元学习:Meta-Learning in Neural Networks: A Survey
原文:Timothy M Hospedales, Antreas Antoniou, Paul Micaelli, Amos J Storkey. Meta-Learning in Neural Networks: A Survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence. 2021. Early Access.
https://doi.org/10.1109/TPAMI.2021.3079209
目录
一、原理
二、分类
(一)previous
(二)this paper
三、应用
(一)Computer Vision and Graphics
(二)Meta Reinforcement Learning and Robotics
(三)Neural Architecture Search (NAS)
(四)其它
四、现有工作及未来发展
(一)现有工作
(二)未来发展
这篇文章是21年5月发表在IEEE Transactions on Pattern Analysis and Machine Intelligence(模式分析与机器智能)上的一篇文章,到现在引用量近700次,主要关注了元学习(Meta Learning)的定义,主要算法,以及在多个领域及场景上的应用。
元学习(Meta Learning)或者叫做学会学习(Learning to Learn)已经成为继强化学习(Reinforcement Learning)之后又一个重要的研究分支。对于人工智能的理论研究,呈现出了 Artificial Intelligence --> Machine Learning --> Deep Learning --> Deep Reinforcement Learning --> Deep Meta Learning 这样的趋势。
之所以会这样发展完全取决于当前人工智能的发展。在Machine Learning时代,复杂一点的分类问题效果就不好了,Deep Learning深度学习的出现基本上解决了一对一映射的问题,比如说图像分类,一个输入对一个输出,因此出现了AlexNet这样的里程碑式的成果。但如果输出对下一个输入还有影响呢?也就是sequential decision making(序列决策)的问题,单一的深度学习就解决不了了,这个时候Reinforcement Learning强化学习就出来了,Deep Learning + Reinforcement Learning = Deep Reinforcement Learning深度强化学习。有了深度强化学习,序列决策初步取得成效,因此,出现了AlphaGo这样的里程碑式的成果。但是,新的问题又出来了,深度强化学习太依赖于巨量的训练,并且需要精确的Reward,对于现实世界的很多问题,比如机器人学习,没有好的reward,也没办法无限量训练,怎么办?这就需要能够快速学习。而人类之所以能够快速学习的关键是人类具备学会学习的能力,能够充分的利用以往的知识经验来指导新任务的学习,因此Meta Learning成为新的攻克的方向。
Meta Learning是一种学习范式,而不是基于场景出发的针对某一种任务的学习方法或框架,例如结合迁移学习,多任务、特征选择和模型集成学习等领域进行研究。另外,在这篇paper中,主要关注了当代神经网络元学习以及单任务元学习,整个过程是通过明确定义的目标函数的端到端学习实现的(如交叉熵损失),并讨论更广泛的(元)目标,比如鲁棒性和计算效率。
一、原理
以分类任务为例,给了一个数据集 ,我们将其分为
,我们将其分为![]() 和
和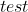 数据集。 传统的人工智能算法采用固定的模型
数据集。 传统的人工智能算法采用固定的模型 来学习这些数据特征,并在预测值与真实值之间求
来学习这些数据特征,并在预测值与真实值之间求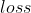 ,通过反向传播、梯度下降等方式来更新参数,进而得到一组最优结果,然后基于这个结果来对新的数据样本进行预测。整个学习过程是data level,围绕进行的。
,通过反向传播、梯度下降等方式来更新参数,进而得到一组最优结果,然后基于这个结果来对新的数据样本进行预测。整个学习过程是data level,围绕进行的。
相比之下,Meta Learning的学习过程与基本数据单元大不相同。以Optimization-based的模型为例,因为我们希望能够加快模型训练过程,同时适应多种任务,因此可以通过学习最优初始化,从而达到这个目标。其训练过程不同于传统人工智能算法的单过程,而是包含Inner loop和Outer loop,目标则是学习一个 ,使其能够针对不同的task能够快速学习
