经典StNet行为识别网络
论文题目:StNet: Local and Global Spatial-Temporal Modeling for Action Recognition
论文链接:https://arxiv.org/abs/1811.01549
代码:https://github.com/PaddlePaddle/models/blob/develop/fluid/PaddleCV/video/models/stnet
10月份比较忙,很久没有写博客文章了。今天,我给大家带来一篇视频行为识别网络StNet,这是百度视觉技术部联合PaddlePaddle团队2018年开发用于视频分类的网络,该文章被收录在AAAI顶会上。
接下来,我将从以下几个方面来对StNet进行阐述,首先,介绍一下StNet的思想;接着是行为识别领域的研究成果;然后我会对StNet的方法进行详细阐述(重点),最后描述StNet的对比实验,来体现其优于当前一些state of the art。
首先介绍一些StNet的思想,StNet将n个连续的视频帧叠加成一个具有3N个通道的super-image,并对super-image进行二维卷积以获取局部的时空关系。为了建立全局时空关系模型,接着将时序卷积应用于局部时空特征图。
接下来,我会用少量的篇幅,再次阐述行为识别的研究成果(其实之前的文章中,我也有过阐述)。对于视频行为识别,做研究的人都知道,要想让算法识别某个动作,首先要将视频输入算法,视频输入算法,最重要的过程是提取特征,有用的特征是成功识别某个动作的关键。对于视频行为识别,我们除了要获取每个视频帧空间信息,不仅要获取动作的时序信息,这是为什么

图1. 局部信息和全局时空特征作用
呢?空间信息告诉我们图片中是什么东西,时序信息告诉我们如何变换,而空间+时序信息告诉我们所关注的东西随时间如何变换,如图1说明了空间和时序信息不同作用。对于基于深度学习的行为识别,目前有两个主要的研究方向:(1).利用CNN+RNN(Donahue et al. 2015; Yue-Hei Ng et al. 2015) ,CNN用来提取空间特征,而RNN用来提取时序特征,然而对于RNN,由于其重复结构,使得端到端优化变得非常困难;(2).使用纯的卷积网络进行行为识别(Simonyan and Zisserman 2014; Feichtenhofer, Pinz, and Wildes 2016; 2017; Wang et al. 2016; Tran et al. 2015; Carreira and Zisserman 2017; Qiu, Yao, and Mei 2017),Simonyan and Zisserman 使用2D卷积来提取经采样RGB帧局部空间特征,对于时序上动作变化,仅仅对几个片段分类得分进行融合,这种方式没有充分考虑时空特征;Tran(2015)和Carreira and Zisserman(2017)使用3D卷积来同时获取时空特征,然而由于3D卷积巨大的参数量,导致其构成的网络深度很浅。
下面的篇幅,我将对StNet的Approach进行阐述,图2是基于ResNet的StNet。StNet包括几个重要的细节模块,具体有Super-Image,Temporal Modeling Block和Temporal Xception Blocks。接下来,我会对每个模块进行详细阐述。

