MG-BERT | 利用 无监督 原子表示学习 预测分子性质 | 在分子图上应用BERT | GNN | 无监督学习(掩蔽原子预训练) | attention
分子性质预测的的大部分文章,本质是研究分子的表示学习,然后应用到性质预测任务。
有分子性质预测的文章,关键词是“property prediction”,也有专门研究毒性的文章,关键词是“toxicity prediction”。
这周读了一篇2021.5发表在BIB上的文章,用无监督的方式学习分子的表示,期刊是化学二区的,影响因子9.905。
MG-BERT: leveraging unsupervised atomic representation learning for molecular property prediction
1 Introduction
1.1 背景
深度学习在各个领域的成功促进了它在分子性质预测中的应用,但面临着数据匮乏的问题。GNNs可以直接从图中学习,但由于受过拟合和过平滑问题的限制,目前的GNNs通常比较浅,削弱了其提取深层模式的能力。
GNN:一般2~3层
over-smooth:过平滑问题,无论特征矩阵的初始状态如何(随机产生),多次卷积后,同一连通分量内所有节点的特征都趋于一致了
1.2 本文工作
本文将GNNs集成到BERT中,提出了分子图BERT(MG-BERT)模型,可以克服普通GNN面临的过平滑问题,并提取深层特征以生成分子表示。进一步提出掩蔽原子预测的预训练策略,可以充分挖掘原子的上下文信息。此外,MG-BERT可以通过attention机制关注目标性质相关的原子和子结构。
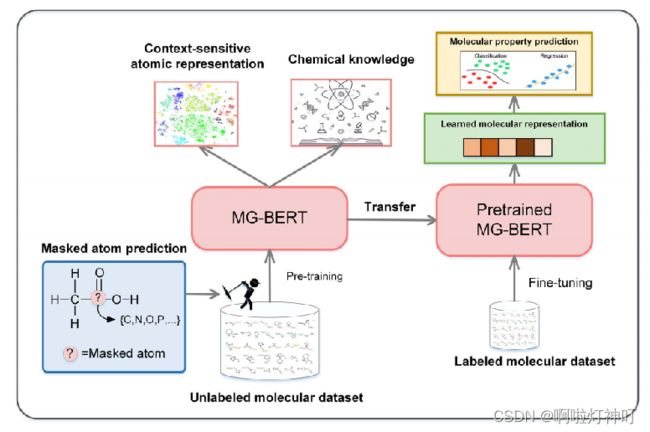
1.3 图形摘要
作者在BERT的基础上提出了MG-BERT:
①Pre-train阶段的任务是学习 上下文敏感的原子表示 和 一些化学知识,input是没有标签的分子数据,对输入分子中的原子进行mask并进行预测,训练模型。
②Fine-tune阶段的任务是预测给定分子的性质,input是有标签的分子数据。使用pre-train阶段训练好的模型,学习分子的表示,用于下游的分类、回归任务。
2 方法
2.1 模型结构
2.1.1 原始的BERT结构
① An embedding layer:通过嵌入矩阵将输入的word token嵌入到连续的向量空间。由于Transformer无法自动学习位置信息,因此要将位置编码加入到向量空间中。
② Several Transformer encoder layers:word token之间通过global attention相互交换信息。
