Poseur: Direct Human Pose Regression with Transformers 论文阅读笔记
Poseur:使用 Transformer 的直接人体姿态回归
ECCV 2022
论文链接
代码链接
摘要: 本文提出一种直接的、基于回归的方法从单个图像中估计2D人体姿态。本文将姿态估计问题表述为一个序列预测任务(sequence prediction task),并使用Transformer来解决。本文提出的网络无需借助热图这样的中间表示,直接学习从图像到关键点坐标的回归映射。这种方法避免了热图法的许多复杂性。为克服以往回归法中存在的特征错位(feature misalignment )问题,本文提出了一种注意力机制,自适应地关注与目标关键点最相关的特征,从而大大提高了准确性。更重要的是,本框架是端到端可微分的,且会自然学习利用关键点间的依赖关系。MS-COCO和MPII数据集上的实验结果表明,本文的方法大大改进了姿态估计回归法的sota。更值得注意的是,本文的方法是第一个优于热图法的回归法。
文章目录
- Poseur:使用 Transformer 的直接人体姿态回归
- 1 Introduction
- 2 Related Work
- 3 Method
-
- 3.1 Poseur Architecture
- 3.2 Training Targets and Loss Functions
- 3.3 Inference
- 4 Experiments
-
- 4.2 Ablation Study
- 4.3 Extensions: End-to-End Pose Estimation
- 4.4 Main Results
- 5 Conclusion
- 6 Additional Results
-
- 6.1 The Effect of Training Schedules
- 6.2 The Effect of Self-attention
- 6.3 Reducing the Number of Parameters
- 6.4 Computational Cost of EMSDA
- 6.5 Comparing the Performance of Poseur and RLE
1 Introduction
现有的姿态估计方法能分为热图法和回归法。热图法先预测热图或分类分数图,来反映区域中每个像素对应于特定骨架关键点的可能性。目前sota方法使用全卷积网络(FCN)来估计该热图,最终关键点位置估计值对应于热图的强峰值。热图法迄今为止比回归法的精度高,因此目前大多方法都基于热图。但热图法也有缺点:1) GT热图需要手动设计并启发式地调整,noisy不可避免地影响最终结果。2) 需要进行后处理操作来查找单个热图中地最大值,这种操作通常是启发式的,不可微的,不能端到端训练。3) FCN预测的热图分辨率通常低于输入图像的分辨率。分辨率降低会导致量化误差,并限制关键点定位的精度。这种量化误差可以通过各种形式的插值来改善,但这会引入一些额外地超参数,且使框架不那么可微,更复杂。
回归法直接将输入图像映射到身体关节坐标,通常使用全连接(FC)预测层。回归法比热图法的pipeline简单得多,因为姿态估计是作为预测一组坐标值的过程来阐述的。基于回归的方法还减少了非极大值抑制、热图生成和量化补偿的需要,并且本质上是端到端可微分的。
基于回归的姿态估计性能较差。造成这种性能缺陷的原因有很多,首先,为了减少最终FC预测层中的参数量,DeepPose 和RLE 等模型采用了全局平均池化来降低FC层之前CNN特征图的分辨率,如图2(b)所示。这种全局平均池破坏了卷积特征映射的空间结构,显著降低性能。其次,如图2(a)所示,一些基于回归的模型(如 DirectPose 和SPM )未对齐,从而降低了定位精度。最后,回归法只回归人体关节的坐标,没有利用它们之间的结构依赖性。