, 图2 基于ResNet backbone的构造的StNet
Super-Image [图二]
从输入的视频中采样T个时序段,每个时序段包括N张连续的RGB帧,N张图片在通道上进行堆叠形成super-image,StNET网络的一个张量size为:TX3NXHXW。Super-Image中不仅仅包含单帧局部空间信息,而且也包含局部连续视频帧之间时序依赖信息。为了能获得局部时空信息,同时降低参数量和计算代价,使用2D卷积作用于每个T super-images上,具体来说,局部时空相关性由resnet的conv1、res2和res3块内的2d卷积核来获取,具体如图2所示。作者设置N=5,在训练阶段,除了第一卷积层外,2D卷积块可以直接用ImageNet预先训练的主干2D卷积模型的权值初始化,而conv1的权重可以按照i3d中所做的操作初始化。
Temporal Modeling Block [图2]
该block的作用可以理解为将一个视频经过2D卷积产生的多个局部时空序段进行聚合产生全局的时空特征。具体为:经过2D卷积的作用,得到T个局部时空特征图,通过这T个时空特征图建立全局的时空特征图对于理解视频是至关重要的,相关实现在图2,经过2D卷积作用之后,通过TMB(Temporal Modeling Block)来获取一个视频长时序的时序变换信息,TMB由3D卷积实现(Conv3d-BN3d-ReLU),为了节省计算量,3D卷积空间核size为1,时序kernel size为3。在res3和res4产生的局部时空特征图上应用TMB来获取全局时空信息。在TMB模块中,Conv3d的权重最初设置为1/(3×Ci),其中Ci表示输入通道大小,而偏压设置为0,BN3D是初始化为恒等映射。
Temporal Xception Block (图3)
该模块设计的初衷是为了在特征序列之间高效的时间建模和易于端到端优化而设计的。具体结构如图3所示,输入TXB模块 tensor 的size为TxCin,TxCin是对T个super-imags的feature map 进行全局均值池化所得到。在TXB中输入先经过1DBN层,为
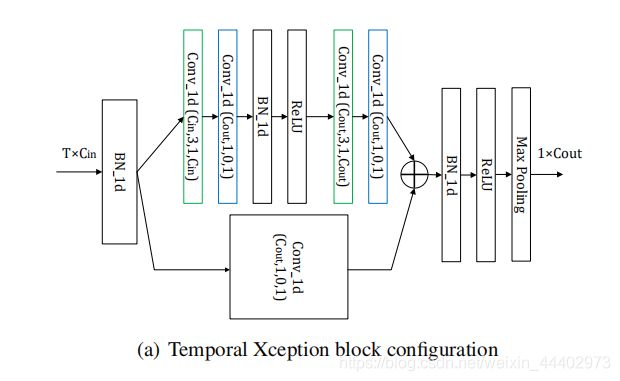
图3 Temporal Xception Block
了使得输出同方差分布,1DBN输出为V,具体计算如图4。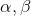 为模型参数,m和var通过mini-batchs获得。为了建立时间关系,将时间维上的卷积应用于V。作者将时间卷积分解为基于逐通道和逐时序分组的一维卷积。技术上,对于基于逐通道的分组一维卷
为模型参数,m和var通过mini-batchs获得。为了建立时间关系,将时间维上的卷积应用于V。作者将时间卷积分解为基于逐通道和逐时序分组的一维卷积。技术上,对于基于逐通道的分组一维卷

图4 1DBN计算
积,时序核大小设置为3,卷积核的数目和组数设置为与输入通道数目相同。对于基于逐时序的分组一维卷积,其卷积核和组数为1,因此,逐时序分组卷积核在每个时序步沿通道维度在所有元素上操作。具体逐通道卷积和时序卷积描述如图5。具体逐通道

图5 逐时序分组卷积核逐通道分组卷积计算
卷积和时序卷积卷积运算如图6,时域 Xception 块(TXB)。时域Xception 块的详细配置如图3所示:括号中的参数表示 1D卷积的(#kernel,kernel size,padding,#groups)配置。绿色的块表示 channel-wise 的 1D 卷积,蓝色的块表示 temporal-wise 的 1D 卷积。图6描绘了 channel-wise 和 temporal-wise 的 1D 卷积。TXB 的输入是视频的特征序列,表示为 T×C_in 张量。Channel-wise 1D 卷积的每个卷积核仅在一个通道内沿时间维度应用。Temporal-wise 的 1D 卷积核在每个时序特征中跨所有通道进行卷积。类似于bottleneck结构,图3TXM结构采用了长短分支,短分支采用了单个ID逐时序卷积,kernel size =group size =1。同时,长分支采用了两个逐通道1D分组卷积。

