关于CNN的可解释性
原创:王稳钺
资料来源:贾老师
本文前两部分介绍CNN的结构、作用以及可解释性的定义、可解释性与可靠性的关系,第三部分介绍解决可解释性问题的主要方法CAM、Grad CAM原理。
1. 认识CNN
CNN主要就是由Conv、ReLU、Pooling层堆叠而成。
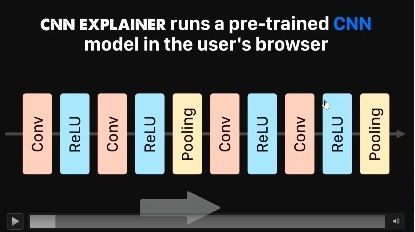
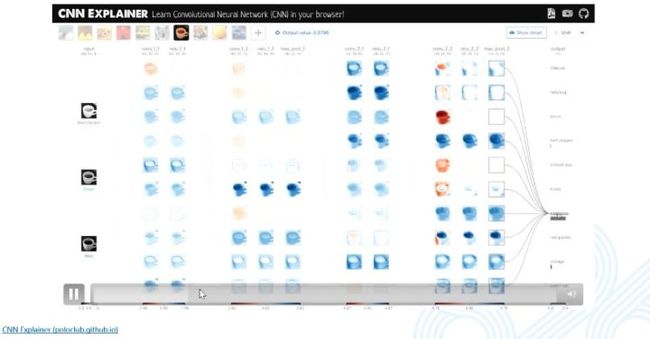
当输入图片给CNN网络,经过不同的操作,会产生各种中间图,如下图。其实下图来自一个可交互的网页,该网页会详细的展示如何通过卷积得到对应的图,感兴趣的同学可以根据下图中左下角的链接了解一下。
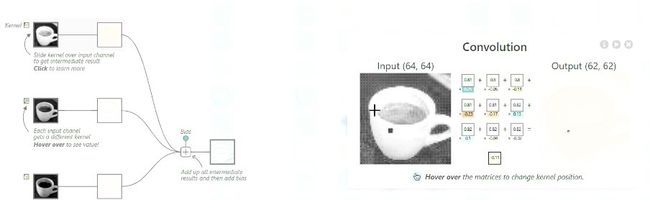
例如第一层叫做卷积层,实际上是先用了一个滤波器,就是图中的九宫格,实际上就是九个数字,这九个数字是固定的。这九个数字要跟另外九个数字相乘,也就是这个白色框里的值,白色框中的值对应原图的灰度值。相乘后得到九个乘积,然后再相加,最后再加一个偏置,这个偏置也是固定。每一张图都做卷积,实际上卷积核也是不一样的,也就是九个数不同。那这九个数怎么来的呢?这九个数实际上是训练得到的,是计算机做最优化的时候找到的一个值。
可以将CNN分成四个组件——张量、神经元、层和权重,下面分别来介绍。
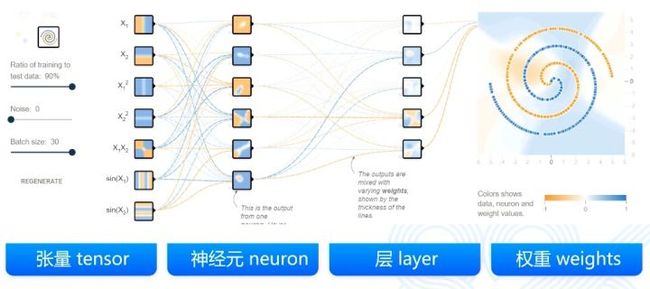
对于张量,其实矩阵就是一个二阶的张量,向量就是一个一阶的张量,一个标量或者任意一个数实际上就是一个零阶的张量。三阶张量是什么呢?其实就是应该有三个维度,其实上面提到的图片有三个通道,实际上就是一个三乘以长乘以高的三阶的张量。张量既可以是输入,输入可以是有很多个样本,每个样本有很多个维度。张量也可以是中间的计算结果。因为每一层对于上一层的结果都会做一个运算,这个运算的结果是要保存在内存里的或者显存里的,那么这个结果实际上也是一个张量。更广泛的,每一层的卷积核或者权重,也通常把它们保存成一个矩阵。那么这个矩阵或者是高阶的矩阵,它也是一个张量。所以张量实际上有多种体现形式,它是做深度学习的时候一种非常基础的数据结构。