③ A task-related output layer:通常是全连接层,执行分类或回归任务。
2.1.2 MG-BERT的结构
MG-BERT在BERT基础上进行了改进:
① Embedding layer:将word token变为atom token。由于分子中的原子没有顺序关联,因此不需要指定位置信息。
② 将global attention变为local attention based on chemical bonds,只允许原子通过化学键交换信息。因为在自然语言句子中,一个单词可能与其他任何单词相关,而在分子中,原子主要与通过 化学键 与相邻原子相关联。本文使用邻接矩阵来控制分子中的信息交换。
③为每个分子添加了可以连接到所有原子的supernode。一方面,超节点可以与其他节点交换信息,在一定程度上解决了长距离依赖问题;另一方面,超节点可以被视为最终的分子表示,并用于解决下游分类或回归任务。
模型架构图如下:
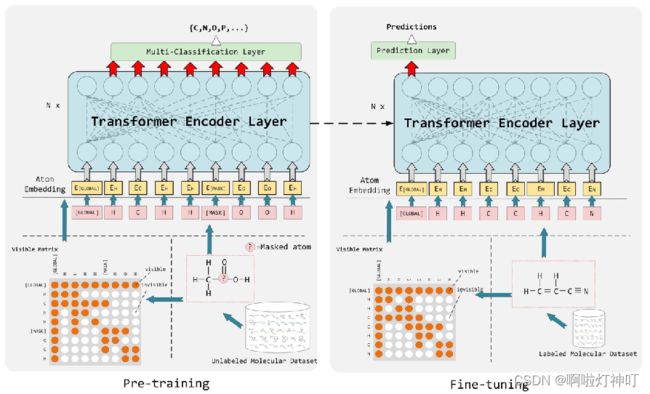
流程如下:
①从未标记的数据集中取出分子,对于每个分子,随机选择15%的原子,每个原子以80%的概率mask,以10%的概率被其它原子替换,以10%的概率不变
②求出这个分子的邻接矩阵,第1个节点是超节点supernode,用[global]标记,被掩蔽的节点用[mask]标记。(这个visible matrix用来调节Transformer中的注意力矩阵,以控制信息交换)
③进行原子嵌入,这里不需要关注位置信息
④输入到transformer中,这里的注意力 是 基于化学键的局部注意力(transformer中的局部注意力)
…
以上部分在pretrain和fine-tune阶段是一样的
最后output:
①pretrain:pretraining head ,用线性分类器预测原子类型,挖掘原子的上下文信息。
②fine-tune:prediction head,预测分子性质。
2.2 预训练策略
使用 masked atom prediction task 来训练模型。首先,随机选择一个分子中15%的原子,只有几个原子的分子至少选一个原子。对于每个选定的原子,以80%的概率被[MASK]标记替换,以10%的概率被其他原子随机替换,以10%的概率保持不变。将原始分子作为ground-truth,计算mask atom的loss。
2.3 输入表示
为了在分子图中表示原子,将所有原子类型添加到字典中。字典中包括了:
①13种常见的原子类型[H]、[C]、[N]、[O]、[F]、[S]、[Cl]、[P]、[Br]、[B]、[I]、[Si]、[Se];
