学习笔记 |《白话机器学习的数学》
一、开始二人之旅
机器学习擅长的三个任务:
- 回归(regression):处理连续数据如时间序列数据时使用
- 分类(classification):只有两个类别的问题称为二分类,有三个及以上的问题称为多分类
- 聚类(clustering):与分类的区别在于数据带不带标签
二、学习回归——基于广告费预测点击量
2.1 设置问题
根据广告费预测点击量
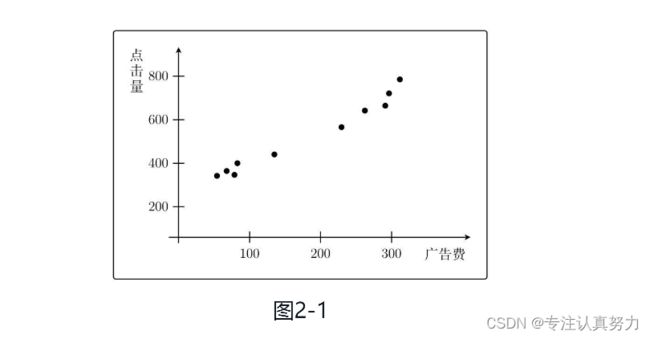
2.2 定义模型

2.3 最小二乘法
目的:寻找合适的参数使得误差之和为最小

假设有n个训练数据,那么它们的误差之和可以用这样的表达式表示。这个表达式称为目标函数,E(θ)的E是误差的英语单词Error的首字母。
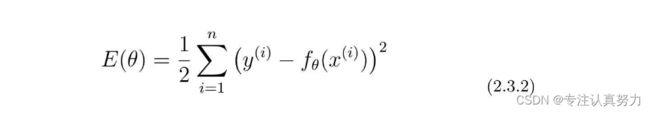
注:x(i)和y(i)中的i不是i次幂的意思,而是指第i个训练数据
为什么要计算误差的平方呢?
误差可能为负值,正负相抵为0,而不使用绝对值是因为绝对值不方便微分,相比而言平方的微分更加简单。
为什么整个表达式还要乘以1/2
微分之后会使表达式更加简单方便,并且这个常数并不影响函数本身取最小值的点的大小
2.3.1 最速(梯度)下降法
目的:在二次函数中,移动x使得g(x)一直变小.
只要向与导数的符号相反的方向移动x,g(x)就会自然而然地沿着最小值的方向前进。

η称为学习率的正的常数,根据学习率的大小,到达最小值的更新次数也会发生变化。换种说法就是收敛速度会不同。有时候甚至会出现完全无法收敛,一直发散的情况。
fθ(x)拥有θ0和θ1两个参数。也就是说这个目标函数是拥有θ0和θ1的双变量函数,所以不能用普通的微分,而要用偏微分。如此一来,更新表达式就是这样的。

使用复合函数的微分,E(θ)中有fθ(x),而fθ(x)中又有θ0,所以我们可以这样分别去考虑它们。

阶梯性地进行微分。
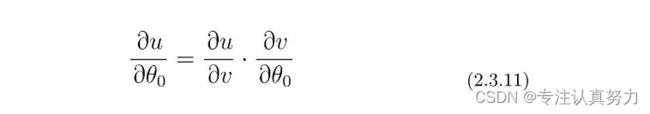
先从u对v微分的地方开始计算。

下面就是v对θ0进行微分的部分了。
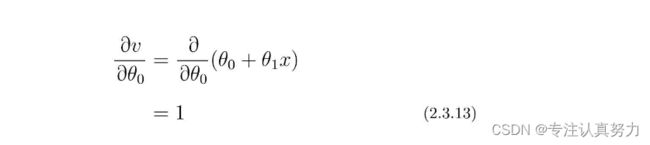
让各部分相乘。
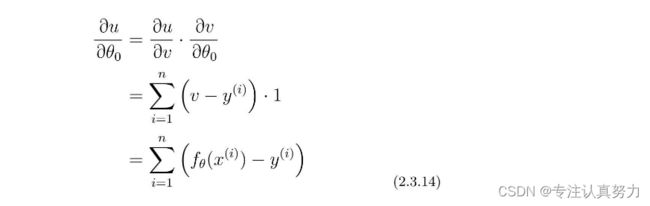
同理得u对θ1的微分。