,使其能够针对不同的task能够快速学习 并完成不同任务。Inner loop和Outer loop是理解Meta Learning的核心与关键。
并完成不同任务。Inner loop和Outer loop是理解Meta Learning的核心与关键。
整个过程区别于以数据本身为单位,Meta Learning是以Task为基本单元,整个学习过程是task level(中的数据与分类任务将被分为一个一个的Task,这些Task又会被分为![]() 与
与![]() ,分别对应ML中的
,分别对应ML中的![]() 和
和![]() ),来学习。 学习目标:
),来学习。 学习目标:

其中, 是meta knowledge,
是meta knowledge,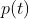 是task的分布,而是task对应的数据集。简而言之,就是我们希望能够学到一个通用的meta knowledge,使得不同的task的
是task的分布,而是task对应的数据集。简而言之,就是我们希望能够学到一个通用的meta knowledge,使得不同的task的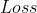 都能越小越好。 Meta Learning分为Meta-train和Meta-test两个阶段,在Meta-train阶段中,我们通过采样大量的source task来学习meta knowledge;然后再Meta-test使用target task来验证效果。 meta knowledge并不等同于用于解决task的model,model的参数是单独存在或者包含于meta knowledge中。所以,Meta-test的目标是基于已经学到的meta knowledge来寻找最优的mode。
都能越小越好。 Meta Learning分为Meta-train和Meta-test两个阶段,在Meta-train阶段中,我们通过采样大量的source task来学习meta knowledge;然后再Meta-test使用target task来验证效果。 meta knowledge并不等同于用于解决task的model,model的参数是单独存在或者包含于meta knowledge中。所以,Meta-test的目标是基于已经学到的meta knowledge来寻找最优的mode。
元学习与迁移学习区别: 1. 元学习的目标是在相似程度较低的任务之间推广学习器,而迁移学习的目标是在相似程度较高的同类任务之间推广学习器; 2. 元学习算法的目标是在任务之间相似程度降低时算法表现不会恶化,而迁移学习算法在任务之间相似程度降低时会出现负迁移导致算法表现恶化; 3. 元学习的目标是让机器学会学习,是General AI的概念。
二、分类
(一)previous
1. Optimization-based methods(基于优化)
学习如何学习新任务, 或者说学习加速新任务学习的方法来达到元学习的目的。神经网络是通过梯度下降来学习的, 对于一组相互关联的任务, 最简单的理解是, 每个任务都有一个最优下降方向,以及最优参数(下降最低点)。而如果我们要找到一个, 让后面的f能够较好的下降, 那么最好的方法无疑是做一个预训练, 能够让网络参数达到一个距离每个任务的最优参数都不太远的位置。一种比较直接的方法, 是取不同任务的梯度的平均方向, 来进行下降,先达到一个比较万金油的位置,而对于动态复杂的真实情况,则没有这么简单,因此诞生了从MAML,到Reptile的一类方法。这些方法通过学习初始化参数,这样用少量的内部步骤就能产生一个对验证数据表现良好的分类器。这也是通过梯度下降来实现的。
2. Model-based (or black box) methods(基于模型(或黑盒))
这类方法关注了基于以往的经验来学习,那索性通过在神经网络上添加Memory来实现,即利用新的模型对梯度预测等强相关与训练速度的指标进行预测。“既然Meta Learning的目的是实现快速学习,而快速学习的关键一点是神经网络的梯度下降要准,要快,那么索性让神经网络利用以往的任务学习如何预测梯度,这样面对新的任务,只要梯度预测得准,那么学习得就会更快了。”"要让学习的速度更快,除了更好的梯度,如果有更好的,那么学习的速度也会更快,因此,索性可以构造一个模型利用以往的任务来学习如何预测。"这类方法的Inner学习步骤被包裹在单个模型的前馈过程中,通过将当前数据集嵌入激活状态,并根据该状态对测试数据进行预测。典型的架构包括循环网络,卷积网络或超网络,嵌入训练实例和给定任务的标签,为测试样本定义预测器。在这种情况下,所有内部层次的学习都包含在模型的激活状态中,并且完全是前馈的,外部优化和内部优化紧密耦合。