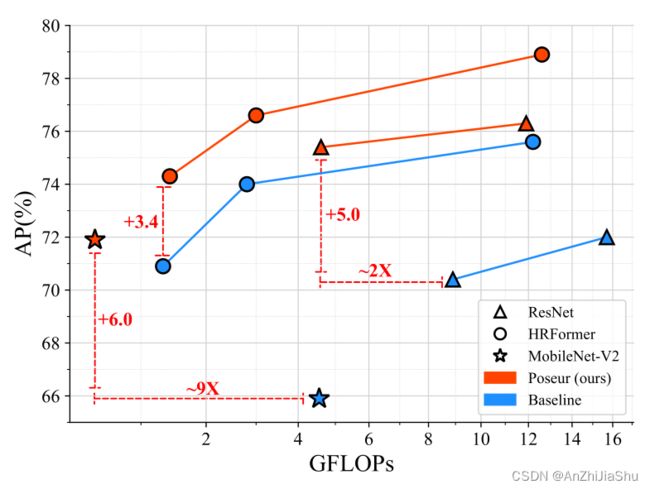
Transformer 最初是为 sequence-to-sequence 任务设计的,激发我们将单人姿态估计表述为一个序列预测问题。具体而言,我们预测一个 length-K 坐标序列,其中K是一个人的身体关节数。 提出了一个简单而新颖的回归的姿态估计框架:Poseur。
如图3所示,将一个 encoder CNN编码的特征图作为输入,Transformer 预测K个坐标对,这样做,Poseur能减轻回归法的缺陷,首先,它无需全局平均池来降低特征维度(参见RLE)。其次,Poseur利用 cross-attention 注意力机制消除了 backbone 特征和预测间的 misalignment。第三,由于self-attention 模块应用于整个关键点queries,因此 transformer 自然会捕获关键点间的结构化依赖关系。最后,如图1 所示,Poseur在多种 backbone 上优于热图法,对于使用低分辨率表示的backbone,如MobileNet V2和ResNet,的改进更显著。结果表明,Poseur可以部署于具有低分辨率表示的fast backbone,而性能没有大幅下降,这是热图法难以实现的。
我们主要的贡献如下:
- 我们提出了一个基于Transformer的轻量级框架:Poseur,直接进行人体姿态回归,可以和使用低分辨率表示的backbone很好地结合。例如,在COCO val set上,基于ResNet-50的Poseur的FLOP减少了49%,且的性能优于超过基于热图的SimpleBaseline5.0 AP。
- Poseur显著提高了回归法的性能,达到了与 sota 热图法相当的性能。例如,在COCO val set,使用ResNet-50 backbone,它在先前最好的回归法(RLE)的基础上改进了4.9 AP,在COCO test-dev set 上,使用HRNet-W48,它超过先前最好的热图法UDPPose 1.0 AP。
- 我们提出的框架易于扩展到 end-to-end pipeline,无需 manual crop 操作,例如,我们将Poseur集成到端到端可训练的Mask R-CNN中,可以克服热图法的许多缺点。在这种端到端设置中,在COCO val set 上,使用HRNet-W48 backbone 我们的方法比先前最好的端到端自上而下方法PointSet Anchor 高3.8AP。
2 Related Work
Heatmap-based pose estimation. 尽管热图法性能良好,但其具有不可微的 decoding pipeline 和由于特征图的下采样导致的量化误差。
Regression-based pose estimation. RLE 是一种基于极大似然估计和流模型的回归法方法。RLE是第一个将回归法的性能提升到与热图法相当水平的方法。然而,它是在由 heatmap loss 预训练的 backbone 上训练的。
Transformer-based architectures. Transformer已成功应用于姿态估计任务。TransPose 和HRFormer 通过将Transformer encoder 应用于backbone 来增强 backbone;TokenPose 通过将图像分割成 patch 并应用 class-token,以 ViT-style fashion 设计姿态估计网络,从而使姿态估计更易于解释。这些方法都基于热图,并使用沉重的transformer encoder来提高模型容量。相反,Poseur是一种具有轻量级Transformer decoder的回归方法。因此,Poseur的计算效率更高,性能更好。
PRTR利用Transformer中的 encoder-decoder 结构执行姿态回归。PRTR基于DETR,即,它使用匈牙利匹配策略来查找 non class-specific queries 和gt 关节间的二部匹配。它带来了两个问题:1)计算量大;2) 每个实例的冗余queries。相反,Poseur可以缓解这两个问题,同时实现更高的性能。
3 Method
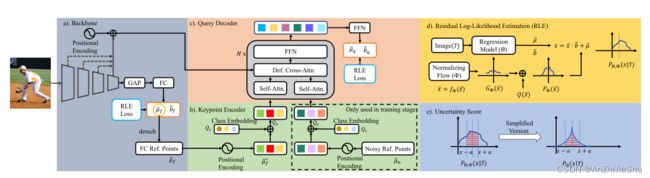
3.1 Poseur Architecture
姿态估计器Poseur的目标是从裁出的单人图像中预测 K个人体关键点坐标。如图2(c)所示,我们方法的核心思想是用 query 表示人体关键点,即每个query 对应一个人体关键点。 queries 被输入到deformable attention模块中,该模块自适应地关注与 query/keypoint 最相关的图像特征。通过这种方式,一个特定关键点的信息能被汇总并编码到单个 query 中,该 query 之后用于回归关键点坐标。因此,RLE(如图2(b)所示)中的全局平均池化导致的空间信息丢失问题能被很好的解决。