综上。

2.4 多项式回归
使用曲线拟合。
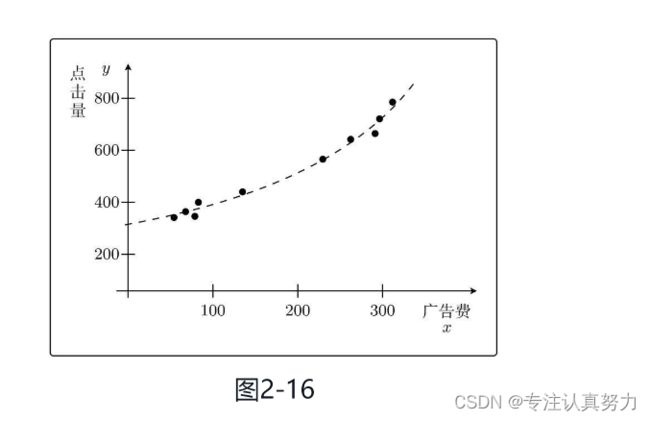
使用二次函数进行拟合。

参数更新。
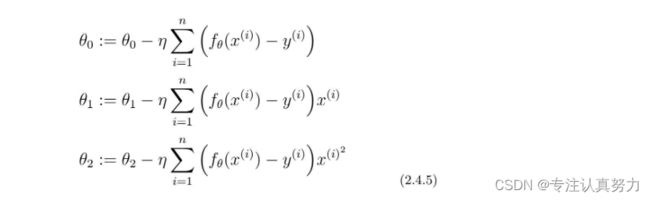
2.5 多重回归
包含了多个变量的回归称为多重回归。
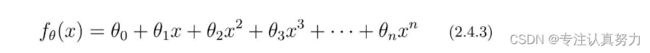
把θ和x用列向量来定义。

把二者相应的元素相乘,然后全部加起来。
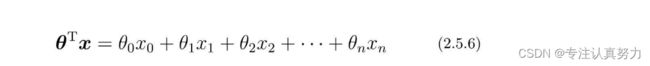
表达式简化。

考虑对第j个元素θj偏微分的表达式。

u对v微分的部分是一样的,所以只需要求v对θj的微分。

第j个参数的更新表达式。

2.6 随机梯度下降法
解决梯度下降法的缺陷:容易陷入局部最优解

最速下降法的参数更新表达式。
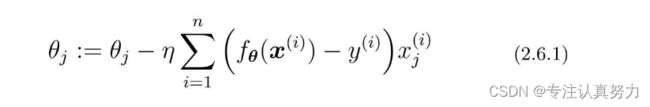
随机梯度下降法中会随机选择一个训练数据,并使用它来更新参数。这个表达式中的k就是被随机选中的数据索引。

三、学习分类——基于图像大小进行分类
3.1 设置问题

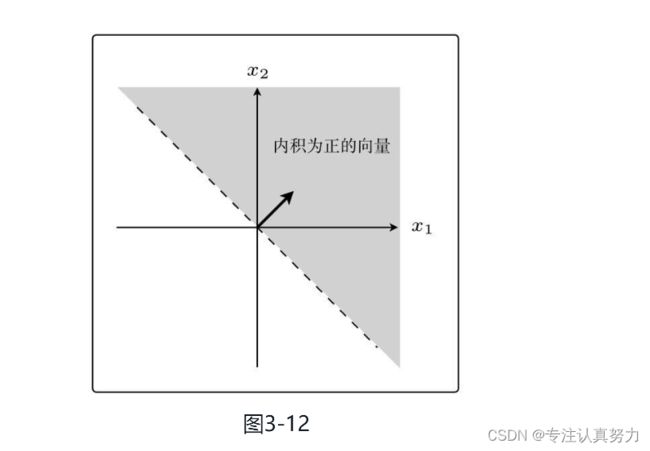
3.2 内积
法线是与某条直线相垂直的向量。

权重向量为w=(1,1)