3. Metric-based (or non-parametric) methods(基于度量(或非参数))
这类方法关注了用于学习的特征,以及特征间的相似度。“我们知道深度学习的成功来源于能够学习数据的特征表示,进一步说, 一个特征表示是, 不同的数据样例进来, 它们的特征向量的几何距离, 与其在语义空间的相似度相对应。这类似于学习了一个metric,或者说度量, 它可以通过学习到的embedding。如此, 学习一个新的任务, 无非是把数据集所有的数据都用上,然后用K邻近(KNN)方法对测试数据进行分类。”到目前为止,度量学习或非参数算法在很大程度上局限于元学习的流行但具体的少量应用。这个想法是通过简单地比较验证点和训练点,并预测匹配训练点的标签,在内部(任务)级别执行非参数“学习”。按照时间顺序,这是通过siamese, matching, prototypical, relation, and graph神经网络实现的。在这里,外部层次的学习对应于度量学习(找到一个特征提取器,代表适合于比较的数据)。“Metric-based方法学到的embedding是非常general的,因为它能被用到各种任务上。而传统深度学习学到的embedding,往往只能用到同一种任务上。那么,我们可以做一下推断:元学习方法学到了事物背后的关联(学到了如何度量相似性),深度学习学会了分类,但有没有学到事物背后的关联,只有上天才知道。”
(二)this paper
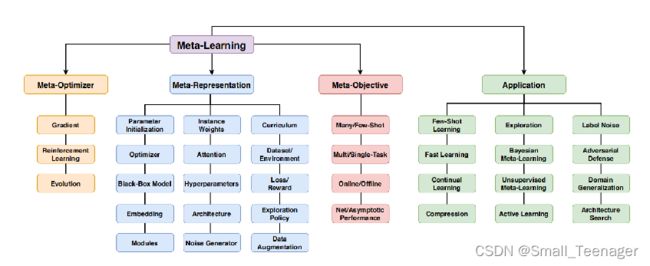
从上面的原理中可以看到,Meta Learning可以对几乎任意的可调整参数进行meta learning,也因此诞生了无数和meta learning相关的paper。meta learning就等价于汽车中的涡轮增压,可以应用到各种发动机中。也因为Meta learning是一个通用性的方法论,使得如何对相关的paper进行分类是个问题。
在这篇综述中作者创新性的对Meta Learning按照是什么(What,Meta-Representation),怎么做(How,Meta-Optimizer),为什么(Why,Objective)来分类。 这种分类方式可以说是目前最全面的分类方式了。 Meta-Representation,即要meta learn的东西。可以是整个model,也可以是超参,网络结构,loss,data等等 Meta-Optimizer,主要指Bilevel-Optimization中的Outer-loop采用的优化方式,这个也就是三种:Gradient,RL及Evolution,根据需要选用 Meta-Objective,即Meta Learning的具体目标,不同的应用会有不同的目标。
三、应用
(一)Computer Vision and Graphics
计算机视觉是元学习的一个主要应用领域,特别是对于小样本学习以及长尾数据的相关任务,有着很好的效果。
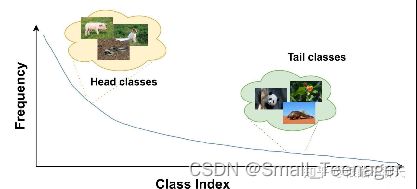
长尾数据就是指几个类别(亦叫头类)包含大量的样本,而大多数类别(亦叫尾类)只有非常少量的样本,是一种偏态分布,比如说上面这张图。
小样本学习非常具有挑战性,特别是对于大型神经网络的应用,小数据集(数据集是掣肘性能的主要因素)训练大型模型会导致过拟合或不收敛,基于元学习的方法能够在许多视觉问题的小数据集上训练强大的cnn。 实际上所谓的应用无外乎就是把双层loop的学习范式应用在不同的场景中,主要就是怎么样能够在这些场景中定义不同的子任务,然后下面这几个类别就简单结合理解做一个介绍,因为原文说的并不是特别清楚。
下面就根据不同领域来举几个例子:
1.分类。元学习最常见的应用是少样本图像识别,其中内部和外部损失函数通常分别是训练和验证集上的交叉熵,通常采用基于优化的方法,度量学习等等。与早期的方法相比,这一工作路线导致了性能的稳步提高,但是仍然远远落后于全监督方法,因此还有更多的工作要做。比如说可以从改进跨域泛化在metatrain和meta-test类定义的联合标签空间内进行识别,增加新的few-shot类别等等的角度入手。
2.目标检测。比如说小样本目标检测和采用基于前馈超网络的方法嵌入support set图像,并在基础模型中合成最终的层分类权重,实际上这个子任务就是不同的分类权重,每个类是一个task。