②[unk]表示不常见的原子;
③[GLOBAL]表示超节点;
④[MASK]表示预训练阶段中的掩蔽原子。
2.4 模型训练与评估
① pretraining
使用RDKit将分子转化为2D无向图
–> 为每个分子加一个连接所有顶点的超节点
–> 根据预训练策略,随机选择15%掩蔽
–> 输入到MG-BERT模型中训练,评估指标为recovery rate。
② fine-tuning
预训练后移除pretraining head,换为prediction head(两层全连接)。为了防止过拟合,采用了dropout∈[0, 0.5]。微调优化器为adam optimizer。分类任务评估指标为ROC-AUC,回归任务评估指标为R2。
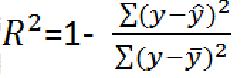
R2:越大越好,分子是 真实值 与 预测值;分母是 真实值 与 真实值的均值
3 实验
3.1 数据集
pretrain:从ChEMBL取出170万个分子作为预训练数据,用于挖掘分子上下文信息 ;
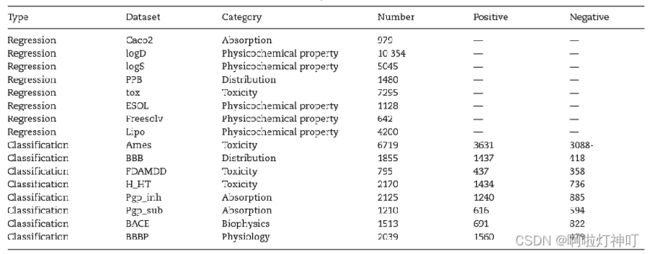
fine-tune:从 ADMETlab 与MoleculeNet 中收集了8 个用于回归,8个用于分类的数据集,覆盖了关键的ADMET性质与常见的分子性质。
数据描述如下:
ChEMBL是一个大型的、开放访问的药物发现数据库,旨在收集药物研究和开发过程中的药物化学数据和知识
ADMET:absorption(吸收),distribution(分配),metabolism(代谢),excretion(排泄),toxicity(毒性)
ADMETlab:一个系统的ADMET(吸收、分布、代谢、排泄和毒性)性质在线预测平台 MoleculeNet:适合分子机器学习的大型基准
MoleculeNet,MoleculeNet 提供多个公共数据集、建立了评估度量,并提供多个分子特征化(molecular featurization)和学习算法的高质量开源实现
Caco2:人 克隆 结肠腺癌 细胞,可以用来研究研究药物吸收的潜力 与 研究药物转运的机制 logD:描述可电离化合物亲脂性的,是所有
化合物形式 在 辛醇/水体系 中 pH依赖的 差异溶解度 的量度 logS:水溶性 指示剂指数,S应该是溶解度,前面的是对数符号
PPB:在溶液中是用 溶质质量 占 全部 溶液质量 的 十亿分比 来表示的浓度,也称 十亿分比浓度(十亿分之一,10-9),经常用于浓度非常小 的场合下
tox:毒性
