我参加 NVIDIA Sky Hackathon——有关ASR模型相关简述
2022年10月29日 团队报名了第七届NVIDIA SKy Hackathon大赛并于2022年11月28日成功完赛
本次系列比赛为团队第二次参加,在有了一定经验的情况下,本次团队也取得了一定的成绩(大赛第四名),而本人主要在团队内负责的是ASR相关模型的训练及调参,故本篇文章主要为ASR模型的相关介绍以及团队在训练过程中遇到的比较经典的问题及解决方案。
目录
(一)大赛简介
(二)相关环境配置(初始环境及ASR相关环境)
(三)ASR模型
3.1 数据集
3.1.1数据搜集
3.1.2 数据标注
3.2 一些比较经典的报错及解决方案
3.2.1 RuntimeError: CUDA out of memory.
3.2.2 在已安装了CUDA的情况下,运行代码时检测CUDA 为False
(四)结语
(一)大赛简介
本次参赛题目:
挑战智能语音垃圾分类任务
题目背景:
垃圾是世界范围内日益严重的环境问题,实行垃圾分类,关系节约使用资源,也是社会文明水平的一个重要体现。NVIDIA正在努力加强技术研究,致力于开发创新计算解决方案,同时鼓励开发者们利用NVIDIA 各种AI开发工具,激发创造力,科技赋能,给垃圾分类注入“智慧力量”。
大赛目的:
本次Hackathon活动以“挑战智能语音垃圾分类任务”为主题。赛事涵盖:语音识别、垃圾检测及用户接口的web页面实现等。并将所有功能部署到 jetson NX上
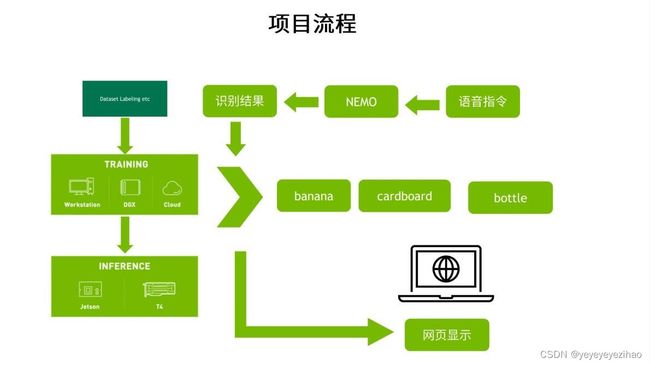
图1-1 本次大赛项目流程 注:图片来源NVIDIA针对于本次比赛的培训ppt
大赛内容:
- 语音识别:通过NEMO将语音结果转化为文字
- 图像识别:通过文字对图片进行识别(banana、cardboard、bottle)
- 网页显示:将语音识别结果、图像识别结果显示在制作的网页上
(二)相关环境配置(初始环境及ASR相关环境)
本次NVIDIA还是很贴心的为参赛人员准备了配置环境的知识图谱,便于初学或第一次参赛的同学安装配置本次大赛所需的环境。
接下来将应用本次NVIDIA Sky Hackathon的知识图谱相关内容便于读者参考阅读:
A1. 获取NGC秘钥
- 1.创建NGC账号:这个帐号与NVIDIA Developer账号是独立的,需要单独申请。如果已经有NGC帐号的,请跳过下面申请的流程,直接到第2步“创建NGC密钥”
- 登录 https://ngc.nvidia.com 会直接出现 CATALOG画面
- 请点击下图右上角 ”Welcome Guest”,然后点选下方 ”Sing in/Sing Up”

3.进入后点选 ”NVIDIA Account” 旁边的”Continue”,就会进入下图右的“登陆”或“创建一个账户”的画面,然后按照标准开帐户的流程执行就可以。

- 2.获取NGC密钥:
- 登陆NGC,点选右上角用户名,在下拉菜单中选择 ”setup” 选项
2.进入下面选项后,点击 ”Get API Key”

