基于 docker 搭建 grafana+prometheus 监控资源之mysql+docker+alertmanager配置(二)(超详细版)
先去看第一篇(基础部署篇),看完后,才能接上本篇。
基于 docker 搭建 grafana+prometheus 监控资源之mysql+docker+alertmanager配置(二)
-
-
- 环境信息
- 服务基本信息
- 一、安装Mysqld_exporter
-
-
- 1.1 标准启动
- 1.2 docker-compose启动
-
- 1.2.1 创建mysql用户并配置权限
- 1.2.2 配置.my.cnf文件
-
- 二、安装Cadvisor
- 三、安装AlertManager
-
-
- 3.1 AlertManager配置
- 3.2 Prometheus 配置 AlertManager 告警规则
-
- 四、触发告警(静等5分钟...)
-
环境信息
| hostname | ip |
|---|---|
| linux_204 | xxx.204 |
| linux_207 | xxx.207 |
服务基本信息
| 服务 | 作用 | 端口(默认) |
|---|---|---|
| Prometheus | 普罗米修斯的主服务器 | 9090 |
| Node_Exporter | 负责收集Host硬件信息和操作系统信息 | 9100 |
| MySqld_Exporter | 负责收集mysql数据信息收集 | 9104 |
| Cadvisor | 负责收集Host上运行的docker容器信息 | 8080 |
| Grafana | 负责展示普罗米修斯监控界面 | 3000 |
| Altermanager | 等待接收prometheus发过来的告警信息,altermanager再发送给定义的收件人 | 9093 |
一、安装Mysqld_exporter
部署该容器后,mysqld_exporter会通过配置的DATA_SOURCE_NAME的信息去连接该mysql数据库,但由于我的mysql数据库是以docker swarm集群方式启动的,那么我的mysqld_exporter容器必须和该mysql数据库互通。因此,我将mysqld_exporter的网络也使用mysql数据库的网络,这样保证二者可以互相访问,那mysqld_exporter就使用docker-compose方式启动。下方我列出标准启动和docker-compose启动的命令,各位根据需求自取:
1.1 标准启动
# 启动mysqld_exporter
docker run -d --name mysqld_exporter --restart=always -p 9104:9104 -e DATA_SOURCE_NAME="root:Password123@(172.17.0.2:3306)/" prom/mysqld-exporter
说明:
- root -----> 账户
- Password123 -----> 密码
- 172.17.0.2:3306 -----> 地址和端口
1.2 docker-compose启动
# 启动mysqld_exporter
vim mysqld_exporter.yml
version: '3.2'
services:
mysqld_exporter:
image: prom/mysqld-exporter
restart: always
networks:
- pangu_middleware_pangu_online
volumes:
- ./.my.cnf:/home/.my.cnf #用于mysqld_exporter去访问mysql数据库
deploy:
replicas: 1
ports:
- "9104:9104"
environment:
DATA_SOURCE_NAME: "mysqld_exporter:mysqld_exporter@(192.168.220.148:3306)/" #这是mysql数据库的ip地址以及用户(用户需要单独创建)
networks:
pangu_middleware_pangu_online: #该网络是mysql数据库所在的网段
external: true
PS:正如上述文件的注释中写道:我们mysqld_exporter需要去访问mysql数据库,那么mysql数据库就需要创建一个用户和地址(mysqld_exporter@(192.168.220.148:3306))供mysqld_exporter访问,且mysqld_exporter也需要通过配置文件中的用户和密码(.my.cnf)才能够访问。
1.2.1 创建mysql用户并配置权限
create user 'mysqld_exporter'@'%' identified by 'mysqld_exporter';
GRANT SELECT, PROCESS, SUPER, REPLICATION CLIENT, RELOAD ON *.* TO 'mysqld_exporter'@'%';

由于我是测试环境,且mysqld_exporter容器一直要重启,ip一直变,所以我就创建用户以及登录权限的时候给了"%",真实环境大家记得只给单独的ip,更加安全和规范。
1.2.2 配置.my.cnf文件
vim .my.cnf
[client]
user=mysqld_exporter
password=mysqld_exporter
输入http://ip:9104/metrics查看是否数据上报