3.Landmark Prediction。这个问题就是定位图像中关键点的骨架,比如说人类或机器人的关节等等(就是关键点检测)。这种任务通常被表述为图像条件回归,对于人机语言(mml)比如我们可以将不同的关节结构的检测对应于不同的task,也可以组成support query set的元学习数据模式。
此外,还有小样本的分割,动作捕捉,图像生成等等领域也可以带入元学习的学习范式。
(二)Meta Reinforcement Learning and Robotics
强化学习通常与学习控制策略有关,使智能体在环境中执行顺序动作任务后获得高奖励。由于奖励稀疏、需要探索和优化算法的高方差,RL通常会遭遇极端的样本效率低下。
然而,对于meta learning来讲,RL领域存在多个可以套用范式的tasks,例如:移动到或到达不同位置,在不同环境中导航,穿越不同地形,驾驶不同的汽车,与不同的竞争对手agent竞争,以及处理不同的障碍,如单个机器人肢体的故障。元学习可以基于构建的这些任务族来提升RL的效率。
1.探索。RL特有的元表示是探索策略。RL之所以复杂,是因为数据分布不是固定的,而是根据agent的操作而变化的。此外,稀疏的奖励可能意味着代理必须采取许多行动,才能获得可以用于指导学习的奖励。因此,如何探索和获取用于学习的数据是任何RL算法的关键因素。传统的探索是基于采样的随机动作,或手工设计的启发式策略。一些meta-RL研究明确地将探索策略或curiosity function视为元知识 ;并将它们的获取建模为元收益问题通过“学习如何探索”来提高样本效率。
2.优化。RL是一个困难的优化问题,因为即使是在“训练集”集上,学习到的策略通常远远不是最优的。这意味着meta-RL方法更常用于提高渐近性能以及样本效率,并可带来整体上显著更好的解决方案。许多元RL框架的目标是agent在整个过程中的净回报,因此样本高效学习和渐近性能学习都得到了奖励。优化难度也意味着在学习损失(或奖励)方面已经有了相对较多的工作,RL代理应该优化这些学习损失(或奖励),而不是传统的稀疏奖励目标。与真正的目标相比,这种习得损失可能更容易优化(密度更大,更平滑),也将探索与奖励学习联系起来,并可被视为学习内在动机的元学习实例。
3.在线元RL。大量元强化学习研究针对单任务设置,在学习单个任务时,元知识如损失,奖励,超参数,或探索策略与基本策略一起在线训练。因此,这些方法不需要任务族,直接提高了各自基础学习者的表现。
(三)Neural Architecture Search (NAS)
架构搜索可以被视为一种超参数优化,其中meta knowledge指定了神经网络的架构。内部优化使用指定的体系结构训练网络,外部优化搜索具有良好验证性能的体系结构。
NAS(Neural Architecture Search)方法已经根据“搜索空间”、“搜索策略”和“性能估计策略”进行了分析,分别对应于meta knowledge的假设空间、元优化策略和元目标。NAS特别具有挑战性,主要是因为:1.完全评估内部循环是昂贵的,因为它需要训练一个多射神经网络来完成。这导致了类似于在线元学习中对训练集的子采样、内部循环的早期终止,meta knowledge和theta的交错下降等近似。2.搜索空间很难定义和优化。这是因为大多数搜索空间是宽广的,而体系结构的空间是不可区分的。
1.Topical Issues。虽然NAS本身可以被看作是超参数学习的一个实例,但它也可以以其他形式与元学习相互作用。NAS需要耗费较大资源,所以一个热门的问题是该架构是否可以进一步推广,跨多个数据集的元训练可能会改善体系结构的跨任务泛化。最后,还可以定义NAS元目标来训练适合于少次学习的体系结构。类似于快速适应的初始条件元学习方法,如MAML,可以训练良好的初始架构或架构先验从而更容易适应特定的任务。
2.Benchmarks。该框架通常在CIFAR-10上对基准NAS进行评估,但由于混合因素(如超参数调优),执行成本很高,结果也很难再现。为了支持可重复和可访问的研究,NAS-benches为大量网络架构提供了预先计算的性能度量。
(四)其它
1.Hyper-Parameter Optimization
2.Bayesian Meta-Learning
3.Unsupervised and Semi-Supervised Meta-Learning
4.Continual, Online and Adaptive Learning
5.Domain Adaptation and Domain Generalization
6.Language and Speech
7.Emerging Topics
四、现有工作及未来发展
(一)现有工作
1.基于记忆Memory的方法
基本思路:既然要通过以往的经验来学习,那么是不是可以通过在神经网络上添加Memory来实现呢?