确定的权重向量w=(1,1)

找到与我画的直线成直角的权重向量。

3.3 感知机
感知机是接受多个输入后将每个值与各自的权重相乘,最后输出总和的模型。

根据参数向量x来判断图像是横向还是纵向的函数,即返回1或者-1的函数fw(x)的定义如下。这个函数被称为判别函数。
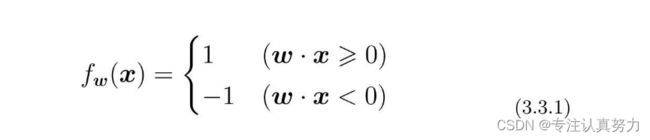
内积是衡量向量之间相似程度的指标。结果为正,说明二者相似;为0则二者垂直;为负则说明二者不相似。
与权重向量w之间的夹角为θ,在90◦<θ<270◦范围内的所有向量都符合条件,即内积为负

同理得另一部分则为正。
训练数据。

判别函数。
权重向量的更新表达式,用这个表达式重复处理所有训练数据,更新权重向量。

当判别函数与标签值不同时,说明判断函数分类失败,需要更新权重向量;
当判别函数与标签值相同时,说明判断函数是正确的,不需要更新权重向量。
权重向量是通过随机值来初始化的。

在这个状态下,假设第一个训练数据是x(1)=(125,30);
现在权重向量w和训练数据的向量x(1)二者的方向几乎相反,w和x(1)之间的夹角θ的范围是90◦<θ<270◦,内积为负。也就是说,判别函数fw(x(1))的分类结果为-1;
训练数据x(1)的标签y(1)是1,所以fw(x(1))=y(1)说明分类失败。

现在y(1)=1,所以更新表达式是这样的,其实就是向量的加法。


刚才x(1)与权重向量分居直线两侧,现在它们在同一侧了。
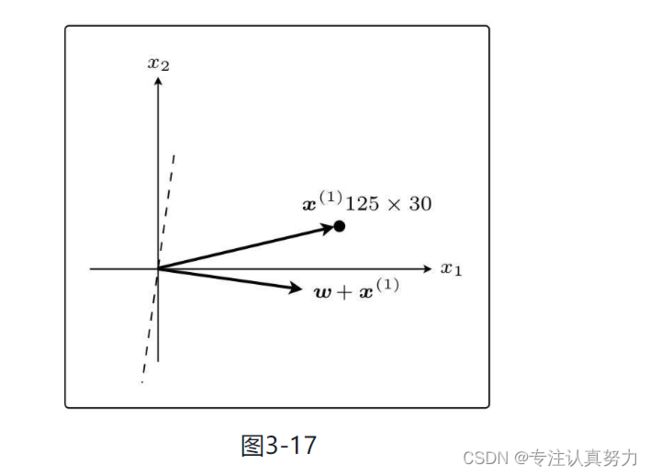
现在θ<90◦,所以内积为正,判别函数fw(x)的分类结果为1。而且x(1)的标签也为1,说明分类成功了。
3.4 线性可分
感知机的缺点:它只能解决线性可分的问题。
线性不可分的分类问题:不能用直线分类的分类问题。

感知机也被称为简单感知机或单层感知机,实际上多层感知机就是神经网络。
3.5 逻辑回归
把分类作为概率来考虑的;设横向的值为1、纵向的值为0。
能够将未知数据分类为某个类别的判别函数fθ(x)。

sigmoid函数。
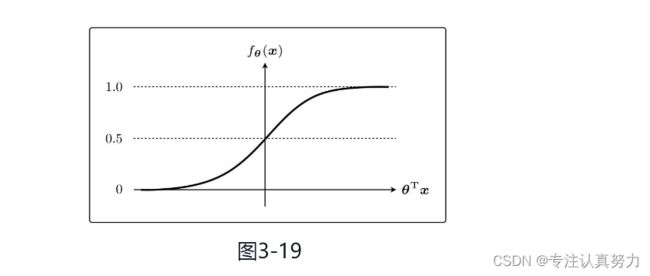
用概率来考虑分类。因为sigmoid函数的取值范围是0<fθ(x)<1,所以它可以作为概率来使用。

