机器学习 决策树 随机森林
文章目录
- 参考
- 决策树指标
-
- 基尼系数
-
- 基础公式
- 公式理解
- 引入划分后的公式
- 划分后公式的理解
- 信息熵、信息增益
-
- 如何理解信息熵
- 两种指标的对比
- 总结
参考
- b站视频 【决策树、随机森林】附源码!!超级简单,同济大佬手把手带你学决策树
- 决策树模型及案例(Python)
- 决策树之基尼系数 该文章的公式理解可能不对,但提供了思路。
- 【概率论】1-4:事件的的并集(Union of Events and Statical Swindles) 并集的概率
决策树指标
决策树有多种可选的形态,那么如何确定哪种决策树是更好的呢?有两种指标可以使用:
- 基尼系数
- 信息熵、信息增益
基尼系数
基础公式
基尼系数是一种评估决策树好坏的指标。他反映了决策树对样本分类的离散情况。假设样本集合为T,分为了若干个类别,每个类别在样本集合T中占的比例为 p i p_i pi。它的计算公式如下:
gini ( T ) = 1 − ∑ p i 2 \operatorname{gini}(T)=1-\sum p_{i}^{2} gini(T)=1−∑pi2
举个例子,假设某个员工的样本集合里都是离职员工,所以该集合只有"离职员工"一个类别,其出现的频率是100%。所以该系统的基尼系数为 1 − 1 2 = 0 1-1^2=0 1−12=0,表示该系统没有混乱,或者说该系统的“纯度”很高。而如果样本中一半是离职员工,另一半是未离职员工,那么类别个数为2,每个类别出现的频率都为50%,所以其基尼系数为 1 − ( 0. 5 2 + 0. 5 2 ) = 0.5 1-(0.5^2+0.5^2)=0.5 1−(0.52+0.52)=0.5,其混乱程度很高。
公式理解
如何理解这个公式的含义?我们举个例子,假设有个贷款人员的样本集合,有贷款人员是否违约的二分类问题,1表示违约,0表示不违约。现在问:任取两个样本,它们属于同一类别的概率是多少?两个样本同属第一个类别的概率为 P 1 = p 1 2 P_1=p_1^2 P1=p12,同属第二个类别的概率为 P 2 = p 2 2 P_2=p_2^2 P2=p22。所以,两个样本同属一个类别的概率如下:
P r ( P 1 ∪ P 2 ) = P r ( P 1 ) + P r ( P 2 ) − P r ( P 1 ∩ P 2 ) = P r ( P 1 ) + P r ( P 2 ) 两个样本不可能同时都属于多个类别 = p 1 2 + p 2 2 \begin{aligned} Pr(P_1 \cup P_2)&=Pr(P_1)+Pr(P_2)-Pr(P_1 \cap P_2) \\ &=Pr(P_1)+Pr(P_2) \qquad \text{两个样本不可能同时都属于多个类别} \\ &=p_1^2+p_2^2 \end{aligned} Pr(P1∪P2)=Pr(P1)+Pr(P2)−Pr(P1∩P2)=Pr(P1)+Pr(P2)两个样本不可能同时都属于多个类别=p12+p22
所以,两个样本不属于同一类别的概率为 1 − P r ( P 1 ∪ P 2 ) = 1 − p 1 2 − p 2 2 = g i n i ( T ) 1-Pr(P_1 \cup P_2)=1-p_1^2-p_2^2=gini(T) 1−Pr(P1∪P2)=1−p12−p22=gini(T)。在二分类问题中,基尼系数的含义就是随机采样的两个样本不属于同一类别的概率。
该说法在多分类问题中一样成立。参考【概率论】1-4:事件的的并集(Union of Events and Statical Swindles)给出的公式:

图中的并集元素项都等于0,所以任取两个样本,都属于同一类别的概率为 Pr ( ⋃ i = 1 n A i ) = ∑ i = 1 n Pr ( A i ) = ∑ i = 1 n p i 2 \operatorname{Pr}\left(\bigcup_{\mathrm{i}=1}^{\mathrm{n}} \mathrm{A}_{\mathrm{i}}\right)=\sum_{\mathrm{i}=1}^{\mathrm{n}} \operatorname{Pr}\left(\mathrm{A}_{\mathrm{i}}\right)=\sum_{\mathrm{i}=1}^{\mathrm{n}}p_i^2 Pr(⋃i=1nAi)=∑i=1nPr(Ai)=∑i=1npi2。所以任取两个样本,不属于同一类别的概率为 1 − ∑ i = 1 n p i 2 1-\sum_{\mathrm{i}=1}^{\mathrm{n}}p_i^2 1−∑i=1npi2,该说法得证。在多分类问题中,基尼系数的含义也是同样的。
引入划分后的公式
当引入某个用于划分样本空间的条件(如“满意度<5”)时,分类后的基尼系数公式如下,其中S1、S2为划分后的两类各自的样本量, g i n i ( T 1 ) gini(T_1) gini(T1)、 g i n i ( T 2 ) gini(T_2) gini(T2)为两类各自的基尼系数。
gini ( T ) = S 1 S 1 + S 2 gini ( T 1 ) + S 2 S 1 + S 2 gini ( T 2 ) \operatorname{gini}(T)=\frac{S_{1}}{S_{1}+S_{2}} \operatorname{gini}\left(T_{1}\right)+\frac{S_{2}}{S_{1}+S_{2}} \operatorname{gini}\left(T_{2}\right) gini(T)=S1+S2S1gini(T1)+S1+S2S2gini(T2)
举个例子,一个初始样本中有1000个员工,其中已知有400人离职,600人不离职,划分前该系统的基尼系数为 1 − ( 0. 4 2 + 0. 6 2 ) = 0.48 1-(0.4^2+0.6^2)=0.48 1−(0.42+0.62)=0.48。
下面采用两种方式决定根节点:一是根据“满意度<5”进行分类;二是根据“收入<10000元”进行分类。
划分方式1:以“满意度<5”为根节点进行划分,如下图所示,1000个员工中,200个人是满意度<5的,另外有800个人满意度>=5。计算过程如下。
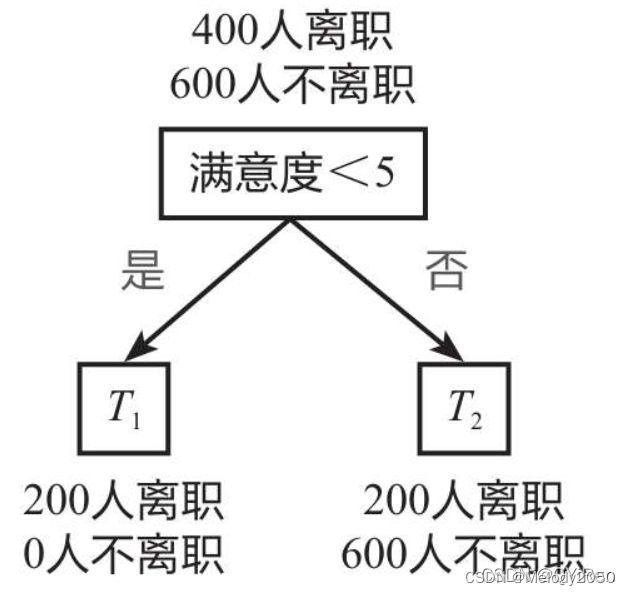
- T1的基尼系数: g i n i ( T 1 ) = 1 − ( 1 2 + 0 2 ) = 0 gini(T_1)=1-(1^2+0^2)=0 gini(T1)=1−(12+02)=0
- T2的基尼系数: g i n i ( T 2 ) = 1 − ( 0.2 5 2 + 0.7 5 2 ) = 0.375 gini(T_2)=1-(0.25^2+0.75^2)=0.375 gini(T2)=1−(0.252+0.752)=0.375
- 综上,划分后的基尼系数就是
gini ( T ) = 200 1000 × 0 + 800 1000 × 0.375 = 0.3 \begin{aligned} \operatorname{gini}(T)&= \frac{200}{1000} \times 0+ \frac{800}{1000} \times 0.375= 0.3 \end{aligned} gini(T)=1000200×0+1000800×0.375=0.3