2.基于预测梯度的方法
基本思路:既然Meta Learning的目的是实现快速学习,而快速学习的关键一点是神经网络的梯度下降要准,要快,那么是不是可以让神经网络利用以往的任务学习如何预测梯度,这样面对新的任务,只要梯度预测得准,那么学习得就会更快了?
3. 利用Attention注意力机制的方法
基本思路:人的注意力是可以利用以往的经验来实现提升的,比如我们看一个性感图片,我们会很自然的把注意力集中在关键位置。那么,能不能利用以往的任务来训练一个Attention模型,从而面对新的任务,能够直接关注最重要的部分。
4. 借鉴LSTM的方法
基本思路:LSTM内部的更新非常类似于梯度下降的更新,那么,能否利用LSTM的结构训练出一个神经网络的更新机制,输入当前网络参数,直接输出新的更新参数?这个想法非常巧妙。
5. 面向RL的Meta Learning方法
基本思路:既然Meta Learning可以用在监督学习,那么强化学习上又可以怎么做呢?能否通过增加一些外部信息的输入比如reward,之前的action来实现?
6. 通过训练一个好的base model的方法,并且同时应用到监督学习和强化学习
基本思路:之前的方法都只能局限在或者监督学习或者强化学习上,能不能搞个更通用的呢?是不是相比微调(finetune)学习一个更好的base model就能work?
7. 利用WaveNet的方法
基本思路:WaveNet的网络每次都利用了之前的数据,那么是否可以照搬WaveNet的方式来实现Meta Learning呢?就是充分利用以往的数据呀?
8. 预测Loss的方法
基本思路:要让学习的速度更快,除了更好的梯度,如果有更好的loss,那么学习的速度也会更快,因此,是不是可以构造一个模型利用以往的任务来学习如何预测Loss呢?
(二)未来发展
在综述中作者列出了大量的应用,鉴于Meta Learning的涡轮增压属性,哪里都可以用得到。
1. meta-learning architectures
2. meta-learning the learning algorithms themselves
3. generating effective learning environments
当以上三个都能实现,我们就有希望构造极强的人工通用智能系统(AGI)了。环境,网络结构,算法都是学的。这个Meta Learning就是个上帝了。当然,现实情况是我们目前并不具备这样的计算资源及算法来实现,所以才会有Meta Learning的个个细分领域,我们先在小问题上做做看,能不能有效的提取Meta Knowledge。这又涉及到泛化性generalization的问题。Meta-Knowledge要如何通用才能实现足够的泛化呢?
Meta-Learning的研究有两个趋势: 一个是现在的基准(benchmark)变得越来越复杂。比如Meta-Dataset,要求在完全不同的dataset上实现泛化。 另一个就是让这个meta knowledge变得越来越难提取,比如抽象推理(abstract reasoning),现实推理(physical reasoning)的问题,已经不是简单提取feature就能很好解决的了。这也说明我们现在研究的Meta Learning还是narrow meta learning,而不是general meta learning,一个学会学习的算法,去学习任意的知识。
从上面的分析可以看出,Meta Learning方兴未艾,各种神奇的idea层出不穷,但是真正的杀手级算法还未出现,所以说未来的发展还是值得非常期待的。