使用0.5作为分类阈值,根据判别函数返回的值对数据进行分类。

改写判别函数为如下等价形式。
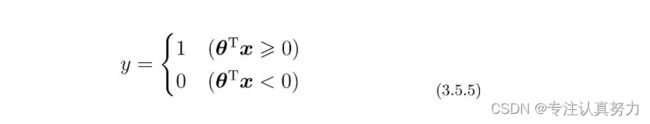
当θ是这样的向量时,我们来画一下θTx≥0的图像。
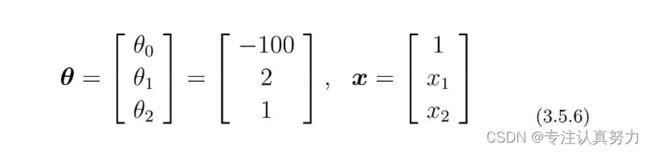
先代入数据,把表达式变为容易理解的形式。
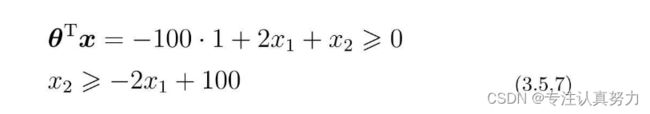

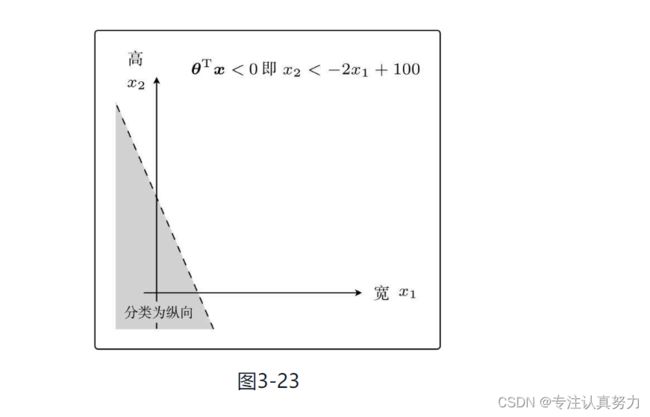
将θTx=0这条直线作为边界线,就可以把这条线两侧的数据分类为横向和纵向了。
这样用于数据分类的直线称为决策边界。

接下来 为了求得正确的参数θ而定义目标函数,进行微分,然后求参数的更新表达式。
3.6 似然函数


假定所有的训练数据都是互不影响、独立发生的,这种情况下整体的概率就可以用下面的联合概率来表示。

联合概率的表达式是可以一般化的,写法如下。
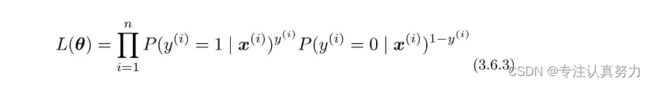
首先向指数y(i)代入1。

然后向指数y(i)代入0。
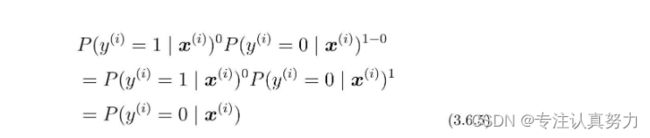
由此可知:可以将取值0或1的两种情况利用任何数字的0次方都是1的特性进行统一为一个公式。
回归的时候处理的是误差,所以要最小化,而现在考虑的是联合概率,我们希望概率尽可能大,所以要最大化。
目标函数L(θ)也被称为似然,函数的名字L取自似然的英文单词Likelihood的首字母。
可以认为似然函数L(θ)中,使其值最大的参数θ能够最近似地说明训练数据。
3.7 对数似然函数
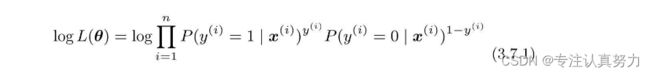
由于log是单调递增函数,现在考察的似然函数也是在L(θ1)<L(θ2)时,有log L(θ1)<log L(θ2)成立。也就是说,使L(θ)最大化等价于使log L(θ)最大化。

