arXiv 最新速递| 异配图上的GNN该怎么设计?
作者:Mengying Jiang ;Guizhong Liu;Yuanchao Su ;Xinliang Wu
 image-20210614235729928
image-20210614235729928
论文标题:Structure Learning Graph Convolutional Networks for Graphs under Heterophily
论文地址:https://arxiv.org/abs/2105.13795
欢迎关注小编知乎:图子
传统的GNN往往聚合来自邻居节点的特征信息,但是在同配性较低的图上,相似的节点可能在图上距离很远。这篇论文是近几日最新发表在arXiv上,提供了另外一种思路,通过改变异配性高的图的拓扑结构,根据节点的相似度生成一个新的邻接矩阵,帮助 GNN 从同一类节点中获取信息。
异质性和异配性区别:
异质性(Heterogeneous),强调节点类型和边类型的多样性。同配性,强调节点和边的类型单一。
异配性(Heterophily),强调节点和其邻居的相似度较低(比如标签差异较大)。同配性,强调节点与其邻居特性较为吻合(向量表示或者标签较为接近)。
0. Abstract
GNN 的性能通常会受到图结构的限制,现实世界的图数据往往是有噪声或不完整的。论文提出了一种结构学习图卷积网(SLGCNs),能够两个方面来缓解这个问题,并应用于节点分类。1)针对节点特征,论文设计了一种高效的带锚点的谱聚类方法,无论节点之间距离多远,都能够有效地聚合所有相似节点的特征表示。2)由于原始邻接矩阵在同配性低的图中为GCN的聚合提供误导信息,因此论文根据节点之间的相似性生成了一个重连接的邻接矩阵,并为下游预测任务进行了优化。重连接的邻接矩阵和原始邻接矩阵都被应用于SLGCNs,以聚合邻居节点的特征表示。SLGCNs 可以应用于具有不同程度同配性的图。在基准数据集上的实验结果表明,SLGCNs的性能优于最先进的GNN模型。
1. Introduction
1)GCN的局限性
GCN通过简单地将所有一跳邻居的归一化特征表示相加来更新节点的特征,这限制了GCN在图结构数据上的表示能力,即GCN无法捕获图中的长距离依赖关系,这一弱点在具有异配性或低/中度同配性的图中会被放大。
2)同配性(Homophily)
同配性是许多现实世界图的一个非常重要的原则,即链接的节点倾向于有类似的特征,属于同一类的节点有类似的特征。例如,论文更有可能引用同一研究领域的论文,而朋友往往有类似的年龄或政治信仰。然而,现实世界中也有关于 "异性相吸 "的设定,导致图的同配性很低,即距离近的节点通常来自不同的类别,并且具有不同的特征。例如,在交友网站中,大多数人倾向于与异性聊。大多数现有的GNN都假定有图很强的同配性,包括GCN,在高异配性下的图上泛化表现很差,甚至比只依靠节点特征进行分类的MLP还要差。
3)现有的解决办法
利用多层GCN来聚集来自远处节点的特征,而这种策略可能会导致过平滑和过拟合。最近有一些新的方法,如GEOM-GCN,H2GCN等,虽然GEOM-GCN提高了GCN的表示学习性能,但在低同配性的图上的节点分类的性能往往不佳。H2GCN改善了GCN的分类性能,但它只能聚合邻近节点的信息,导致缺乏捕捉距离较远但相似节点特征的能力。
4)SLGCNs
本文提出了一种新的GNN方法来解决上述问题,称为结构学习图卷积网络(SLGCNs)。按照谱聚类(SC)方法,图的节点被映射到一个新的特征空间,原始图中连接紧密或具有相似特征的节点在新的特征空间中通常是邻近的。如果采用SC来处理图结构数据,节点可以从相似的节点中聚集特征,从而使GCN能够捕获长距离的依赖关系。
