【论文简述】CVP-MVSNet:Cost Volume Pyramid Based Depth Inference for Multi-View Stereo(CVPR 2020)
一、论文简述
1. 第一作者:Jiayu Yang
2. 发表年份:2020
3. 发表期刊:CVPR oral
4. 关键词:MVS、深度学习、代价体金字塔、残差深度图
5. 探索动机:MVSNet内存消耗立方级别的,R-MVSNet减少了内存但需要更多时间,Point-MVSNet运行时间和迭代次数成正比。现在基于学习的网络精度很好,但是太慢了。
Yao et al. propose MVSNet to infer a depth map for each view. An essential step in is to build a cost volume based on a plane sweep process followed by multiscale 3D CNNs for regularization. While effective in depth inference accuracy, its memory requirement is cubic to the image resolution. To allow handling high resolution images, they then adopt a recurrent cost volume regularization process. However, the reduction in memory requirements involves a longer run-time.
In order to achieve a computationally efficient network, Chen et al.work on 3D point clouds to iteratively predict the depth residual along visual rays using edge convolutions operating on the knearest neighbors of each 3D point.While this approach is efficient, its run-time increases almost linearly with the number of iteration levels.写的很详细。
6. 工作目标:是否提高精度的同时,可以提高网络的效率?
7. 核心思想:提出了一个基于代价体、小型的和计算效率高的MVS深度推断网络;在详细分析深度残差搜索范围与图像分辨率之间关系的基础上,以由粗到细的方式构建代价体金字塔;框架可以用更少的内存处理更高分辨率的图像,比目前最先进的框架(如Point-MVSNet)快6倍,并在基准数据集上实现了更好的精度。
8. 实验结果:在基准数据集上,该模型具有与最先进的方法相似的性能,但是速度快6倍。
9. 论文下载:
Cost Volume Pyramid Based Depth Inference for Multi-View Stereo (thecvf.com)
http://https: //github.com/JiayuYANG/CVP-MVSNet
二、实现过程
1. CVP-MVSNet概述
由粗到细(coarse-to-fine)构建代价体金字塔。首先构建不同分辨率的L+1层图像金字塔,接着用最小分辨率层的N张图像按照MVSNet的方式构建代价体,推断深度图DL+1,并上采样得到L层的初始深度图DL;以初始深度图DL为基础、结合L层的N张图像,通过重投影的方式构建一个部分代价体(partial cost volumes),并依次推断出初始深度图DL上各像素的残差深度(residual depth,即相对于初始深度的Δd),相加之后得到当前L层的最终深度图,不断重复迭代至推断出最终第0层即原始尺寸的深度图。
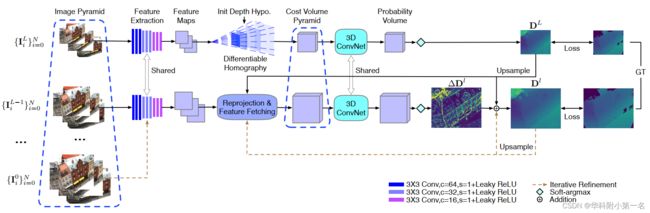
2. 特征金字塔
特征提取管道机制包括两个步骤,首先对于每个输入图像,构建L + 1层图像金字塔。其次,利用9个卷积层组成特征提取网络(参数共享)获取特征图,每一层后面都有Leaky-ReLU激活函数(代替一般的 Conv + BN + ReLu结构)。每层的输出通道数为16,第l层的宽高尺寸为[W/2l,H/2i]。
可学习特征表示的意义:As raw images vary with illumination changes, we adopt learnable features, which has been demonstrated to be crucial step for extracting dense feature correspondences.
3. 代价体金字塔
动机:Common approaches usually build a single cost volume at a fixed resolution, which incurs in large memory requirements and thus, limits the use of high-resolution images.
解决思路:we propose to build a cost volume pyramid, a process that iteratively estimates and refines depth maps to achieve high resolution depth inference.
3.1. 推断粗略深度图的代价体(第L层)
构建最顶层也就是分辨率最小一层的代价体,方式和MVSnet一模一样,深度假设均匀采样。这一部分对于代价体构建描述的很详细,建议反复阅读。
深度定义:A sampled depth d = dmin + m(dmax - dmin)/M, m ∈ {0, 1, 2, · · · , M-1} represents a plane where its normal n0 is the principal axis of the reference camera.
方差意义:This metric encourages that the correct depth for each pixel has the smallest feature variance, which corresponds to the photometric consistency constraint.
3.2. 推断多尺度深度残差的代价体(第L层-第0层)
首先在上节中我们得到了第L+1层的深度图DL+1,通过双三次插值将其上采样得到第L+1层的初始深度图DL+1↑,然后,构建部分代价体,对定义为∆Dl的残差深度图进行回归,得到第l层的改进后的深度图Dl = Dl+1↑ +∆Dl。随后重复该步骤至第0层得到最终深度图。
Our motivation is that depth displacements for neighboring pixels are correlated which indicates that regular multi-scale 3D convolution would provide useful contextual information for depth residual estimation. We therefore arrange the depth displacement hypotheses in a regular 3D space and compute the cost volume as follows。
对于上采样后的初始深度图DL+1 ↑,我们定义第L层图像上像素点p(u,v)深度为dp=DL+1 ↑(u,v)。下图是该操作的两个步骤,左边为重投影操作,右边为提取特征和构建部分代价体。