每一行的变形分别利用了下面这些特性。

逻辑回归将这个对数似然函数用作目标函数。
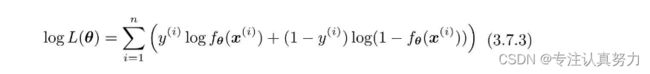
接下来,对各个参数θj求微分。
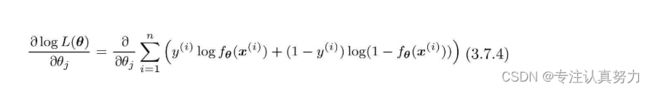
和回归的时候是一样的,我们把似然函数也换成这样的复合函数,然后依次求微分。

阶梯式求复合函数偏微分。

求u对v的微分。

求解结果。

求v对θj的偏微分。

已知sigmoid函数的微分如下。

设z=θTx,然后再一次使用复合函数的微分会比较好。
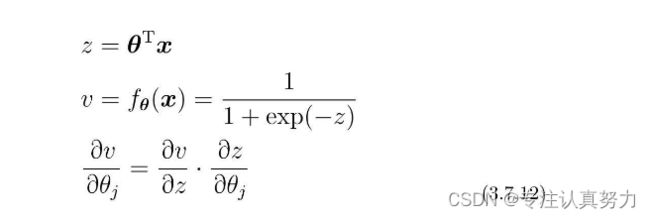
由sigmoid函数的微分可得。

z对θj的微分。

把结果相乘得到v对θj的偏微分公式。
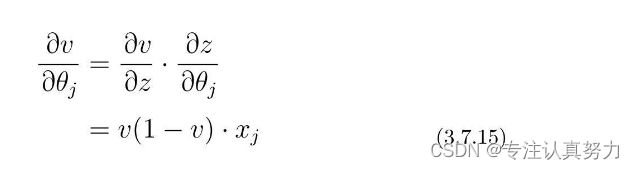
代入各个结果,然后通过展开、约分,使表达式变得更简洁。

接下来要做的就是从这个表达式导出参数更新表达式。不过现在是以最大化为目标,所以必须按照与最小化时相反的方向移动参数。
即最小化时要按照与微分结果的符号相反的方向移动,而最大化时要与微分结果的符号同向移动。

为了与回归时的符号保持一致,也可以将表达式调整为下面这样。注意,η之前的符号和∑中的符号反转。
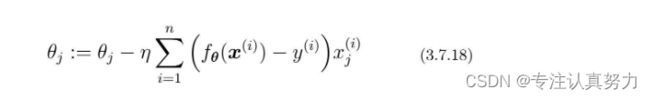
3.8 线性不可分
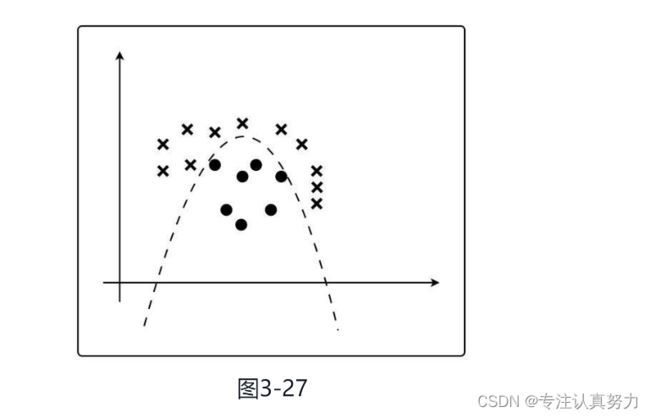
将逻辑回归应用于线性不可分问题。

