YOLOF训练自己的数据集(目标检测,cvpods版本)
训练准备:
github repo地址:https://github.com/megvii-model/YOLOF
github上有两个版本,一个是cvpods,一个是detectron2,第二个我每次运行都报AssertionError: bad box: x1 larger than x2,说是调小学习率,后来一直也没跑成功,精度也不正常,就放弃了,转到cvpods版本了
我也是初学刚接触,看不懂网上的注册数据集,就是运行的时候哪里报错哪里改代码,有专业的还请多多指正
前提是你已经把你的数据集转换成coco形式了,我在这里给出一个转换后的例子,只有一个waste类,从0开始标记
我是从yolo格式转到coco,github repo使用的是:DL_tools/yolo2coco.py at main · Weifeng-Chen/DL_tools · GitHub
{
"categories": [
{
"id": 0,
"name": "waste",
"supercategory": "mark"
}
],
"annotations": [
{
"area": 21344.000000000004,
"bbox": [
493.0,
9.999999999999996,
232.0,
92.00000000000001
],
"category_id": 0,
"id": 0,
"image_id": 0,
"iscrowd": 0
},
...
],
"images": [
{
"file_name": "0071.jpg",
"id": 0,
"width": 1600,
"height": 900
},
...
]
}我使用的是单类数据集,要注意的是,我是从0开始标记物体的,如果是从1开始标记物体的,那么0就是background,具体看这篇CSDN中 “注册自己的数据集” 这部分
Detectron2训练自己的数据集(较详细)_qq_29750461的博客-CSDN博客_detectron2训练自己的数据集
默认你已经安装好README.md里所有环境了
默认在你的根目录下有datasets,你已经用ln -s链接数据集过了,我这边取名为coco
另外我这边还下载了预训练权重,loss会损失地快一点,我这边用到的模型是YOLOF_R50_C5_1x,没有用他默认给的detectron2://ImageNetPretrained/MSRA/R-50.pkl

然后开始修改部分代码,以下代码所在行数,根据你使用的模型代码而定,其实你可以修改每一个步骤就执行一遍训练的命令,哪里报错就改哪里。全改完了跑起来还是报错,就看看有没有kennel漏改的地方(学习率,类别数等等)
训练过程:
1、 修改权重路径
到playground/detection/coco/yolof/yolof.res50.C5.1x/config.py Line 6,确保预训练权重名和你下载的一样
WEIGHTS="../../../../../pretrained_models/YOLOF_R50_C5_1x.pth",2、修改参数
我是单卡,只有一个gpu,原来的模型是在8个gpu上跑的,需要修改batch,steps,warmup等参数设置,跑失败了我再调整参数,调参真的是件很痛苦的事,我也没什么技巧和经验,在这里简单说一下我是按照什么规则调的,具体还要看你们机器