左边:重投影过程
在L层,依据当前点p的初始深度dp找出对应3D点(绿色),加、减一个值作为最远和最近的、可能真实3D点(紫色、红色),残差搜索深度sp就是指紫色点和红色点之间的距离(该范围及间隔选定方法将在下一节详细解释),残差深度平面就是在中间划分M个可能的深度值平面,此时残差深度平面的距离间隔为Δdp=sp/M,M个可能3D点的深度值为(DL+1 ↑(u,v)+mΔdp),其中m∈{-M/2, … ,M/2-1}。也就是以初始深度为起始点,初始深度加、减sp/2为可能的3D点最远、最近深度。
此时对于当前参考视图下的像素点p,我们可以将其M个不同深度的可能3D点的按照以下公式投影,在一张源视图下得到M个深度对应的特征,如图上设置的紫色、绿色、红色三个深度点在各个源视图下都对应了一个特征。

右边:构建局部代价体
将这些不同深度的可能3D点投影后的特征做方差,并将方差值作为像素点p在该深度的代价;由于有M个假设深度,共HxW个像素点,通过以下公式,便得到[H/2l×W/2l×M×F]的部分代价体,回归即可的到残差深度Δd。
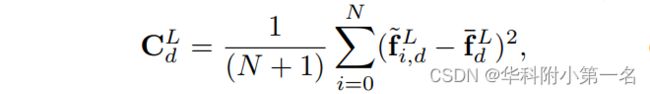
这里和MVSNet构建代价体都使用方差法,MVSNet是通过假设一系列深度值,将各源视图转化到参考图前的平行视锥体,也就是参考视图的各像素坐标通过单应矩阵H变换到源视图下对应的像素坐标从而取其值,而这里是通过假设真实3D点位置来找到各源视图上该点的特征。本质上是一样的,只是一个从源图像投到参考图像,一个从参考图像投到源图像。
参考:https://blog.csdn.net/qq_41794040/article/details/127897080
4. 深度图推断
4.1. 代价体金字塔的深度采样
我们观察到虚拟深度平面的深度采样与图像分辨率有关。如图所示,不需要对深度面进行密集采样,因为这些采样的3D点在图像中的投影距离太近,无法为深度推断提供额外的信息。实验中,为了确定虚拟平面的数量,只计算图像中对应0.5像素距离的平均深度采样间隔。

为了确定每个像素当前深度估计附近的深度残差局部搜索范围,我们首先将其3D点投影到源视图中,沿着极线在两个方向上找到距离其投影两个像素的点(见 2 pixel length),然后将这两个点反向投影到3D射线中。这两条射线与参考视图中的可视射线的交点决定了当前层的深度的搜索范围。

