目中,会出现一个告警弹窗,并且会告知安全人员及时进行安全排查。本文通过微信“喵提醒”的方式来实现。
整体的串联代码如下:
# aidlux相关
from cvs import *
import aidlite_gpu
from yolov5_code.aidlux.utils import detect_postprocess, preprocess_img, draw_detect_res, extract_detect_res
import os
import torch
import requests
import time
import torch.nn as nn
from torchvision.models import mobilenet_v2,resnet18
from advertorch.utils import predict_from_logits
from advertorch.utils import NormalizeByChannelMeanStd
from robust_layer import GradientConcealment, ResizedPaddingLayer
from timm.models import create_model
from advertorch.attacks import LinfPGDAttack
from advertorch_examples.utils import ImageNetClassNameLookup
from advertorch_examples.utils import bhwc2bchw
from advertorch_examples.utils import bchw2bhwc
device = "cuda" if torch.cuda.is_available() else "cpu"
import time
import cv2
# AidLite初始化:调用AidLite进行AI模型的加载与推理,需导入aidlite
aidlite = aidlite_gpu.aidlite()
# Aidlite模型路径
model_path = '/home/yolov5_code/models/yolov5_car_best-fp16.tflite'
# 定义输入输出shape
in_shape = [1 * 640 * 640 * 3 * 4]
out_shape = [1 * 25200 * 6 * 4]
# 加载Aidlite检测模型:支持tflite, tnn, mnn, ms, nb格式的模型加载
aidlite.ANNModel(model_path, in_shape, out_shape, 4, 0)
# 读取图片进行推理
# 设置测试集路径
source = "/home/Lesson5_code/adv_code/test_images"
images_list = os.listdir(source)
print(images_list)
frame_id = 0
# 读取数据集
for image_name in images_list:
frame_id += 1
print("frame_id:", frame_id)
image_path = os.path.join(source, image_name)
frame = cvs.imread(image_path)
# 预处理
img = preprocess_img(frame, target_shape=(640, 640), div_num=255, means=None, stds=None)
# 数据转换:因为setTensor_Fp32()需要的是float32类型的数据,所以送入的input的数据需为float32,大多数的开发者都会忘记将图像的数据类型转换为float32
aidlite.setInput_Float32(img, 640, 640)
# 模型推理API
aidlite.invoke()
# 读取返回的结果
pred = aidlite.getOutput_Float32(0)
# 数据维度转换
pred = pred.reshape(1, 25200, 6)[0]
# 模型推理后处理
pred = detect_postprocess(pred, frame.shape, [640, 640, 3], conf_thres=0.25, iou_thres=0.45)
# 绘制推理结果
res_img = draw_detect_res(frame, pred)
cvs.imshow(res_img)
# 测试结果展示停顿
time.sleep(5)
#图片裁剪,提取车辆目标区域
cut_img = extract_detect_res(frame, pred, image_name)
cvs.imshow(cut_img)
#cap.release()
#cv2.destroyAllWindows()
# 图片裁剪,裁剪区域[Ly:Ry,Lx:Rx]
# cut_img = extract_detect_res(frame, pred)
# cvs.imshow(cut_img)
# cap.release()
# cv2.destroyAllWindows()
### 读取图片
def get_image():
img_path = os.path.join("/home/Lesson5_code/adv_code/adv_results", "adv_image.png")
img_url = "https://farm1.static.flickr.com/230/524562325_fb0a11d1e1.jpg"
def _load_image():
from skimage.io import imread
return imread(img_path) / 255.
if os.path.exists(img_path):
return _load_image()
else:
import urllib
urllib.request.urlretrieve(img_url, img_path)
return _load_image()
def tensor2npimg(tensor):
return bchw2bhwc(tensor[0].cpu().numpy())
normalize = NormalizeByChannelMeanStd(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
np_img = get_image()
img = torch.tensor(bhwc2bchw(np_img))[None, :, :, :].float().to(device)
imagenet_label2classname = ImageNetClassNameLookup()
### 常规模型加载
class Model(nn.Module):
def __init__(self, l=290):
super(Model, self).__init__()
self.l = l
self.gcm = GradientConcealment()
#model = resnet18(pretrained=True)
model = mobilenet_v2(pretrained=True)
# pth_path = "/Users/rocky/Desktop/训练营/model/mobilenet_v2-b0353104.pth"
# print(f'Loading pth from {pth_path}')
# state_dict = torch.load(pth_path, map_location='cpu')
# is_strict = False
# if 'model' in state_dict.keys():
# model.load_state_dict(state_dict['model'], strict=is_strict)
# else:
# model.load_state_dict(state_dict, strict=is_strict)
normalize = NormalizeByChannelMeanStd(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
self.model = nn.Sequential(normalize, model)
def load_params(self):
pass
def forward(self, x):
#x = self.gcm(x)
#x = ResizedPaddingLayer(self.l)(x)
out = self.model(x)
return out
### 对抗攻击监测模型
class Detect_Model(nn.Module):
def __init__(self, num_classes=2):
super(Detect_Model, self).__init__()
self.num_classes = num_classes
#model = create_model('mobilenetv3_large_075', pretrained=False, num_classes=num_classes)
model = create_model('resnet50', pretrained=False, num_classes=num_classes)
# self.multi_PreProcess = multi_PreProcess()
pth_path = os.path.join("/home/Lesson5_code/model", 'track2_resnet50_ANT_best_albation1_64_checkpoint.pth')
#pth_path = os.path.join("/Users/rocky/Desktop/训练营/Lesson5_code/model/", "track2_tf_mobilenetv3_large_075_64_checkpoint.pth")
state_dict = torch.load(pth_path, map_location='cpu')
is_strict = False
if 'model' in state_dict.keys():
model.load_state_dict(state_dict['model'], strict=is_strict)
else:
model.load_state_dict(state_dict, strict=is_strict)
normalize = NormalizeByChannelMeanStd(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
# self.model = nn.Sequential(normalize, self.multi_PreProcess, model)
self.model = nn.Sequential(normalize, model)
def load_params(self):
pass
def forward(self, x):
# x = x[:,:,32:193,32:193]
# x = F.interpolate(x, size=(224,224), mode="bilinear", align_corners=True)
# x = self.multi_PreProcess.forward(x)
out = self.model(x)
if self.num_classes == 2:
out = out.softmax(1)
#return out[:,1:]
return out[:,1:]
model = Model().eval().to(device)
detect_model = Detect_Model().eval().to(device)
### 对抗攻击监测
detect_pred = detect_model(img)
print(detect_pred)
if detect_pred > 0.5:
id = 'tLyPaLG'
# 填写喵提醒中,发送的消息,这里放上前面提到的图片外链
text = "出现对抗攻击风险!!"
ts = str(time.time()) # 时间戳
type = 'json' # 返回内容格式
request_url = "http://miaotixing.com/trigger?"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.47'}
result = requests.post(request_url + "id=" + id + "&text=" + text + "&ts=" + ts + "&type=" + type,
headers=headers)
print(text)
print(result)
else:
pred = imagenet_label2classname(predict_from_logits(model(img)))
print(pred)