然而,SC 的计算复杂度对于大规模图来说是非常高的,因此论文设计了一种高效的带锚点的谱聚类(ESC- ANCH)方法来有效地提取SC特征。然后,将提取的SC特征与原始节点特征相结合作为强化的特征(EF),并利用EF来训练GNN。
5)SLGCNs的贡献
将谱聚类集成到GNN中,用于捕捉图上的长距离依赖关系,并提出了ESC-ANCH算法,以便在图结构数据上有效地实现谱聚
SLGCNs可以学习重连接的邻接矩阵,这不仅与节点的相似性相关,更利于下游的预测任务;
SLGCNs分别从节点特征和边的方面提出了处理异配性的改进方案,并将两种改进结合起来,使之相互补充。
2. Related Work
2.1. Spectral Clustering
谱聚类(SC) 是一种从图论演变而来的算法,利用权重图对数据集进行分割。假设 代表一个数据集。聚类的任务是将 划分为 个簇。聚类对齐矩阵表示为 ,其中 是 的簇对齐向量。从另一个角度来看, 可以被视为 在 维特征空间中的特征表示。
亲和矩阵
令 表示一个无向的带权图, 表示节点的集合, 表示亲和矩阵, 是 中节点的数目,矩阵中的每一个元素 表示图中一对节点的相似度。最常见的构建 的方法是全连接方式。 计算方式:
和 表示两节点特征, 可以控制节点之间相似性的程度。拉普拉斯矩阵 , 是度矩阵,即对角阵。
谱聚类的目标函数:
是簇指示矩阵,谱聚类目标函数重写为:
目标函数的最优解 是由 的 个最大特征值所对应的特征向量构成。
不仅可以看作是节点聚类的结果,也可以看作是节点的新特征矩阵,其中的节点有 个特征元素。即通过谱聚类我们可以得到一个新的维度更低的特征矩阵。
2.2. GCN
在GCN中,节点特征的更新采用了对一跳邻居特征的各向同性的平均化操作。设 是第 层GCN中节点 的特征表示,有:
其中 代表节点i的一跳邻居集合, 是权重矩阵,ReLU是激活函数。注意, 是第i个节点的入度。此外,2层GCN的前向模型可以表示为:
是节点的特征矩阵,也是第一层GCN的输入。
3. SLGCN 方法
本文提出结构学习图卷积网络(SLGCNs),用于图结构数据的节点分类。SLGCNs 的流程如图1所示。整体思路就是结合谱聚类和GCN,捕获距离较远但是特征相似的节点之间的依赖关系。
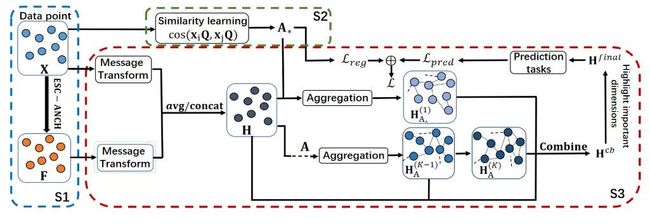 fig1
fig1
它由三个阶段组成。(S1)带锚的高效谱聚类,采用ESC-ANCH生成SC特征 。(S2)重连接图,根据节点之间的相似性构建一个重连接的图,这个重连接的图可以随着SLGCNs模型的训练而逐渐优化。(S3)结构学习图卷积网络,将原始特征 和SC特征 合并为增强特征 ,并分别使用重新连接的邻接矩阵原始邻接矩阵对 进行特征聚合。将聚合的结果和 合并为 ,并使用权重向量来突出 的重要维度,以使SLGCNs适应不同程度的同配性的图。
3.1. 利用锚点进行谱聚类
GCN只是简单地聚合了一跳邻居的信息,且GCN的深度通常是有限的。距离遥远且相似的节点的信息总是被忽略,而谱聚类可以根据节点之间的亲密关系来划分节点。具体来说,在新的特征空间中,联系紧密和相似的节点距离更近,反之亦然。因此,将GCN与SC结合起来,提取距离较远但相似的节点的特征是非常合适的。
根据第2.1小节,执行SC的目的是:为了生成簇对齐矩阵 。
只能通过对归一化相似矩阵 的特征值分解来计算,这需要 的时间复杂度,其中 和 分别是节点和簇的数量,在大规模的图来上具有很大的计算复杂度。
高效谱聚类