到playground/detection/coco/yolof/yolof.res50.C5.1x/config.py Line 66-67,调整IMS_PER_BATCH=64, IMS_PER_DEVICE=8,原来的batch是64,有8张卡,所以一张卡是8个batch。但是我只有一个卡,我调成了4,再跑不起来,就再以2的倍数调小,2、1。。
IMS_PER_BATCH=4,
IMS_PER_DEVICE=4,3、修改训练类别
这一部分就是你训练的时候也不会显示报错,但是最后测试的时候会出错的地方,在训练之前就要设置好
到playground/detection/coco/yolof/yolof.res50.C5.1x/config.py Line 24,NUM_CLASSES=80换成你数据集中的类别数,我这里是1

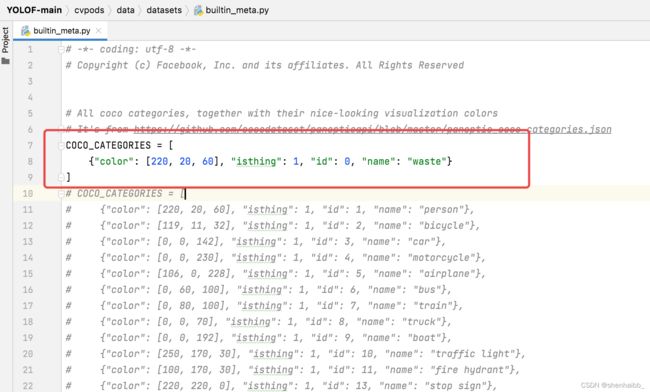
到cvpods/data/datasets/builtin_meta.py Line 7,注释掉原来的COCO_CATEGORIES,设置为你数据集中的种类,我这里只有一个类别waste,并且我第id是从0开始,这要看你的json是怎样设置的了,我的json是从0开始计数类别
COCO_CATEGORIES = [
{"color": [220, 20, 60], "isthing": 1, "id": 0, "name": "waste"}
]
3、最后执行运行命令:
pods_train --num-gpus 1出现以下类似界面不中断就已经跑起来了
 训练到迭代5000次的时候代码会保存一个checkpoint,设置的地方在cvpods/configs/base_config.py,Line 140
训练到迭代5000次的时候代码会保存一个checkpoint,设置的地方在cvpods/configs/base_config.py,Line 140
CHECKPOINT_PERIOD=5000这里放一个我训练到5000次的截图,可以看到加载了预训练模型后,loss收敛的速度还是较快的
训练结果:
执行命令验证一下模型的精确度:
pods_test --num-gpus 1 MODEL.WEIGHTS output/model_iter_0005000.pth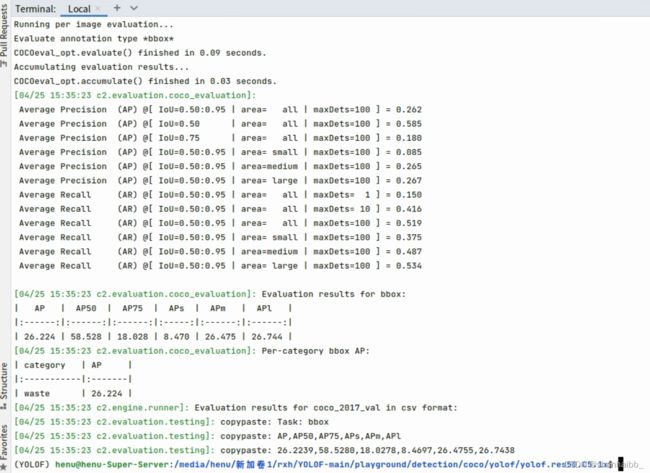
精度还是差点,因为没训练完 回头跑完
-------------------------------------------- 华丽的分割线 --------------------------------------------
跑完了,最终的效果还是不错的
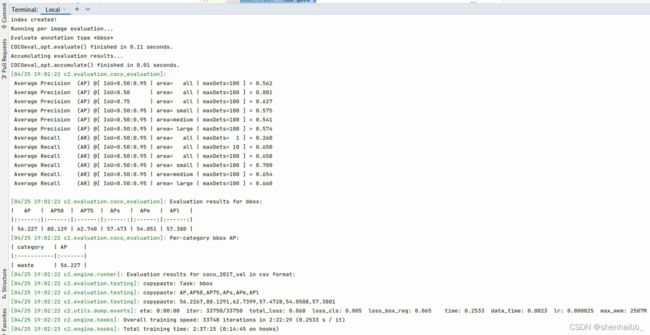
可能报错的地方:
1、RuntimeError: Default process group has not been initialized, please make sure to call init_process_group
解决方法:到playground/detection/coco/yolof/yolof_base/yolof.py Line 7,下添加以下代码:
dist.init_process_group('gloo', init_method='file:///tmp/somefile', rank=0, world_size=1)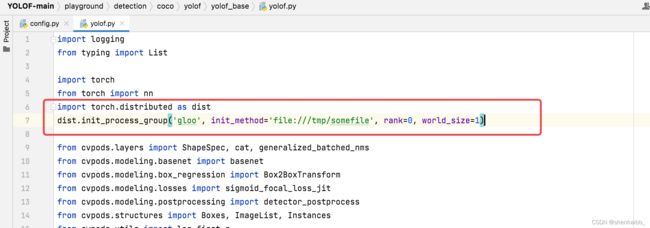
或者把模型中包含SyncBN的地方都换成BN