对于这个例子来说,虽然用直线不能分类,但是用曲线可以进行分类。
向训练数据中加入x12,考虑这样的数据。
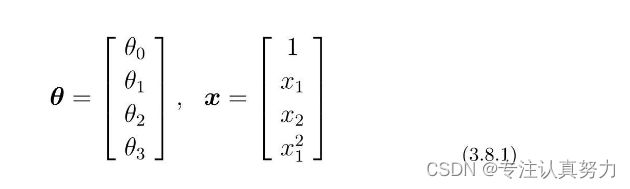
展开。

假设θ是这样的向量。

考虑θTx≥0的图形。


之前的决策边界是直线,现在则是曲线了。因为参数θ是随便定的,所以数据完全没有被正确地分类。
四、评估——评估已建立的模型
4.2.1 回归问题的验证
把获取的全部训练数据分成两份:一份用于测试,一份用于训练。然后用前者来评估模型。
模型评估就是像这样检查训练好的模型对测试数据的拟合情况。
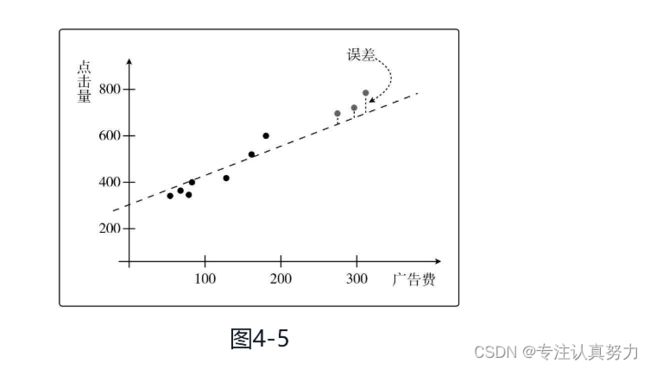
对于回归的情况,只要在训练好的模型上计算测试数据的误差的平方,再取其平均值就可以了。假设测试数据有n个,那么可以这样计算。

这个值被称为均方误差或者MSE,全称Mean Square Error(图4-5)。这个误差越小,精度就越高,模型也就越好。
4.2.2 分类问题的验证
分类结果为正的情况是Positive、为负的情况是Negative。分类成功为True、分类失败为False。

使用表里的4个记号来计算分类的精度,它表示的是在整个数据集中,被正确分类的数据TP和TN所占的比例。
用测试数据来计算这个值,值越高精度越高,也就意味着模型越好。
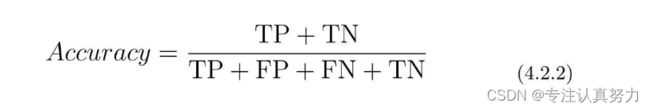
4.2.3 精确率和召回率
一般来说,只要计算出这个Accuracy值,基本上就可以掌握分类结果整体的精度了。但是有时候只看这个结果会有问题,所以还有别的指标。
考虑一下数据量极其不平衡的情况,只看整体的精度看不出来问题。
首先我们来看第一个指标——精确率。它的英文是Precision。
它的含义是在被分类为Positive的数据中,实际就是Positive的数据所占的比例。

还有一个指标是召回率,英文是Recall。
它的含义是在Positive数据中,实际被分类为Positive的数据所占的比例。

4.2.4 F值
一般来说,精确率和召回率会一个高一个低,需要我们取舍,有些麻烦。
所以就出现了评定综合性能的指标F值。表达式4.2.8中的Fmeasure就是F值,Precision是前面说的精确率,Recall是召回率。

F值的特点是:精确率和召回率只要有一个低,就会拉低F值。
这说明该指标考虑到了精确率和召回率的平衡。
有时称F值为F1值会更准确,除F1值之外,还有一个带权重的F值指标。
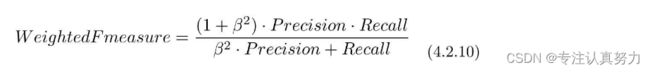
可以认为F值指的是带权重的F值,当权重为1时才是刚才介绍的F1值。
F1值在数学上是精确率和召回率的调和平均值。
之前介绍的精确率和召回率都是以TP为主进行计算的,也可以以TN为主。