4.2. 深度图估计
与MVSNet一样,把代价体输入3D卷积网络中聚合上下文信息并输出概率体,由概率体通过soft-argmax求期望得到深度图。首先对PL=0应用soft-argmax来获得粗深度图:
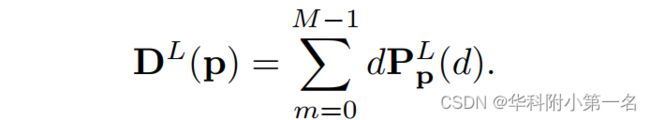
然后,利用soft-argmax迭代改进得到的深度图PL,得到较高分辨率下的深度残差。设rp = m·∆dp为深度残差假设。我们计算下一层的更新深度为:
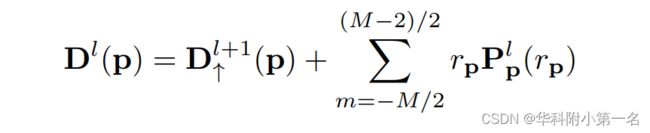
5. 损失函数
对每层估计深度图与真实深度图求l1损失求和作为loss:

其中Ω是带有真实度量的有效像素集。
6. 实验
6.1. 数据集
DTU Dataset
真实深度图大小:To train our model, we generate a 160 × 128 depth map for each view by using the method provided by MVSNet.
Tanks and Temples Benchmark:intermediate set
6.2. 实现
训练:使用DTU数据集训练CVP-MVSNet。与Mvsnet、RMvsnet以高分辨率图像作为输入,但估计的深度图尺寸较小不同,我们的方法生成与输入图像相同大小的深度图。为了进行训练,我们通过将高分辨率图像下采样到一个较小的尺寸为160×128的图像来匹配真实深度图。然后,我们建立了图像和地面的两层真实深度金字塔。为了构建代价体金字塔,我们在最粗(第2层)的整个深度范围内均匀采样M = 48个深度假设。然后,每个像素下一层有M = 8个深度残差假设,用于深度估计的改进。输入视图数N = 3,通过PyTorch实现,Adam作为优化器,batch size为16,在1张NVIDIA TITAN RTX显卡训练,迭代27个epoch。
指标:accuracy, completeness and overall score
Accuracy is measured as the distance from estimated point clouds to the ground truth ones in millimeter and completeness is defined as the distance from ground truth point clouds to the estimated ones [1]. The overall score is the average of accuracy and completeness.
评估:设置深度采样次数,最粗深度估计M = 96,对于深度残差推理层M = 8。输入视图数N = 5,采用相同深度图融合方法得到点云D = 192。用不同大小的图像评估我们的模型,并相应地设置金字塔水平,以在最粗的水平上保持与输入图像(80 × 64)相似的大小。例如,输入尺寸为1600 × 1184时,金字塔有5层,输入尺寸为800 × 576和640 × 480时,金字塔有4层。
6.3. 结果
DTU数据集重建质量:SOTA

时间及内存:精度相似,但是又快又小

点云及法线图:上面一行显示点云,下面一行显示与橙色矩形对应的法线图。在法线图中看到,我们的结果在边缘区域获得更多高频细节的同时,在表面上更平滑。

泛化性:SOTA

6.4. 消融实验
训练金字塔层级。首先分析金字塔层数对重建质量的影响。为此,我们对图像进行下采样,以形成具有四个不同层次的金字塔。分析结果汇总在表中。如图所示,2层金字塔是最好的。随着金字塔等级的增加,最粗等级的图像分辨率降低。对于超过2层的情况,这个分辨率太小,无法生成一个好的初始深度图。
评估像素间隔设置。深度采样是由源视图中相应的像素偏移量决定的,因此设置合适的像素间隔很重要。表中总结了在评估期间从0.25像素到2像素对应的深度范围更改间隔的效果。如图所示,当间隔过小(0.25像素)或过大(2像素)时,性能会下降。

这篇论文在每节开始前和结束后都有或多或少的总述或总结,文字表述很结构化。