在下面点击右上角”Generate API KEY”会跳出“确认”,点击”confirm”就可以

生成的这组密钥在整个训练过程以及最后推理时都需要用到,非常关键。由于密钥只有在创建时候能看到内容,日后无法在NGC独立查询,请自行复制做好记录。
在https://docs.nvidia.com/ngc/ngc-overview/index.html有NGC更完整说明。
A2. 安装NVIDIA驱动460以上版本
| $ $ $ $ |
sudo apt-get install software-properties-common sudo add-apt-repository ppa:graphics-drivers/ppa sudo apt-get install nvidia-driver-460 sudo reboot # 重启之后才会生效,重启后执行 nvidia-smi 检查驱动 |
A3. 安装 docker与nvidia-docker2
- 安装docker
| $ $ $ $ $ $ |
sudo apt-get install -y ca-certificates curl gnupg lsb-release curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null sudo apt-get update sudo apt-get install -y docker-ce docker-ce-cli containerd.io # 测试安装 sudo docker run hello-world |
- 安装nvidia-docker2
| $ $ $ $ $ $ |
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - distribution=$(. /etc/os-release;echo $ID$VERSION_ID) curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list sudo apt-get update && sudo apt-get install -y nvidia-docker2 sudo systemctl restart docker # 测试安装 sudo docker run --rm --gpus all nvidia/cuda:11.0.3-base-ubuntu20.04 nvidia-smi |
如果出现以下信息,表示docker与nvidia-docker2都安装完成:
- 登录NGC:只要登录一次就行
| $ |
sudo docker login -u '$oauthtoken' --password-stdin nvcr.io <<< '申请的密钥' |

A4. 安装 MiniConda3与Jupyter开发环境
- 安装 MiniConda
| $ $ $ $ $ |
# 用国内清华源 export DL_SITE=https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda # 用原厂的源 export DL_SITE=https://repo.anaconda.com/miniconda # 下载安装包 wget -c $DL_SITE/Miniconda3-py38_4.10.3-Linux-x86_64.sh # 执行安装,全部按照预设路径与”yes”选项 bash Miniconda3-py38_4.10.3-Linux-x86_64.sh # 启动 Conda source ~/.bashrc |
- 安装 Jupyter Lab
| $ $ $ |
pip install jupyter jupyterlab # 设置登录密码 export PW=’自行提供‘ python3 -c "from notebook.auth.security import set_password; set_password('$PW','$HOME/.jupyter/jupyter_notebook_config.json')" |
A5. 安装NeMo 1.4.0
(1)安装Pytorch
通过pip安装GPU版本Pytorch参考链接Previous PyTorch Versions | PyTorch
例如Pytorch1.12.1版本则安装指令如下:
$ pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
(2)安装NeMo:
| $ $ $ $ $ $ $ |
sudo apt-get update && sudo apt-get install -y libsndfile1 ffmpeg pip install Cython pip install --user pytest-runner pip install rosa numpy==1.19.4 pip install torchmetrics==0.6.0 pip install nemo_toolkit[all]==1.4.0 pip install ASR-metrics |
(3)检测NeMo
| $ |
python >>>import nemo >>>import nemo.collections.asr as nemo_asr |
若没有报错表示安装成功(warning不用理会)
(三)ASR模型
3.1 数据集
3.1.1数据搜集
针对于本次大赛的ASR数据集部分,本次大赛需要识别3类物品(果皮、纸箱、瓶子),故在数据集方面,团队至少需要这3类物品排列组合合计7类语音(“请检测出果皮”、“请检测出纸箱”、“请检测出瓶子”、“请检测出瓶子和纸箱”、“请检测出果皮和纸箱”、“请检测出瓶子和果皮”、“请检测出瓶子纸箱和果皮”)。团队成员共计录制了1523条训练数据70条测试数据,其中包含若干男性和女性的声音,年龄段分布在10-30岁,单声道保存为wav格式的普通话,每条语音均对前后静音进行裁剪。数据集标签json文件以pycharm方式打开展示效果如下图(图3-1、图3-2)所示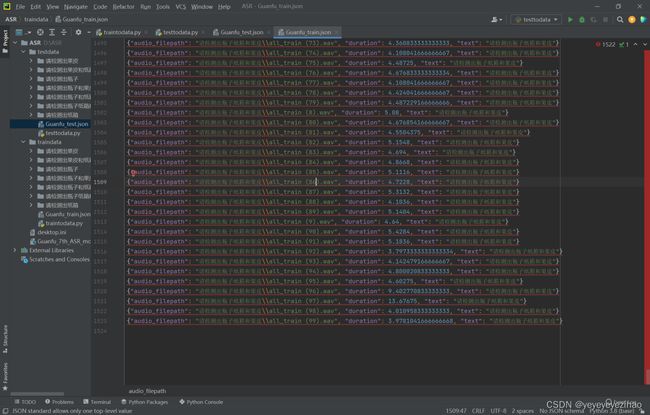
图3-1 训练集数据一览
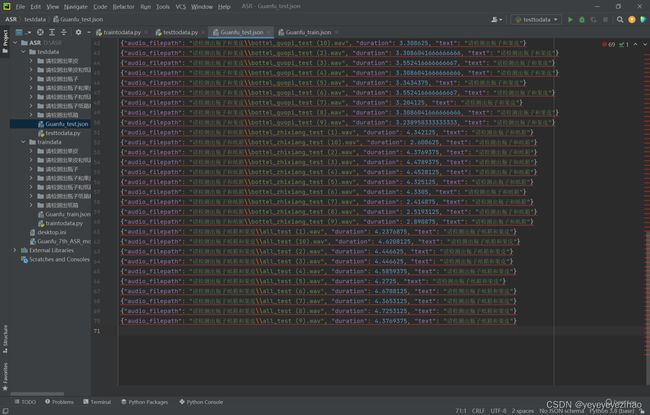
图3-2 测试集数据一览
在采集语音制作数据集方面,以下提供两种采集方法:
1.第一种方法为NVIDIA官方提供的方法,使用录音软件Audacity录制:
录制语音文件,文件类型需统一转换为wav格式,采样率建议在44100HZ 、单声道。
通过录音软件Audacity录制:Ubuntu系统安装=>sudo apt install audacity
windows系统可用此网址下载安装:https://www.onlinedown.net/soft/46359.htm