ESOL:包含1128种化合物的 水溶性数据。该数据集已被用于训练直接从化学结构估计溶解度的模型,就像在SMILES(Simplified molecular input line entry system,简化分子线性输入规范)字符串中编码的那样。但是些结构不包括3D坐标,因为溶解度是分子的属性,而不是其特定构象的属性。
Freesolv:自由溶剂化数据库(Free Solvation,简称FreeSolv)提供了水中小分子的实验和计算的水合自由能
Lipo:脂类 代谢异常 可引起 血脂水平改变,若 血脂浓度 高于 正常值上限 即可称为高脂血症。hyperlipoidemia
Ames:Ames试验全称 污染物 致 突变性检测。 BBB:Biological Basis of Behaviour,生物学上的行为
FDAMDD:生物数据偏差( Microbiological Data Deviations)。美国FDA的一个微生物试验专门工作组首次于2001年提出的一个首字母缩略词MDD,将微生物实验室的数据偏差与化学检验项目的OOS区别开来。
> H_HT:???????????
Pgp_inh:???????????
Pgp_ sub:???????????(暂时没找到相关知识,、以后补充)
BACE:BACE数据集提供了一组人类b-分泌酶1(BACE-1)抑制剂的定量(IC50)和定性(二元标记)结合结果
BBBP:血脑屏障渗透(Blood Brain Barrier Penetration,简称BBBP)数据集来自最近关于屏障渗透性建模和预测的研究。作为分隔循环血液和脑细胞外液的膜,血脑屏障可阻断大多数药物、激素和神经递质。因此,屏障的渗透在以中枢神经系统为靶点的药物开发中形成了一个长期存在的问题。该数据集包括超过2000种化合物的渗透性特性的二进制标签。
3.2 有无预训练
①经过预训练比没有预训练的准确率要高,证明了预训练策略的有效性和预训练模型的良好泛化能力;
②对于小数据集,如Caco2与FDAMMD,准确率提升>7%,表明预训练策略可以更有效地提高小数据集的预测性能。
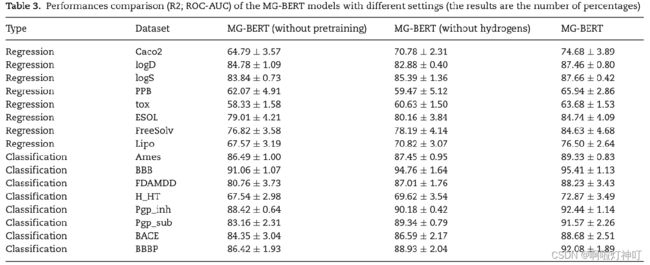
3.3 有无H原子
在大多数已有的分子性质预测模型中,氢原子通常被忽略。在这项研究中,进行了一个控制实验,以探索氢原子是否是MG-BERT模型所必需的。在MG-BERT模型相同的超参数设置下,建立了基于不含所有氢原子的分子图的无氢模型。
结果证明,有H氢原子的准确率比没有氢原子的准确率要高,如上图与下图。
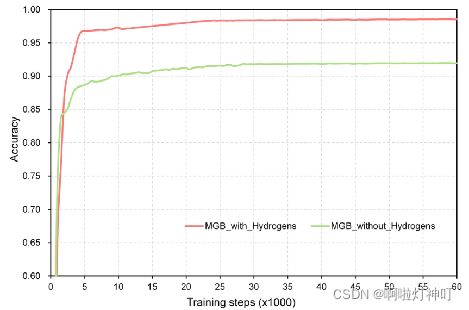
原因有3个:
a.MG-BERT 只利用 分子的 组成和连接 信息。在这种情况下,氢原子可以用来确定其他类型原子的化学键数。在atom masking prediction中,键的数目对于确定掩蔽原子的类型非常重要。
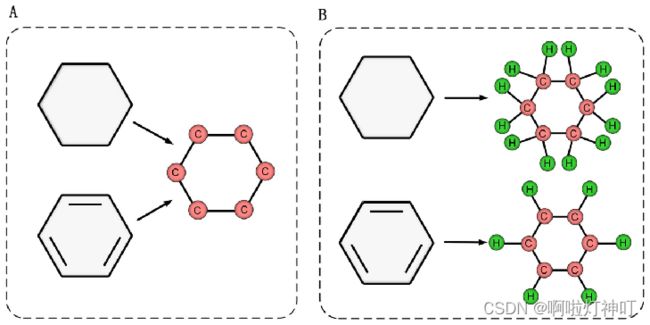
b.如果氢原子被移除,一些分子会变得难以区分。如下面的图,如果去除了氢原子,苯和环己烷可以转化为相同的图形,如A。然而,如果保留氢原子,它们将被转换成两个不同的图形,如B。
c.氢原子的缺失 也会影响 预训练阶段 上下文信息 挖掘 过程,从而削弱预训练模型的泛化能力。
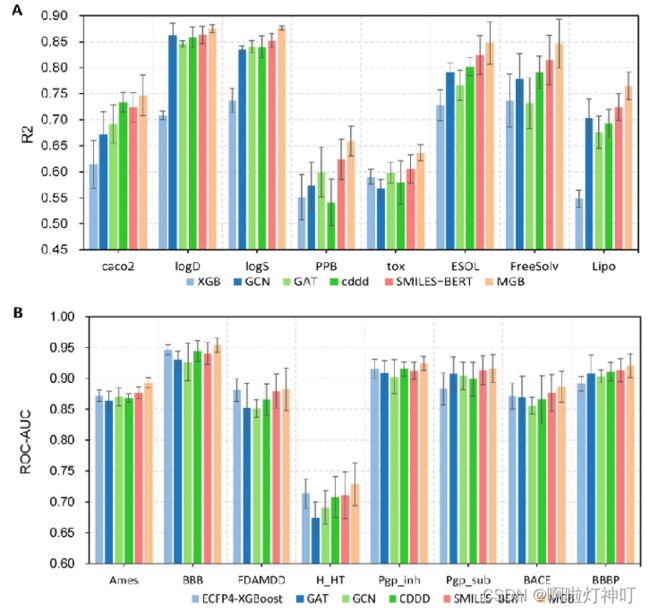
3.4 与其他机器学习方法比较
基线模型:
① ECFP4-XGBoost:是基于 ECFP4 指纹的 XGBoost 模型(ECPF4指纹基于摩根指纹,是基于连通性的)
② CDDD(continuous-and-data-driven descriptor):基于连续和数据驱动描述符,由一个固定的RNN编码器 和 一个全连接层组成组成,编码器已经在 未标记的 SMILES 串上进行了预训练。
③ SMILES-BERT:将BERT模型用于SMILES串。
结果分析:
①ECFP4-XGBoost :基于指纹的模型,在不同数据集上的结果差异很大,可能是因为用ECFP4表示的分子是定长的,所以不适合特定的任务。
②GNN模型,也就是GAT与GCN,在数据集充足时表现较好,在数据集稀少时表现较差。
③CDDD模型性能略低于本文模型,但CDDD模型的分子表示是通过SMILES编码和解码获得的,无法针对特定任务进一步优化。
④SMILES-BERT 与MG-BERT可以在预训练阶段学习到丰富的上下文信息,而且可以针对特定的任务进一步优化。但 SMILES-BERT 效果不如 MG-BERT 好,这可能是因为 SMILES-BERT 需要解析出SMILES串中复杂的语法信息。
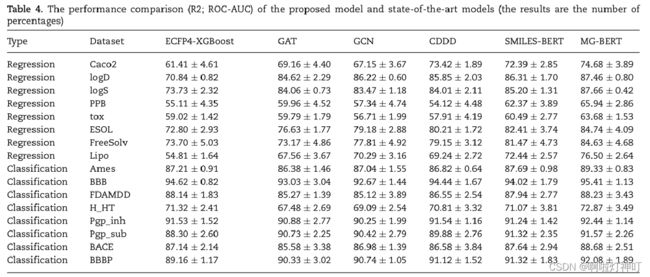
下面这个图更直观一些,最后一条柱是本文模型。
3.5 通过t-SNE分析pretrained MG-BERT的原子表示
为了分析MG-BERT模型在预训练阶段学习到的知识,将pretrain阶段生成的原子表示可视化,试图找到一些有趣的模式。
从fine-tune数据集中随机选择1000个分子(大约2200个原子)在没有mask的情况下输入到预训练模型中,收集transformer的输出。
这样获得22000个向量,每个原子向量256维,使用t-SNE将高维向量可视化。