划分方式2:以“收入<10000元”为根节点进行划分,如下图所示,1000个员工中,有400个人收入小于10000元,另外600人收入>=10000元计算过程如下。
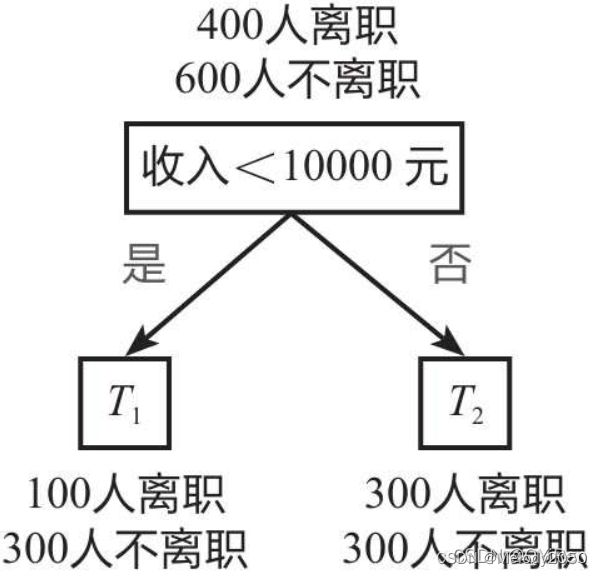
T1的基尼系数: g i n i ( T 1 ) = 1 − ( 0.2 5 2 + 0.7 5 2 ) = 0.375 gini(T1)=1-(0.25^2+0.75^2)=0.375 gini(T1)=1−(0.252+0.752)=0.375
T2的基尼系数: g i n i ( T 2 ) = 1 − ( 0. 5 2 + 0. 5 2 ) = 0.5 gini(T2)=1-(0.5^2+0.5^2)=0.5 gini(T2)=1−(0.52+0.52)=0.5
- 综上,划分后的基尼系数就是
gini ( T ) = 400 1000 × 0.375 + 600 1000 × 0.5 = 0.45 \begin{aligned} \operatorname{gini}(T)&= \frac{400}{1000} \times 0.375+ \frac{600}{1000} \times 0.5= 0.45 \end{aligned} gini(T)=1000400×0.375+1000600×0.5=0.45
可以看到,划分前的基尼系数为0.48,以“满意度<5”为根节点进行划分后的基尼系数为0.3,而以“收入<10000元”为根节点进行划分后的基尼系数为0.45。基尼系数越低表示系统的混乱程度越低(纯度越高),区分度越高,越适合用于分类预测,因此这里选择“满意度<5”作为根节点。
划分后公式的理解
如何理解划分后的基尼系数公式?在划分前,样本空间是全集。划分将决策树的分为了若干个树节点,每个树节点相当于一个样本空间子集。所以公式中将各个划分样本计算基尼系数后,按权重相加的方式,相当于计算每个划分样本空间基尼系数的加权和。
信息熵、信息增益
这里建议阅读原文决策树模型及案例(Python),对某个样本空间X计算信息熵的公式为:
H ( X ) = − ∑ p i log 2 ( p i ) ( i = 1 , 2 … … n ) H(X)=-\sum p_{i} \log _{2}\left(p_{i}\right) \quad\left(i=1,2 \ldots \ldots{ }{\text n}\right) H(X)=−∑pilog2(pi)(i=1,2……n)
进行某种变量A划分后(比如“满意度<5”),信息熵的计算公式如下。则根据变量A划分后的信息熵又称为条件熵。
H A ( X ) = S 1 S 1 + S 2 H ( X 1 ) + S 2 S 1 + S 2 H ( X 2 ) H_{A}(X)=\frac{S_{1}}{S_{1}+S_{2}} H\left(X_{1}\right)+\frac{S_{2}}{S_{1}+S_{2}} H\left(X_{2}\right) HA(X)=S1+S2S1H(X1)+S1+S2S2H(X2)
什么是信息增益?为了衡量不同划分方式降低信息熵的效果,还需要计算分类后信息熵的减少值(原系统的信息熵与分类后系统的信息熵之差),该减少值称为熵增益或信息增益,其值越大,说明分类后的系统混乱程度越低,即分类越准确。
假设某样本的初始信息熵为 H ( X ) = 0.97 H(X)=0.97 H(X)=0.97,按照某划分后,信息熵为 H A ( X ) = 0.65 H_A(X)=0.65 HA(X)=0.65
如何理解信息熵
两种指标的对比
基尼系数涉及平方运算,而信息熵涉及相对复杂的对数函数运算,因此,目前决策树模型默认使用基尼系数作为建树依据,运算速度会较快。
总结
其实算法面试基本不会考吧?可是反正我也失业了,就随着性子学知识吧。这辈子就这样了。