当数据不平衡时,使用数量少的那个会更好。最开始的例子中Positive极少,所以我们使用了Positive来计算,反之如果Negative较少,那就使用Negative。
对于回归和分类,我们都可以这样来评估模型。
把全部训练数据分为测试数据和训练数据的做法称为交叉验证。这是非常重要的方法。
交叉验证的方法中,尤为有名的是K折交叉验证。

假如我们要进行4折交叉验证,那么就会这样测量精度。

4.3 正则化
模型只能拟合训练数据的状态被称为过拟合,英文是overfitting。
过度增加函数fθ(x)的次数会导致过拟合。
有几种方法可以避免过拟合。

对于回归问题的目标函数进行正则化。

向这个目标函数增加下面这样的正则化项。

对这个新的目标函数进行最小化,这种方法就称为正则化。
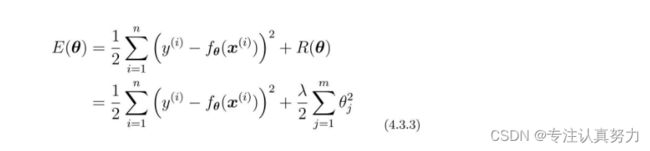
m是参数的个数。
一般来说不对θ0应用正则化。所以仔细看会发现j的取值是从1开始的。 这也就是说,假如预测函数的表达式为fθ(x)=θ0+θ1x+θ2x2,那么m=2就意味着正则化的对象参数为θ1和θ2。
θ0这种只有参数的项称为偏置项,一般不对它进行正则化。
λ是决定正则化项影响程度的正的常数。这个值需要我们自己来定。
首先把目标函数分成两个部分。

C(θ)是本来就有的目标函数项,R(θ)是正则化项。
C(θ)和R(θ)相加之后就是新的目标函数,所以我们实际地把这两个函数的图形画出来,加起来看看。不过参数太多就画不出图来了,所以这里我们只关注θ1。而且为了更加易懂,先不考虑λ。
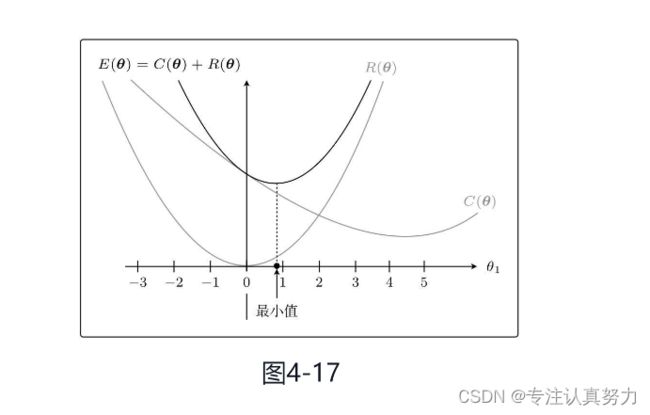
正则化后,目标函数的θ1更接近0。
这就是正则化的效果。它可以防止参数变得过大,有助于参数接近较小的值。虽然我们只考虑了θ1,但其他θj参数的情况也是类似的。
参数的值变小,意味着该参数的影响也会相应地变小。
比如二次函数的的二次项系数为0的话,就会退化为一条直线,这正是通过减小不需要的参数的影响,将复杂模型替换为简单模型来防止过拟合的方式。
总之就是为了防止参数的影响过大,在训练时要对参数施加一些惩罚。一开始就提到的λ,是可以控制正则化惩罚的强度。
比如令λ=0,那就相当于不使用正则化; 反过来λ越大,正则化的惩罚也就越严厉。
刚才讨论的是回归的情况,对于分类也可以应用正则化。
对于分类问题的目标函数:对数似然函数。
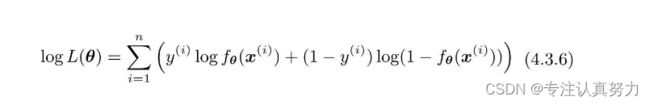
分类也是在这个目标函数中增加正则化项。