第二个组成元素叫神经元。实际上网络中的神经元和生物里的神经元还是差别非常大的,只是简单的模仿。神经元可以有多个输入也可以有多个输出,下图只展示了单输出的情况。神经元中间这个函数是怎么运算的呢?首先它一定要是非线性的。如果是线性的神经元,那么多个这个神经元做叠加,最终网络还是线性网络,没有学习的意义,所以一定要保证神经元的运算是一个非线性函数。为了简单起见,通常如下图设计。
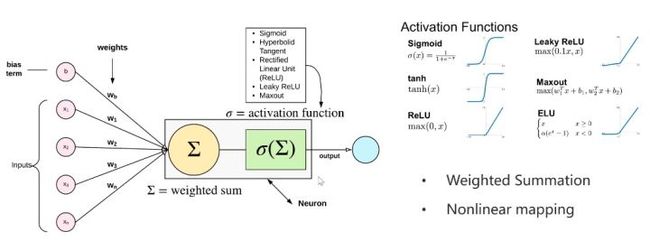
单个神经元通常完成不了复杂的任务,所以研究者就把多个神经元放到同一深度,也就出现了第三个要素——层。神经网络每一层内部实际上是不做运算的,只有上一层跟下一层才有直接的运算关系。这个运算关系就是神经元的运算关系,多个运算关系的叠加。而CNN将每一层的线性的结构变成了一个二维的结构或者一个三维的结构。它就是为了保证三个特性。第一个就是的局部连接性,比如说当看到一个图像的时候,人们通常关心的是一个像素的四周。所以说需要在一个二维空间里,当然三维也可以,起码要在一个二维领域里感受到它的联系。所以CNN的连接不光是一个维度了,而是两个维度,卷积核就这样诞生了,每个卷积核都对应着一定大小的感受野。上文提到过的卷积核中的数字,其实称为权重,权重是网络通过学习得到的。
2. 认识可解释性
什么叫解释性呢?解释性有什么用呢?假如一个模型能做到非常好的效果,常见的任务都能做到 99% 以上准确率,还需要可解释性吗?实际上还是需要的,其实这就是可解释性的必要性。因为有些模型在某些场合总是适用的,但是不代表任何场合都适用,尤其是在未来的某些时间,可能遇到了一些数据,这些数据上模型就会失败。尤其是在一些要求非常高的领域,比如说金融放贷,它要求一个模型判断是否可以贷款给他。假如模型判断可以贷款,但是银行也会考虑这个模型是否可靠,而不是一味地依赖它,这就是可解释性的必要性。即使在历史上这个模型总是成功的,但是通常也要求能够理解这个模型是如何做的决策。而CNN和NN,这方面是比较欠缺的,因为它太复杂,人们很难理解。训练过程发生了很多计算,但是这些并不是人们都能把握好的。所以说这个必要性就使得人们有的时候会需要对这些网络做一个更深层次的探究。