配置prometheus.yml文件
# 在后面添加以下数据
vim prometheus/prometheus.yml
- job_name: pangu_mysql
static_configs:
- targets: ["xxx.xxx.xxx.204:9104"] # 收集mysql信息的mysqld_exporter的ip(这里是宿主机ip,ip映射到了宿主机)及端口
#重启prometheus容器
docker restart docker_prometheus
PS:这里一定是重启docker_prometheus,千万不要删除哈,不然所有已监控到的数据全部丢失了, 会重新监控,之前我修改了prometheus.yml后重启,容器内一直无法生效,索性就直接删除,重建了。当时还在想为什么数据全没了。。。但之所以无法生效是因为第一次docker run docker_prometheus容器时,没有使用-v指定映射文件,因此修改了容器外文件,重启也不会映射到容器内。
完成后在http://ip:9090/targets中查看是否有刚刚配置的job_name: xxx信息出现
这里给出的全效果图
打开Grafana倒入mysql监控信息模版

二、安装Cadvisor
#启动cadvisor
docker run -v /:/rootfs:ro -v /var/run:/var/run:rw -v /sys:/sys:ro -v /var/lib/docker/:/var/lib/docker:ro -v /dev/disk/:/dev/disk:ro -p 8080:8080 -d --name=cadvisor --restart=always google/cadvisor:latest
浏览器输入http://ip:8080/metrics 查看是否获取到数据

修改 prometheus.yml
# 在后面添加以下数据
vim prometheus/prometheus.yml
- job_name: cadvisor_207
static_configs:
- targets: ["xxx.xxx.xxx.207:8080"]
- job_name: cadvisor_204
static_configs:
- targets: ["xxx.xxx.xxx.204:8080"]
#重启prometheus容器
docker restart docker_prometheus
完成后在http://ip:9090/targets中查看是否有刚刚配置的job_name: xxx信息出现
这里给出的全效果图
打开Grafana倒入mysql监控信息模版

三、安装AlertManager
# 1.启动容器
docker run -itd --name alertmanager prom/alertmanager
# 2.复制容器内部的配置文件到宿主机,不用事先创建$PWD/alertmanager目录
docker cp -a alertmanager:/etc/alertmanager/ $PWD/alertmanager
# 3.删除容器
docker rm -f alertmanager
# 4.启动服务 设置端口9093
docker run -itd --name alertmanager -p 9093:9093 -v $PWD/alertmanager:/etc/alertmanager prom/alertmanager
浏览器输入http://ip:9093/#/alerts