具体而言,在Poseur框架中(如图3所示),backbone 上添加了两个主要组件:一个 keypoint encoder 和一个 query decoder。输入图像先被backbone编码为密集特征图,然后FC层,预测粗糙的关键点坐标,用作一组粗糙的 proposals。proposal coordinates 表示为 µ ^ f ∈ R K × 2 \hat{µ}_f∈ R^{K×2} µ^f∈RK×2,然后,这些 proposals 初始化 keypoint encoder中的 keypoint-specific query Q ∈ R K × C Q∈R^{K×C} Q∈RK×C(其中C是embedding dimension)。最后,来自backbone和Q的特征图被送到 query decoder ,以获取关键点的最终特征,每个特征被送到线性层,以预测相应的关键点坐标。此外,与以往简单回归关键点坐标并应用L1损失进行监督的方式不同,Poseur根据 RLE 预测反映每个位置出现GT的概率分布,并通过最大化 GT 位置的概率来监督网络。 具体而言,Poseur(θ)预测一个位置参数 µ ^ q \hat{µ}_q µ^q和一个 scale 参数 b ^ q \hat{b}_q b^q,用于shift 和 scale 由一个流模型Φ生成的分布(参见第3.2节), µ ^ q \hat{µ}_q µ^q是分布的中心,可视为预测的关键点坐标。
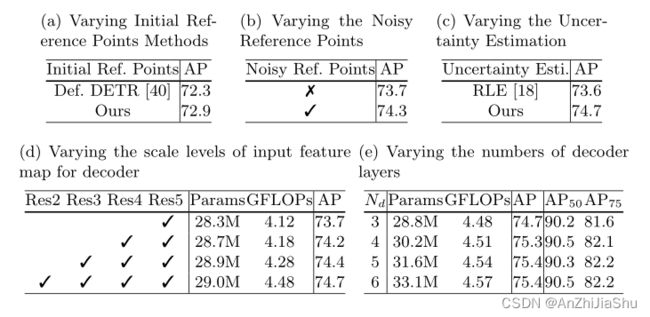
Backbone. 我们的方法适用于CNN(例如ResNet、HRNet)和Transformer backbone(例如HRFormer)。 给定backbone,提取 multi-level 特征图,然后将其输入到 query decoder 中,同时,在 backbone 的最后阶段进行全局平均池操作,然后用FC层回归粗糙关键点坐标 µ ^ f \hat{µ}_f µ^f(归一化为[0,1])和相应的scale parameter b ^ f \hat{b}_f b^f,并由第3.2节介绍的残差对数似然估计(RLE)进行监督。
Keypoint encoder. keypoint encoder 用于初始化 query decoder 的每个query Q。为更好地初始化 query,在 keypoint decoder 中将两个keypoint属性(location和category)编码到 query中。 具体而言,首先,对于位置属性,我们使用 fixed positional encodings 对粗糙的x-y关键点坐标 µ ^ f \hat{µ}_f µ^f 进行编码,遵循ViT 将x-y坐标转换为 sine-cosine positional embedding。获得的tensor表示为: µ ^ f ∗ ∈ R K × C \hat{µ}^∗_f ∈ R^{K×C} µ^f∗∈RK×C,其次,对于类别属性,K个可学习的 vectors Q c ∈ R K × C Q_c∈ R^{K×C} Qc∈RK×C ,称为 class embedding,用于分别表示K个不同的类别。最后,初始的queries Q z ∈ R K × C Q_z∈ R^{K×C} Qz∈RK×C 是通过positional embedding 和 class embedding的逐元素添加融合位置和类属性生成的,即 Q z = Q c + µ ^ f ∗ Q_z=Q_c+\hat{µ}^∗_f Qz=Qc+µ^f∗。
然而, µ ^ f \hat{µ}_f µ^f只是一个粗糙的proposal,在推理过程中有时会出错。为使我们的模型对错误的proposal 更健壮,我们引入了一个query增强过程:noisy reference points sampling strategy,仅在训练期间使用,该策略的核心思想是模拟粗糙 proposals µ ^ f \hat{µ}_f µ^f出错的情况,并强制解码器用错误的proposals定位正确的关键点。 具体而言,在训练期间,我们构造了两种类型的关键点queries:第一种类型的关键点 queries 用proposals µ ^ f \hat{µ}_f µ^f 初始化;第二种类型的关键点 queries 用 normalized random 坐标 µ ^ n \hat{µ}_n µ^n(noisy proposal)初始化。然后,在接下来的训练过程中同等处理这两种类型的queries。我们的实验表明,用 noisy proposal µ ^ n \hat{µ}_n µ^n 训练decoder 网络可以提高其对推理阶段由粗糙 proposals µ ^ f \hat{µ}_f µ^f 引入的错误的鲁棒性。注意,在推理过程中,不使用随机初始化的关键点query。
Query decoder. Query decoder中,query 和特征图主要用于模块化关键点和输入图像之间的关系。如图3所示,decoder 遵循典型的 Transformer-decoder 范式,其中 decoder 中有N个相同的层,每个层由self-attention、cross-attention 和前馈网络(FFN)组成。query Q按顺序遍历这些模块,并生成一个 updated Q 作为下一层的输入。与DETR一样,self-attention 和FFN分别是 multi-head self-attention 模块和MLPs。对于cross-attention,我们基于Deformable DETR 提出的MSDA,提出了一种高效多尺度可变形注意力(efficient multi-scale deformable attention :EMSDA)模型。与MSDA类似,在EMSDA中,每个 query 都通过给定参考点周围的 sampling offset(一对坐标,稍后将介绍),学习从特征图中采样相关特征;然后,通过注意力机制总结采样特征以更新query。与MSDA不同,MSDA将线性层应用于整个特征图,因此效率较低,我们发现仅将线性层用于双线性插值后的采样特征就足够了。实验表明,后者性能相当且效率更高。具体而言,EMSDA可以写成:

Q q ∈ R C , p ^ q ∈ R 2 , { x l } l = 1 L Q_q∈ R^C,\hat{p}_q∈ R^2,\{x^l\}^L_{l=1} Qq∈RC,p^q∈R2,{xl}l=1L 是第 q个输入 query vector、第 q 个query的参考点 offset 和 backbone得到的 l-th level特征图的 偏移量;x 中每个特征向量的维数为C。 h e a d i head_i headi 代表第 i 个注意力head。L、 M和S分别表示 decoder 中使用的特征图级别数、注意力头数和每级特征图的采样点数。 A i , l , q , s ∈ R 1 A_{i,l,q,s}∈ R^1 Ai,l,q,s∈R1 和 ∆ p i , l , q , s ∈ R 2 ∆p_{i,l,q,s}∈ R^2 ∆pi,l,q,s∈R2 分别表示第 i 头部、第 l 级别、第 q query、第s采样点的注意力权重和采样offset;query 特征 Q q Q_q Qq 送入线性投影以生成 A i , l , q , s 和∆ p i , l , q , s A_{i,l,q,s} 和 ∆p_{i,l,q,s} Ai,l,q,s和∆pi,l,q,s 。 A i , l , q , s A_{i,l,q,s} Ai,l,q,s 满足限制: ∑ l = 1 L ∑ s = 1 S A i , l , q , s = 1 \sum_{l=1}^L\sum_{s=1}^SA_{i,l,q,s}=1 ∑l=1L∑s=1SAi,l,q,s=1。 Φ l ( ⋅ ) Φ_l(·) Φl(⋅)是将 p ^ q \hat{p}_q p^q转换为 l-th level 坐标系的函数。 x l ( Φ l ( p ^ q ) + ∆ p i , l , q , s ) x^l(Φ_l(\hat{p}_q) + ∆p_{i,l,q,s}) xl(Φl(p^q)+∆pi,l,q,s)表示采样双线性插值特征图 x l x_l xl 上位于 offset ( Φ l ( p ^ q ) + ∆ p i , l , q , s ) (Φ_l(\hat{p}_q) + ∆p_{i,l,q,s}) (Φl(p^q)+∆pi,l,q,s) 的 feature vector。 W o ∈ R C × C 和 W v i ∈ R C × ( C / M ) W^o∈R^{C×C} 和 W_v^i∈R^{C×(C/M)} Wo∈RC×C和Wvi∈RC×(C/M) 是两组可训练的权重。通过在 Q q Q_q Qq 上应用线性层,参考点 p ^ q \hat{p}_q p^q 在每个解码器层的最后更新。注意,FC输出 µ ^ f \hat{µ}_f µ^f被用作初始 query Q z Q_z Qz的参考点。
综上所述,不同关键点间的关系通过自注意力模块建模,输入图像和关键点间关系通过 EMSDA 模块建模。值得注意的是,EMSDA解决了全连接回归中的特征错位(feature misalignment)问题。
3.2 Training Targets and Loss Functions
根据RLE,我们计算一个概率分布 P Θ , Φ ( x ∣ I ) P_{Θ,Φ}(x|I) PΘ,Φ(x∣I) 来反映 GT 出现在输入图像 I 上的位置 x 的概率,其中θ是Poseur的参数,Φ是流模型的参数。如图3(d) 所示,流量模型 f Φ f_Φ fΦ 通过将一个初始分布 ¯ z ∼ N ( 0 , I ) ¯z ∼ N (0, I) ¯z∼N(0,I) 映射为一个zero-mean 复杂分布 ¯ x ∼ G Φ ( ¯ x ) ¯x ∼ G_Φ(¯x) ¯x∼GΦ(¯x) 来反映输出与GT值µg的偏差。给G(¯x)加上一个zero-mean 的拉普拉斯分布 L(¯x) 来获得 P Φ ( ¯ x ) P_Φ(¯x) PΦ(¯x) 。回归模型 θ 预测了分布中心 µ ^ \hat{µ} µ^ 和 scale b ^ \hat{b} b^。最后,分布 P Θ , Φ ( x ∣ I ) P_{Θ,Φ}(x|I) PΘ,Φ(x∣I) 建立在 P Φ ( ¯ x ) P_Φ(¯x) PΦ(¯x) 的基础上,通过将 x shift 和rescal为 x,x = ¯x · ˆσ + ˆµ。请读者参考 RLE 了解更多细节。
与RLE 不同,我们仅使用 proposal (ˆµf , ˆbf )进行粗略预测。然后,通过上述基于 query 的方法更新该预测,以生成改进的估计值( ˆ µq, ˆ bq)。粗糙的 proposal (ˆµf , ˆbf ) 和 query decoder 预测的 ( ˆ µq, ˆ bq)都使用极大似然估计(MLE)进行监督。MLE的学习过程优化了模型参数,以使观测到的GT值µg 可能性最大。FC predictions (ˆµf , ˆbf ) 的 loss定义如下:

其中,θf和Φf分别是 backbone 和流模型的参数。类似地,与 query decoder preditions (ˆµq, ˆbq)分布相关的loss定义为:
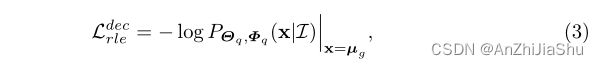
其中,θq和Φq分别是 query 解码器和另一个流模型的参数。最后相加两损失函数得总损失:

λ是一个用于平衡两个损失的常数,默认λ=1。
3.3 Inference
Inference pipeline. 在推理阶段,Poseur 为每个关键点预测 (ˆµq, ˆbq),ˆµq表示预测的关键点坐标,ˆbq用于计算关键点置信度score。
Prediction uncertainty estimation. 对于基于热图的方法,例如SimpleBaseline,每个关键点的预测分数与边界框分数相结合,以提高最终人体实例分数:
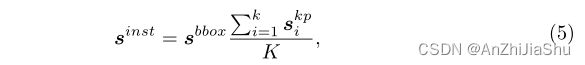
其中 s i n s t s^{inst} sinst 是实例的最终预测分数; s b b o x s^{bbox} sbbox 是人体检测器预测的边界框分数, s i k p s^{kp}_i sikp是关键点检测器预测的第 i 个关键点分数,K是每个人的总关键点数。以往大多数基于回归的方法忽略了关键点得分的重要性,因此,相较于热图法,回归法通常具有较高的召回率,较低的精度。 考虑相同的 well-trained Poseur模型,加上关键点得分显著减少了假阳性数量,带来4.7AP的提升(74.AP vs 70.0AP),而且两种模型的平均召回率(AR)几乎相同。
我们的模型预测了每个人体关键点在图像坐标上的概率分布。 我们将第i 个关键点预测分数 s i k p s^{kp}_i sikp 定义为关键点落入区域 ([ˆµi − a, ˆµi + a]) 的概率,即:

其中,a是控制 µ-adjacent 间隔大小的超参数,ˆµi 是Poseur 预测的相应关键点的坐标。实际上,在推理阶段运行正则化模型会增加更多的计算成本。 我们发现,通过使用 query decoder predictions (ˆµq, ˆbq) shift 并 re-scal zero-mean Laplace distribution L(¯x)可以获得相当的性能,因此,概率密度函数可以改写为:

其中,ˆµi是拉普拉斯分布的中心和预测的关键点坐标,^bi是Poseur预测的scale参数。最后, s i k p s^{kp}_i sikp可以写成:

注意,x轴和y轴上的分数 s i k p s^{kp}_i sikp 将分别计算,然后通过乘法运算合并。
4 Experiments
4.2 Ablation Study
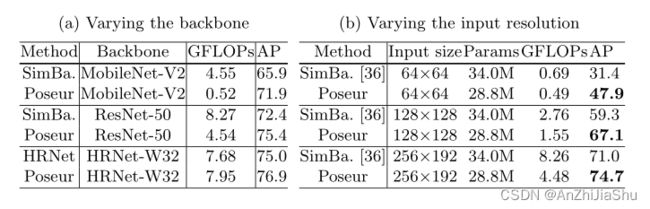
4.3 Extensions: End-to-End Pose Estimation
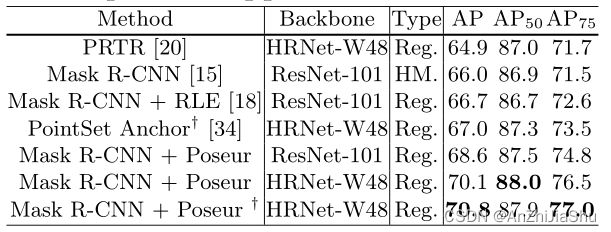
4.4 Main Results

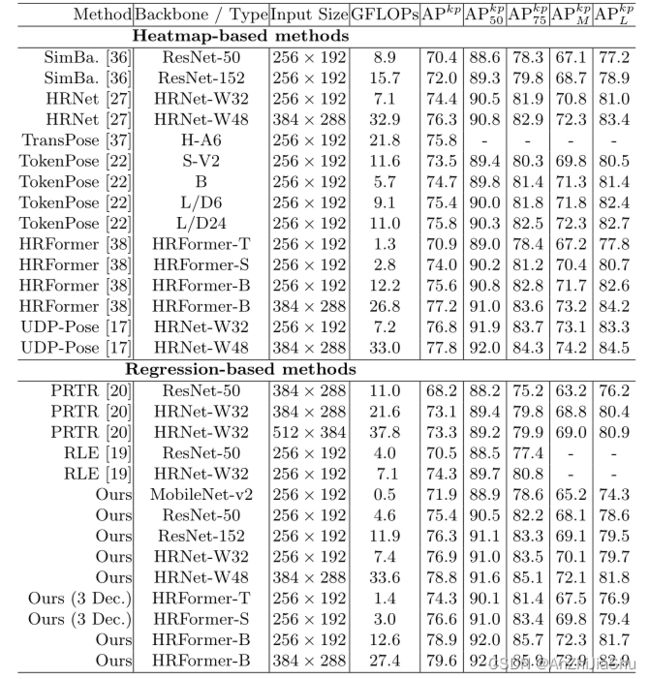

5 Conclusion
我们提出了一种新的基于Transformers的姿态估计框架Poseur,它大大提高了基于回归的姿态估计的性能,并绕过了热图法的缺点,如不可微的后处理和量化误差。MS-COCO 和 MPII上大量实验结果表明,Poseur在回归法和热图法中都能达到sota性能。
6 Additional Results
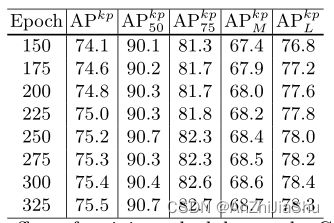
6.1 The Effect of Training Schedules
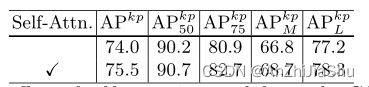
6.2 The Effect of Self-attention


6.3 Reducing the Number of Parameters

6.4 Computational Cost of EMSDA

6.5 Comparing the Performance of Poseur and RLE

6.6 Verifying the Effect of Keypoint Encoder and Query Decoder in Poseur 略
6.7 The Explanation of the Positional Encoding in Keypoint Encoder 略
6.8 Robustness to Truncation 略