为了克服计算复杂度的问题,论文提出了高效谱聚类(ESC)来有效地执行SC。采用内积法来构建亲和矩阵 。因此,ESC方法中的归一化相似矩阵G可以表示为:
定义 ,因此 . 的奇异值分解可以表示为:
, 左奇异向量矩阵,奇异值矩阵和右奇异向量矩阵。 的列向量就是G的特征向量。因此,可以很容易地通过使用 的特征向量来构造 ,特征向量对应于 中最大的 个特征值。与直接对 进行特征值分解相比,在 上进行SVD的计算复杂度要低得多。
带锚节点的谱聚类
在许多图结构数据中,节点原始特征的维数 通常很高,ESC 方法的效率仍有待提高。论文提出了ESC-ANCH,从节点集合 中随机选择 个节点作为锚节点,其中m< 大多数现有的GNN都是为具有高同配性的图而设计的,即链接的节点更有可能拥有相似的特征表示,并且属于同一类别,例如社区网络和引文网络。然而,现实世界中有大量的异配图,其中的链接节点通常拥有不同的特征,属于不同的类别,例如网页链接网络。这些在同配性假设下设计的GNN对于异配性下的图来说是非常不合适的。 无论图的同配程度如何,同一类的节点总是拥有高度相似的特征。如图2所示,为了帮助GCN从同一类的节点中获取信息,作者根据节点之间的相似性和下游任务学习一个重连接的邻接矩阵 。 余弦相似度作为度量函数,一对节点之间的相似度可以表示为: 是可学习的权重向量,因此可以生成相似度矩阵 ,元素的取值范围是 。但是邻接矩阵应该是非负的和稀疏的。因此,需要从 中提取一个非负的、稀疏的邻接矩阵 。定义一个非负的阈值 ,并将 中那些小于 置0。 首先利用原始特征 和SC特征 来构建EF SLGCNs 的第一层表示为: 是可训练的权重矩阵。也可以使用 和 进行拼接: 如果使用平均方法则记为 ,如果使用拼接方法则记为 。 在第一层构建完成后,使用重连接 来聚合和更新节点的特征,以获得中间表征: 是行归一化邻接矩阵。 同样使用原始邻接矩阵 来聚合和更新特征,获得节点的间接表征 。 , 表示特征聚合的时间, ,经过几轮的特征聚合之后,组合几个最关键的间接表示,作为节点的新的嵌入: 对于具有高同配性的图, 和 足够来表征节点的嵌入。这可以由GCN和GAT证明。此外, 可以被视为 和 的补充。对于异配性不足的图, 和 在学习特征表示上也能表现良好。为了充分发挥这些中间表征的优势,利用拼接方式来组合这些中间表征。 随后,生成一个与 相同维度的可学习权重向量 ,并将 和 之间的哈达玛德积作为节点的最终特征表示。 这一步的目的是突出 的重要部分。之后,根据最终嵌入Hfinal对节点进行分类,具体如下: 其中 是最后一层的可训练权重矩阵,分类损失如下: 即交叉熵损失。 为防止过拟合,对学习到的图应用一个正则项 。重连接的图 的同配性很高, 的连通性和稀疏性也很重要,定义正则项 如下: 其中 和β是非负的超参数。第一项通过对数项促进 中的连接性,第二项促进 变得稀疏。 最后的 loss 如下: 在本文中,使用 的SLGCN被称为SLGCN ,使用 的SLGCN为SLGCN 。算法1中给出了的SLGCN的伪代码。 三个常用的引文数据集:Cora, Citeseer, and Pubmed,三个 WebKB 的子网络 Cornell, Texas, and Wisconsin,两个Wikipedia网络:Chameleon and Squirrel,来验证提出的 SLGCN。 对于所有的数据集,将每一类的节点随机分成48%、32%和20%,用于训练、验证和测试。测试是在每次运行中验证损失达到最小时进行的。所有数据集的特征概述见表1。 图的同配水平度量 利用边的同配性比率描述边的同配水平: 当h高时,图具有强的同配性(h→1),而当h低时,图具有强的异配性或弱的同配性(h→0)。