如图,可以轻松分辨出不同类型的原子,这表明生成的表示包含原子类型信息,同时发现一个问题,即一个种类的原子出现不同聚类。
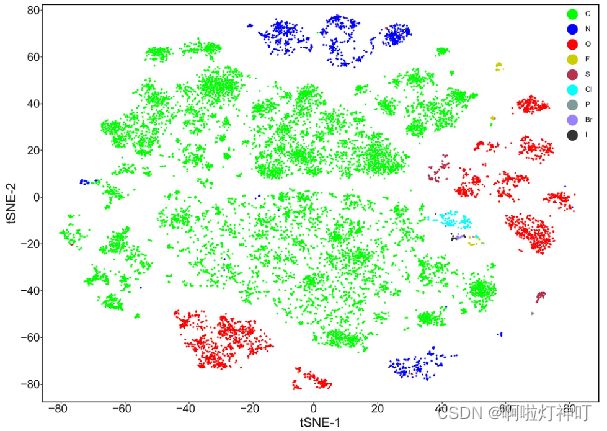
这表明生成的 原子表示 中的信息很丰富,不止有原子类型这一种。
这一发现的启发是根据原子周围的环境来定义一些原子类别(category),并根据它们的类别来可视化原子。
原子的类别主要由一阶邻域的可能变化来定义,如下表。

(如第一行:有四个单键的C原子,没有边与N相连)
结果表明,生成的原子表示包含的信息 除了原子类型以外,还有其邻居信息。
通过这种方式,学习到的原子表示可以被视为分子子结构的表示,这对下游任务非常有益。
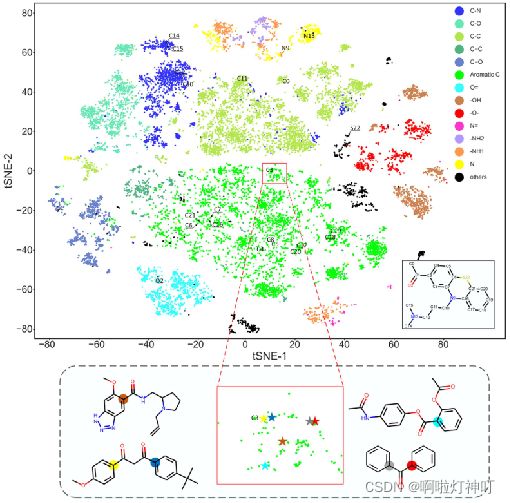
由原子类别(category)着色的(原子嵌入向量的)t-SNE图
①主图 标记了 上表中的 每个类别的原子的位置
放大图中 原子与它相应的位置用相同颜色标记,这些标记的原子都在苯环中,而且与羰基(c=o)相连
②为了进行进一步的分析,随机选择了一个复杂的分子(主图的右下角),并在图中标记了其原子的位置。
可以发现:
(i)如果苯环的支化环境相似,则苯环中的原子往往彼此接近,如将两个苯环连接在一起的碳原子C6/C7/C16/C21;
(ii)小方块标记的碳原子都与羰基(c=o)相连,这些结果表明预训练模型在一定程度上能够捕获高阶邻域信息。
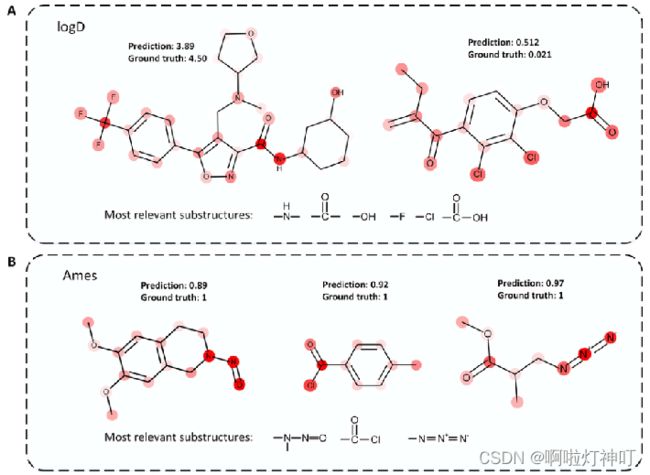
3.6 MG-BERT注意力分析
根据特定任务 可视化 分子的 注意力权重。
①当分析亲脂性时,更多的注意力放在极性基团上,如A,因为极性基团在决定分子亲脂性方面起着重要作用。(logD是用来分析亲脂性的)
②当确定一个分子是否属于诱变剂时,注意力主要集中在 酰氯、亚硝胺和叠氮化物上,这些基团已经被证明了可以导致结构突变。(Ames任务是用来确定一个分子是否属于诱变剂的)
这些结果表明,MG-BERT能够根据特定任务合理分配注意权重,这对于药物化学家探索亚结构与分子性质之间的关系具有重要意义。
4 结论
本文将分子图数据融合到BERT中,用来解决分子性质预测中的数据稀缺问题,MG-BERT通过掩蔽原子恢复任务利用大量未标记的分子数据挖掘分子图中的上下文信息,以实现有效的原子和分子表示学习,其亮点如下:
①提出了一种有效的自监督学习策略——masked atoms prediction,用于在大量未标记数据上预训练MG-BERT模型,以挖掘分子中的上下文信息。得到的原子表示不仅包含原子类型信息,也包含其邻居信息;
②注意力机制可以测量原子或子结构与目标属性之间的相关性。