3.1 AlertManager配置
配置 vi alertmanager/alertmanager.yml 宿主机文件(本篇配置的qq邮箱报警,当然也可以163邮箱、企业微信、微信、钉钉等)
# 配置好的文件内容 可直接复制
alertmanager.yml
global: # 全局配置
resolve_timeout: 5m # 处理超时时间,默认为5min
smtp_from: '' # 邮件发送地址(自行配置)
smtp_smarthost: 'smtp.qq.com:465' # 邮箱SMTP 服务地址
smtp_auth_username: '' # 邮件发送地址用户名(邮箱地址)
smtp_auth_password: '英文' # 邮件发送地址授权码(自行查看qq邮箱SMTP或POP3的授权码,百度可查如何配置)
smtp_require_tls: false
smtp_hello: 'qq.com'
route: # 设置报警的分发策略
group_by: ['alertname']
group_wait: 20s # 最初即第一次等待多久时间发送一组警报的通知
group_interval: 5m # 在发送新警报前的等待时间
repeat_interval: 5m # 发送重复警报的周期 对于email配置中,此项不可以设置过低,否则将会由于邮件发送太多频繁,被smtp服务器拒绝
receiver: 'email'
receivers: # 配置告警消息接受者信息
- name: 'email'
email_configs:
- to: '' # #邮件接收地址(自行配置)
send_resolved: true
inhibit_rules: # 抑制规则配置
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
# 重启alertmanager 容器
docker restart alertmanager
3.2 Prometheus 配置 AlertManager 告警规则
新建Prometheus目录下 服务器 告警规则文件
vim prometheus/node-exporter-record-rule.yml【注意看文内注释】
groups:
- name: server-alarm
rules:
- alert: "内存告警"
expr: (1 - (node_memory_MemAvailable_bytes / (node_memory_MemTotal_bytes))) * 100 > 5 #正常情况下是80,这里写了5,是因为我看到真实使用是8,为了做告警出发,写了5
for: 1m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: 检测到 高内存 使用率!"
description: "{{$labels.instance}}: 内存使用率在 80% 以上 (当前使用值为:{{ $value }})"
- alert: "CPU告警"
expr: (1 - avg(irate(node_cpu_seconds_total{mode="idle"}[2m])) by(instance)) * 100 > 80
for: 1m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: 检测到 高CPU 使用率!"
description: "{{$labels.instance}}: CPU使用率在 80% 以上 (当前使用值为:{{ $value }})"
- alert: "磁盘告警"
expr: 100 - (node_filesystem_free_bytes{fstype=~"tmpfs|ext4"} / node_filesystem_size_bytes{fstype=~"tmpfs|ext4"} * 100) > 5
for: 1m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: 检测到 高磁盘 使用率!"
description: "{{$labels.instance}}: 磁盘使用率在 80% 以上 (当前使用值为:{{ $value }})"
新建Prometheus目录下 MySql 告警规则文件
vim mysql-exporter-record-rule.yml
groups:
- name: mysql-alarm
rules:
- alert: "MySql is down"
expr: mysql_up == 0
for: 1m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: 检测到 MySql服务 已停止运行!请重点关注!!!"
description: "{{$labels.instance}}: 当前 MySql服务已停止! (当前状态mysql_up状态为:{{ $value }})"
- alert: "MySql_High_QPS"
expr: rate(mysql_global_status_questions[5m]) > 1500
for: 1m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: 检测到 MySql_High_QPS 过高!"
description: "{{$labels.instance}}: 当前 MySql操作超过 1500/秒 (当前值为:{{ $value }})"
- alert: "Mysql_Too_Many_Connections"
expr: rate(mysql_global_status_threads_connected[5m]) > 300
for: 1m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: 检测到 MySql 连接过多!"
description: "{{$labels.instance}}: 当前 MySql连接超过 300个/秒 (当前值为:{{ $value }})"
- alert: "mysql_global_status_slow_queries"
expr: rate(mysql_global_status_slow_queries[5m]) > 5
for: 1m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: 检测到 MySql 慢查询过多!"
description: "{{$labels.instance}}: 当前 MySql慢查询 超过 5个/秒 (当前值为:{{ $value }})"
- alert: "SQL thread stopped"
expr: mysql_slave_status_slave_sql_running != 1
for: 1m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: 检测到 SQL 线程停止!请重点关注!!!"
description: "{{$labels.instance}}: 当前 SQL线程 已停止! (当前值为:{{ $value }})"
- alert: "IO thread stopped"
expr: mysql_slave_status_slave_io_running != 1
for: 1m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}: 检测到 IO 线程停止!请重点关注!!!"
description: "{{$labels.instance}}: 当前 IO线程 已停止! (当前值为:{{ $value }})"
修改Prometheus.yml文件
vim prometheus/prometheus.yml
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets: ["xxx.xxx.xxx.204:9093","xxx.xxx.xxx.207:9093"] # 告警配置地址
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
- "*rule.yml" #告警通知文件信息
# 重启Prometheus 服务
docker restart docker_prometheus
浏览器输入http://ip:9093/#/status检查是否配置成功

正常状态
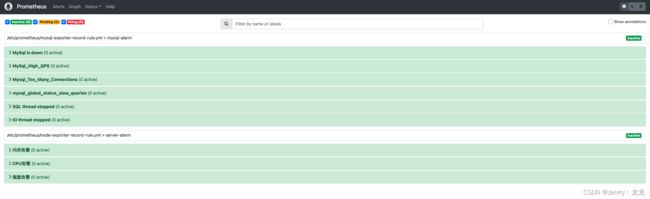
四、触发告警(静等5分钟…)

将node-exporter-record-rule.yml中的内存使用率阀值改为80

告警解除

至此,基于 docker 搭建 grafana+prometheus 监控,以及监控项所有的配置全部完成。可以说比较简单,但是逻辑理清楚,出现问题知道是哪一块问题才是最主要的。送各位一句话:隧道的尽头总有光!!!加油,年轻的我们!