这些探究主要分三个层级。第一层是深度的解释,也就是CNN每一层它提取到了什么特征。比如说检测轮胎,人们发现这个前几层的特征都是关于花纹的,后几层的特征都是关于圆圈的。这个时候实际上做到了第一步——深层的解释,解释清楚了这个神经网络是怎么工作的,原来最后它学到了具有花纹、圆形、黑色的,它就是一个轮胎,它是这样来做预测的。解释清楚了它的工作原理,这个时候网络的可靠性也就有了一定提升。第二层是Interpreitable Models,这个技术是为了学习到更多的结构化、可解释的、有因果的模型说模型。第三层是模型推理。假如模型是黑盒子,假如我们不了解这个模型内部的机理怎么样去解释它,这是XAI的三个研究方向,感兴趣的同学可以深入调研。
对于CNN的可解释性,主流的方法是通过Saliency map(重要性图)。比如下图中,上面一排的图中是两只羊。这时有一个预测概率,是羊的概率是26%,是牛的概率是17%,这里是做一个类别预测。这里只写了前两个类别的这个可能性,其他的这个类别没有写,一定是还有其他类别,因为它的概率加起来不是1。可以根据某种技术得到,当网络或者模型的重要性图,当它分类为羊时,在白羊这块关注度比较高的,其他区域是比较低的。对于牛这个类别,它对于右边的黑羊区域是比较关注的。
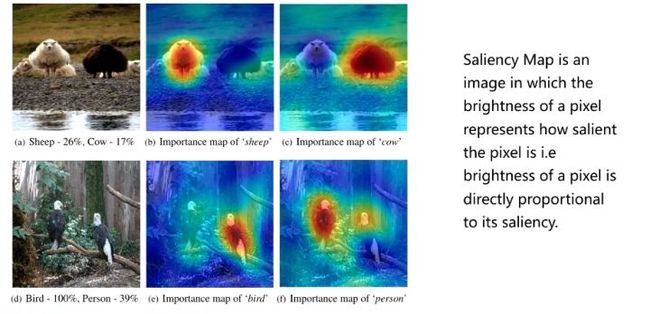
上面的图是如何得到的呢?实际上是和原图做了一个叠加。Saliency map实际上是中间某一层的特征图,这个特殊的特征图像素是比较低的。在和原图做累加时就需要resize,把它做一个这个放大,然后再加在一起。下图中右边是采用三种不同的CAM算法的结果,可以发现对于不同类别关注的区域是不同的。这就提供了可解释性。同时,假如一个模型不太成功,模型预测是老鼠,做出了一个错误的预测。那只能从头调参吗?实际上第一步要看模型为什么错了,它到底对于这张图来说注意了哪些区域。那么就可以从三种CAM技术中任选一种,看一看模型对于老鼠类别注意哪里。假如模型注意到了绿色草地,这时候就要警惕了,说明模型判断这张图片为老鼠,它不是靠老鼠的特点,而是靠周围草丛的特点,那么凡是有草坪的图都预测为老鼠。实际上这个时候对于有经验的人来说,这已经是一个很明显的信号了。这种现象说明数据选的不太合适,数据的多样性不足,老鼠跟草坪总是同时出现,所以导致了模型在做老鼠分类的时候,就集中在了草坪上,而没有集中在了这个动物上。可以非常简单地这这个想到的问题并且可以解决问题,这也是可解释性的一种应用。

3. 解决方法
3.1 CAM