针对这种方法,我们团队对于这个录音软件操作不太熟悉,在一个人需要录制多条多次语句的情况下,我们团队觉得这个软件使用起来相对比较麻烦,于是就有了第二种方法,仅供参考~
2. 第二种方法为,直接使用手机自带的录音机功能。该方法在录制时较为方便 ,在录制完成后,可批量传输至电脑上。
但是,这里存在一个问题!
由于数据集需求必须为wav格式,采样率建议在44100HZ 、单声道。而录音机录制的音频文件一般都是MP3格式且为多声道,所以这里就需要用到一个很关键的软件。
格式工厂
格式工厂的下载方式在本文不具体详述在任意网站上面下载即可
图3-3 格式工厂的打开界面
文件格式的转换即将需要转换格式的文件批量拖入界面空白处即可,拖入后设置相关参数如图3-4 图3-5 图3-6所示
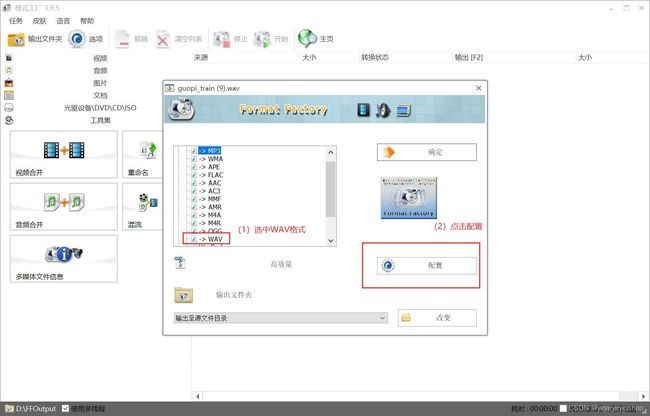
图3-4
 图3-5
图3-5
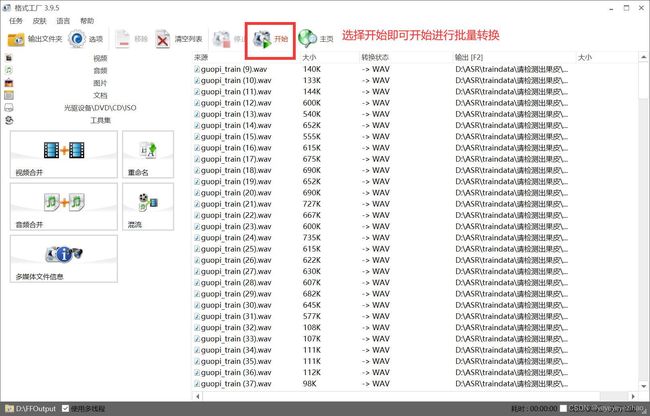 图3-6
图3-6
以上两种方法均可获得合格数据用于数据标注。
3.1.2 数据标注
由于本次数据集所需数量庞大,故以人力打标签来完成所有语音数据集标注不太现实,故团队通过脚本来实现批量数据标记。脚本内容如下:
import os
import librosa
def get_allfile(path): # 获取所有文件
all_file = []
for f in os.listdir(path): # listdir返回文件中所有目录
f_name = os.path.join(path, f)
all_file.append(f_name)
return all_file
all_file = get_allfile("请检测出××××××")#事先对语音数据集进行统一归类 找到所需文件夹名称即可
print(all_file)
count = 0
import json
with open("test.json",mode="a+",encoding="utf-8") as f:
for i in all_file:
contrast_dict={}
duration=librosa.get_duration(filename=i)#通过调用librosa库来确定语音数据时长
contrast_dict["audio_filepath"] = all_file[count]
contrast_dict["duration"] = duration
contrast_dict["text"] = "请检测出××××××"#需要打的标签的内容
json.dump(contrast_dict,f,ensure_ascii=False)
f.write("\n")
print(duration)
count += 1通过以上方法,即可完成ASR的数据搜集以及数据标注等工作,完成后将生成好的数据清单在代码中引用,即可开始对自己的模型进行训练了~
3.2 一些比较经典的报错及解决方案
3.2.1 RuntimeError: CUDA out of memory.
这个报错应该算得上是一个比较经典的报错,在第一次参加比赛的同学应该大部分都会遇到这个错误。要解决这个错误也十分的简单,只需要在 quartznet_15x5_zh.yaml 中调小batch_size,关于batch_size的调整一般设置为4的倍数。如下图3-7:

图3-7
以本团队为例子,团队训练集数量为1523条,显存为10G,当调整batch_size为8时,占用显存5G左右(如图3-8),可参考来进行调整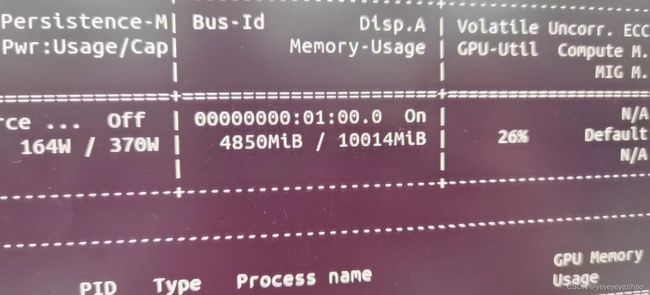
图3-8
3.2.2 在已安装了CUDA的情况下,运行代码时检测CUDA 为False
已经安装了CUDA的条件下在运行代码 torch.cuda.is_avaliable()时输出结果为False,话不多说,上图看看(图3-9)
图3-9
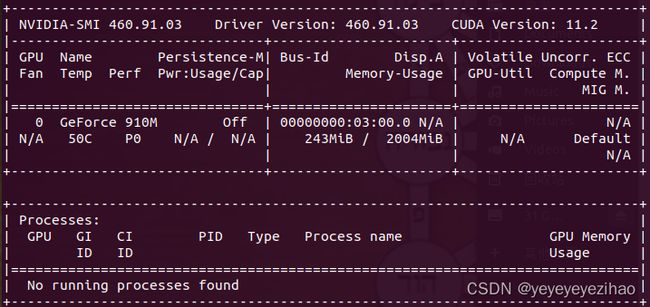
此时,我们需要在终端输入 nvidia-smi 查看情况,在我输入指令后,情况如下(图3-10)

图3-10
如果出现了上述情况,那就说明是显卡驱动出现了问题
显卡驱动出现了问题,一般重启电脑,系统就会为我们自行修复。如果修复不成功的话,尝试选择最后一次正确配置选项,看看是否可以正常启动系统。如果还是不能成功修复的话,可能就需要去电脑城问问师傅了。
(四)结语
NVIDIA的Sky Hackathon系列比赛在其中其实可以学到很多有用的知识,对于作者本人来说,NVIDIA的系列比赛是完全区别于学校内的平日学习的,学校课程一般是由低阶到高阶,从最底层,最基础的概念开始讲解,而Hackathon系列比赛则是一来就开始进行相对工程化的操作,节奏也是相对较快,无论是从配置环境到训练模型,模型在终端设备的部署,都是在学校很少接触到的知识,在第一次参加比赛时,作者几乎在每一个步骤上都踩了坑,但是对各方面的锻炼也是巨大的,对于本科的萌新来说,这种参加比赛的机会也希望大家可以把握住~
本文为第一次尝试写作,如有遗漏或错误之处,烦请指出,感谢大家的理解。