图6 逐通道和时序卷积
最终经过TXB模块输出的特征,在时序维度进行最大池化操作,得到特征向量表示对视频时空特征的表示,最后经过softmax层进行分类。至此,我已经将StNet的每个模块都阐述完毕。
最后是实验部分,作者在新发布的大规模行为识别数据集Kinetics(Kay等人2017年)对StNet进行了评估。实验结果表明,stnet的性能优于目前几个state of the art 2D和3D的行为识别模型,同时从FLOPs角度来看,StNet在识别精度上优于3D CNN。

图7 不同网络配置结果图
为了验证stnet的有效性,作者在UCF101上进行了比Kinetics小得多的迁移学习实验。为了说明StNet中每个模块的有效性,作者也做了消融实验,具体如图7。图8表示TXN中每个模块重要性。图9 为StNet和一些最优的2D和3D网络对比,结果在Kinetics400和Kinetics600验证集上的评估。图10不同模型迁移学习。为了帮助更好地理解StNet如何学习用于行为识别的区分性时空描述符,作者使用CAM可视化了模型的特定类的激活图(Zhou等人2016)方法。在实验中,T设为7,并从kinetics600验证集中的视频序列中均匀地采样7个片段,以获得它们的类特定激活图。作为比较,作者还可视化了TSN模型的激活图,它利用局部空间信息,然后通过平均分类得分来融合T片段,而不是联合建模局部和全局时空信息。作为说明,图11列出了两种模式的四个动作类(气垫板、高尔夫驾驶、填充眉毛和玩扑克)的激活图。图11表明,与TSN无法联合建模视频中的局部和全局时空动态相比,StNet能够捕获视频帧内的时间交互信息。它关注的是与GT行为作用密切相关的时空区域。例如,它更关注附近有眉笔的人脸,而只有人脸的区域则不那么活跃特别是在“玩扑克”的例子中,StNet仅通过手和赌场令牌被显著激活。然而,TSN被许多面部区域激活。
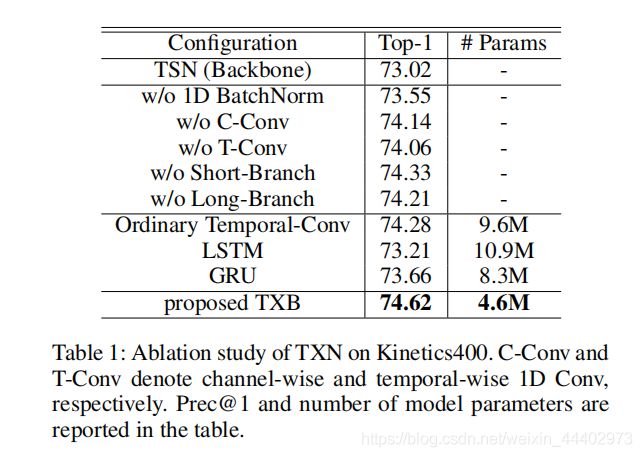
图 8.Ablation study of TXN on Kinetics400
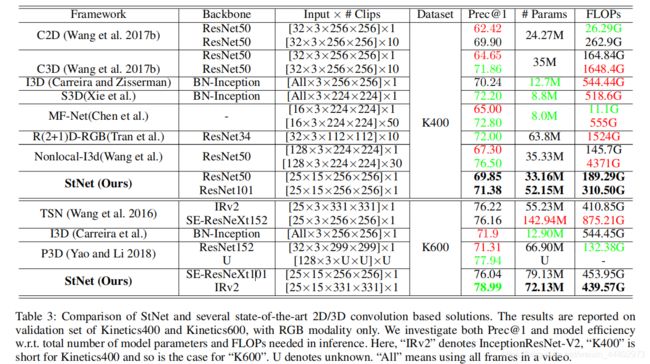
图9 为StNet和一些最优的2D和3D网络对比

图10 不同模型迁移学习在UCF-101评估

图 11 TSN和StNet可视化