2、RuntimeError: CUDA out of memory. Tried to allocate 234.00 MiB (GPU 0; 7.79 GiB total capacity; 5.79 GiB already allocated; 108.25 MiB free; 5.83 GiB reserved in total by PyTorch)
解决方法:到playground/detection/coco/yolof/yolof.cspdarknet53.DC5.3x/config.py,把该页面下所有的SyncBN都换成了BN
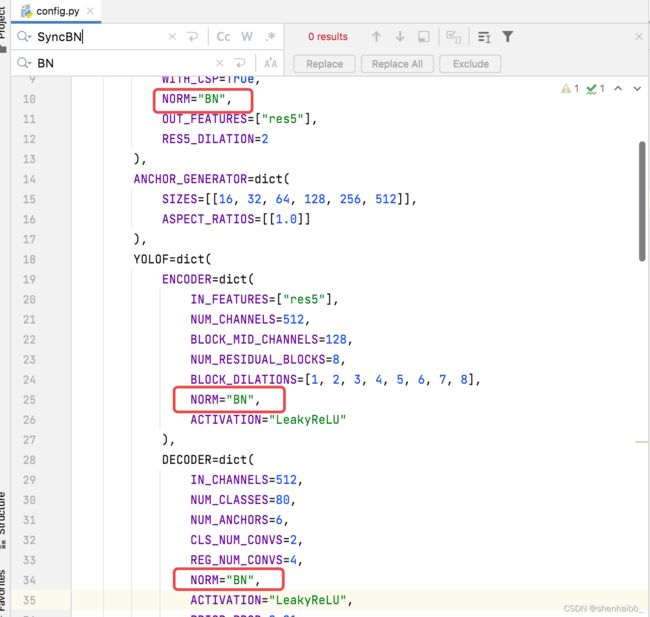
或者减小batch,或者看看有没有其他进程占用了
3、AssertionError: IMS_PER_BATCH/DEVICE in config file is used for 8 GPUs
解决方法:到cvpods/engine/setup.py Line 84,注释这一句
# AssertionError: IMS_PER_BATCH/DEVICE in config file is used for 8 GPUs4、AssertionError: Box regression deltas become infinite or NaN!
解决方法:需要修改参数,我认为出现这个错就是降低学习率,出现精度有差距,就加大迭代次数
到你模型的config文件下,我使用的模型对应的py路径是playground/detection/coco/yolof/yolof.res50.C5.1x/config.py
Line 50开始的SOLVER部分,需要注意的几个参数(我自认为需要调整的参数,有其他的可以补充,还有也具体调整多少还是看机器,一个个试看怎样才能跑起来)
参考github issue:Cannot get the AP result in the paper · Issue #37 · megvii-model/YOLOF · GitHub
前面说到”原来的batch是64,有8张卡,所以一张卡是8个batch,但是我只有一个卡,我调成了4“,所以相比之前我缩小到了一半的batch,所以参数都是按照1/2的比例放大缩小,要是太大或太小自己可以再调整,以最终跑起来为主

5、assert len(thing_ids) == 80, len(thing_ids) AssertionError: 1
解决方法:到cvpods/data/datasets/builtin_meta.py下
Line 194:把80换成你的类别数
assert len(thing_ids) == 1, len(thing_ids)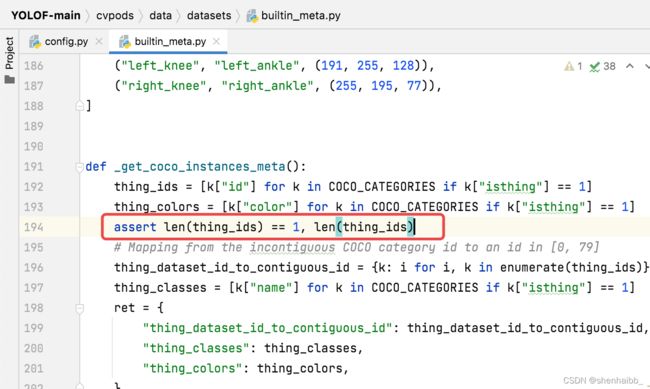
6、执行运行命令没反应

解决方法:之前在playground/detection/coco/yolof/yolof_base/yolof.py Line 7加了下面的代码,
dist.init_process_group('gloo', init_method='file:///tmp/somefile', rank=0, world_size=1)先注释上面这个代码,注释后再运行,运行报错后再添加(我感觉这个命令是不是设置了之后,只能初始化下一次的程序运行,每次跑都要再初始化一次,有效性只有一次??)
更新:后来我发现程序顺利跑完之后,就不需要注释再运行,可能之前是因为程序意外中断的,导致没有及时销毁吧
更新:后来我又发现再怎么经过这个操作都不行了,我就重启了一下电脑,又可以了,我怀疑是初始化太多次了,而每次结束后都没销毁,所以重启之后就好了,如果注释后再添加不行,就试试重启
以上