表1中列出了每个图的同配水平 h,可以发现所有的引文网络都是高同配性的图,而所有的WebKB网络和维基百科网络都是低同配性的图。 首先验证 SLGCNs 的结构学习的有效性。图3展示了 WebKB 和 Wikipedia 网络中的原始图、初始化图和重连接图的同配性比率。可以观察到,在每个网络中,重连接的图的同配性比率都比原始图和随机初始化的图高很多。这是因为重连接的图是根据节点之间的相似性来构建的,而且在相似性学习中涉及的权重参数可以通过模型的训练来优化。因此,SLGCNs可以通过利用重连接的邻接矩阵来聚合具有相同类别的节点的特征。 通过消融研究探讨了所学的重连接图对所提出的SLGCNs的准确性的影响。 表2所示,原始邻接矩阵A对引文网络中的SLGCN非常重要。然而,在WebKB网络和维基百科网络中,A的影响非常有限,甚至很糟糕。这是因为引文网络是具有高度同配性的图,但WebKB网络和维基百科网络的同配性比例很低。 探讨所提出的ESC-ANCH方法提取的SC特征对SLGCN分类准确性的影响。图4可以看出,SLGCNcc和SLGCNav比没有SC特征的SLGCN获得更好的性能。这说明SC特征不仅反映了节点的ego-embedding,也反映了相似节点。 从表3中,可以看到ESC和ESC-ANCH比SC更有效率。同时,由于引入了锚节点,ESC-ANCH比ESC更快。 图5中,在Cora数据集上实现了3层GCN、4层GCN、5层GCN以及提出的SLGCNcc和SLGCNav。GCN层数的增加会导致过拟合,SLGCNs不需要增加网络的深度来聚集更多的节点特征。因此,无论聚合多少节点特征,SLGCNs都可以免于过拟合。 表4所示,一些GNN模型在WebKB网络和维基百科网络中的表现甚至不如MLP,即GCN、GAT、Geom-GCN和MixHop。造成这种现象的主要原因是GNN模型从邻居聚集了无用的信息,并且没有分离ego-embedding和无用的邻居嵌入。无论采用哪种图,H2GCN和SLGCNs都能获得良好的结果。同时,SLGCNs的结果相对比H2GCN要好。这要归功于SLGCNs的重连接的图。此外,SC特征的引入可以通过将相似的节点聚在一起来改善节点的ego- embedding。 论文提出了一种有效的GNN方法,即SLGCNs。与其他GCNs相比,本文包括三个主要贡献。1)将谱聚类集成到GNN中,用于捕捉图上的长距离依赖关系,提出了一种ESC-ANCH算法,用于处理图结构的数据,效率很高;2)SLGCNs可以学习一个重连接的邻接矩阵,从边的方面改进SLGCNs;3)SLGCNs通过组合多个节点嵌入,适合于所有级别的同配性。3.2. 重连接图
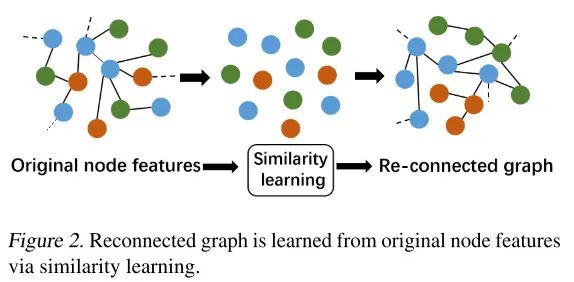 fig1
fig1
3.3. 结构学习图卷积网络
 fig3
fig3
4.实验
4.1 数据集
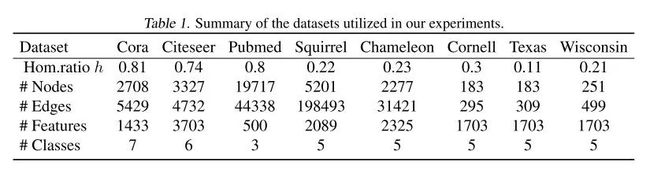 fig4
fig4
4.4. Does Re-connected Adjacency Matrix Work?
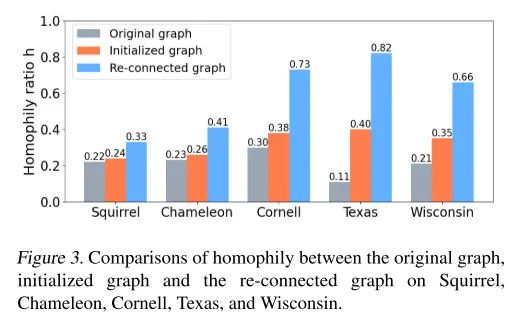 fig5
fig5
 fig6
fig6
4.5. Effect of SC Feature on Accuracy
 fig7
fig7
 fig8
fig8
4.6. Comparison Among Different GNNs
 fig9
fig9
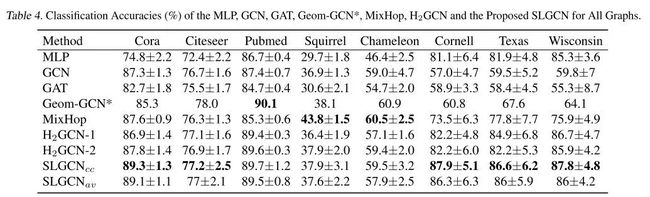 fig10
fig10
5. Conclusion