对数似然函数本来以最大化为目标。但是,这次我想让它变成和回归的目标函数一样的最小化问题,所以加了负号。这样就可以像处理回归一样处理它,所以只要加上正则化项就可以了。
总之反转符号是为了将最大化问题替换为最小化问题。
反转了符号之后,在更新参数时就要像回归一样,与微分的函数的符号反方向移动才行。
刚才我们把回归的目标函数分成了C(θ)和R(θ)。这是新的目标函数的形式,我们要对它进行微分。

对各部分进行偏微分。

对于左边部分前面已经求得,我们重点求右边部分。
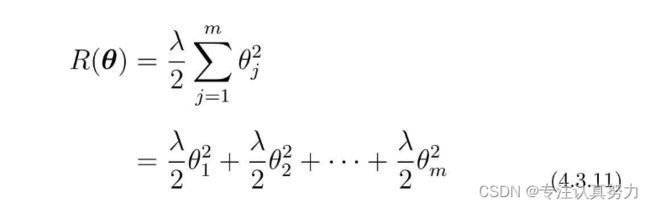

左右两边相加。
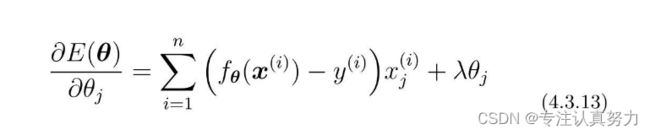
由于一般不对θ0应用正则化,R(θ)对θ0微分的结果为0。所以实际上我们需要像这样区分两种情况。

同理,对于逻辑回归。
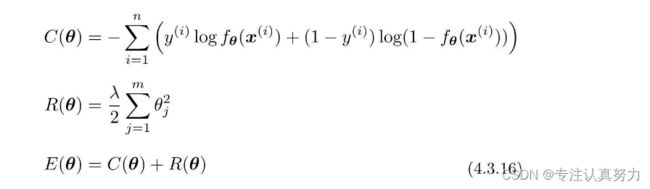
参数更新公式结果与回归问题的相同。
刚才我介绍的方法其实叫L2正则化。
除L2正则化方法之外,还有L1正则化方法。它的正则化项R是这样的。

L1正则化的特征是被判定为不需要的参数会变为0,从而减少变量个数。而L2正则化不会把参数变为0。
L2正则化会抑制参数,使变量的影响不会过大,而L1会直接去除不要的变量。
4.4 学习曲线
欠拟合是与过拟合相反的状态,所以它是没有拟合训练数据的状态。
将两份数据的精度用图来展示后,如果是这种形状,就说明出现了欠拟合的状态。也有一种说法叫作高偏差。
这是一种即使增加数据的数量,无论是使用训练数据还是测试数据,精度也都会很差的状态
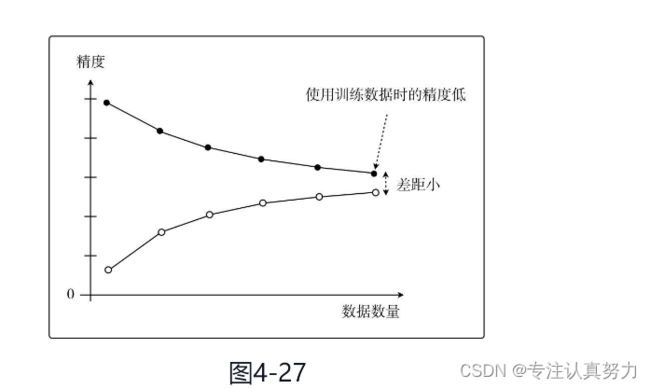
而在过拟合的情况下,图是这样的。这也叫作高方差。随着数据量的增加,使用训练数据时的精度一直很高,而使用测试数据时的精度一直没有上升到它的水准。
只对训练数据拟合得较好,这就是过拟合的特征。

通过学习曲线判断出是过拟合还是欠拟合之后,就可以采取相应的对策以便改进模型了。