pytorch怎么样自定义datasets数据集(用于分类任务)一
pytorch怎么样自定义datasets数据集(用于分类任务),做个实验 ,如下的结构。其中voc30里面存放这三十张图片,图片名为000001.jpg到0000030.jpg
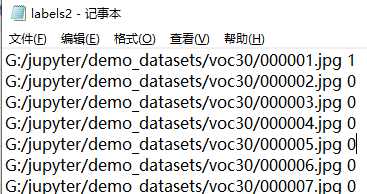
而作为标签文件的labels2.txt存放的是上述图片的地址和类别标签,如下
from torchvision import transforms, utils
from torch.utils.data import Dataset, DataLoader
import matplotlib.pyplot as plt
from PIL import Image
def default_loader(path):
return Image.open(path).convert(‘RGB’)
from torchvision import transforms, utils
from torch.utils.data import Dataset, DataLoader
import matplotlib.pyplot as plt
from PIL import Image
def default_loader(path):
return Image.open(path).convert('RGB')
class MyDataset(Dataset):
def __init__(self, txt, transform=None, target_transform=None,loader=default_loader):
fh = open(txt, 'r')
imgs = []
for line in fh:
line = line.strip('\n')
line = line.rstrip()
words = line.split()
imgs.append((words[0],int(words[1])))
self.imgs = imgs
self.transform = transform
self.target_transform = target_transform
self.loader = loader
def __getitem__(self, index):
fn, label = self.imgs[index]
img = self.loader(fn)
if self.transform is not None:
img = self.transform(img)
return img,label
def __len__(self):
return len(self.imgs)
transform = transforms.Compose([
transforms.Resize((227,227)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])
])
#txt这里的路径是当前项目下
#这里labels2.txt里面的图片路径是绝对路径,而且一定要transform,防止出现图片大小不一,
#因为DataLoader只识别大小尺寸统一的图片
train_data=MyDataset(txt='labels2.txt', transform=transform)
data_loader = DataLoader(train_data, batch_size=6,shuffle=True)
print(len(data_loader))
输出 5
for i, data in enumerate(data_loader):
inputs, labels = data
print(inputs.shape,labels)
torch.Size([6, 3, 227, 227]) tensor([1, 1, 0, 0, 1, 0])
torch.Size([6, 3, 227, 227]) tensor([1, 0, 0, 0, 0, 0])
torch.Size([6, 3, 227, 227]) tensor([0, 0, 0, 0, 0, 0])
torch.Size([6, 3, 227, 227]) tensor([1, 0, 1, 1, 0, 0])
torch.Size([6, 3, 227, 227]) tensor([0, 0, 0, 1, 0, 1])