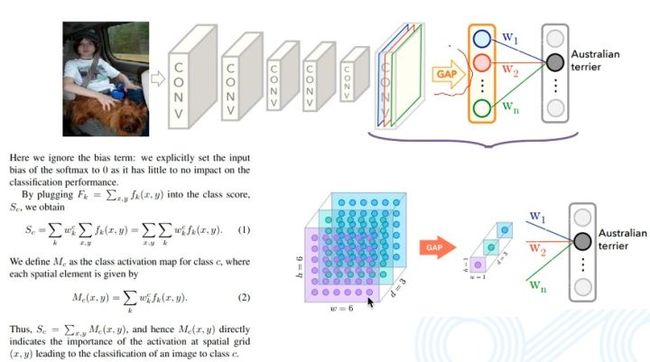
CAM出现于2015年。图片在经过卷积、池化、非线性激活等等这样的一些过程之后,最后得到特征图,这个特征图再经过拉平操作以及FC层,最终经过softmax得到分类结果,大致流程如下图,下图中假设分类结果为ABCDEF六类。
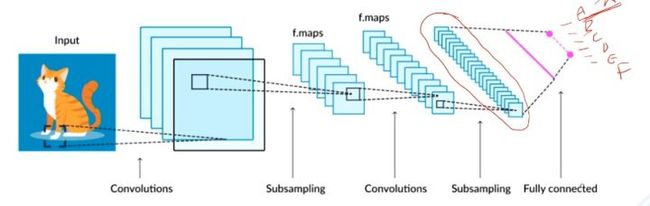
假设网络输出结果为A,那么网络为什么预测了A呢?因为它的值比较大,它的值比较大意味着什么?实际上要看的是权重,与A相连的权重,示意图如下。
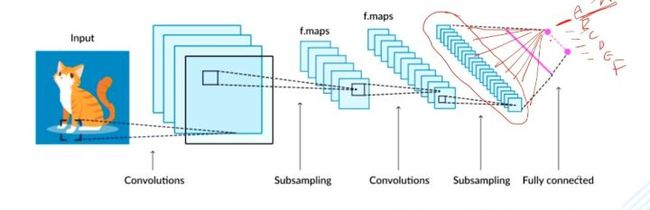
与权值相连的是一系列通道的特征图。特征图的维度一定是很低的,但是它也是个二维的,表示了一定的空间信息。这个时候可以非常粗暴地把权重给它,认为权重是对应的特征图的权重。加权求和把特征图材加到一起就变成了一个图,这个图肯定是尺寸小的,可以通过 resize 将其变成原图大小。这张图实际上就表示了它对于 A 类别的关注程度。但实际上,最后还要经过全连接层,很难找到权重。所以CAM为了解决问题,引入了全局平均池化,将每一个特征图求平均,再与全连接层相连,这样就可以找到每一个特征图所对应的权重,即下图中的w1、w2、w3。加入w1比较大,就意味着w1对应通道的特征图比较重要,CAM就是这样的机理。
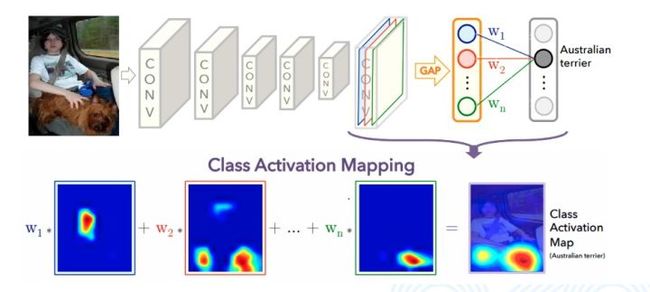
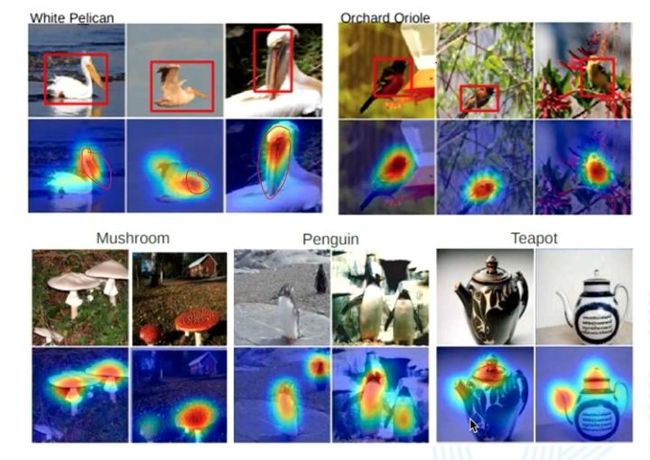
下图展示了CAM原文所给出的结果。
3.2 Grad CAM
Grad CAM从名字上理解就是CAM加上一层梯度信息。CAM为了解决特征图映射的关系,刻意新加了全局平均池化层。但假如说模型已经训练好了,费了很长时间训练好,需要看它的可靠性或者可不可解释性,还得加入全局平均池化层重新训练,是不是有时不太现实。为了解决这个问题,Grad CAM采用了用类别对每一个位置求梯度,用平均梯度来代替权重,具体见下图。

其实Grad CAM还有一些问题,图像边缘的梯度和图像中间的梯度一样重要吗?这个问题是Grad CAM++所想要解决的。如果对可解释性感兴趣的同学,可以更加深入的了解Grad CAM、Grad CAM++等方法。