PyTorch学习笔记(七)------------------ Vision Transformer
目录
一、Patch and Linear map
二、Adding classification token
三、Positional encoding
四、LN, MSA and Residual Connection
五、LN、MLP and Residual Connection
六、Classification MLP
前言:vision transformer(vit)自Dosovitskiy等人介绍以来,一直在计算机视觉领域占主导地位,在分类中的大多数情况超过了传统的卷积神经网络(cnn)Transformer的刚提出其实是在自然语言处理(NLP)领域,而vit的整个思路与NLP大差不异,它是将一张完整的图片分为几个token,再将这些token输入到网络中,类似于NLP中语句的输入,这些被分开的token就相当于每一个小单词
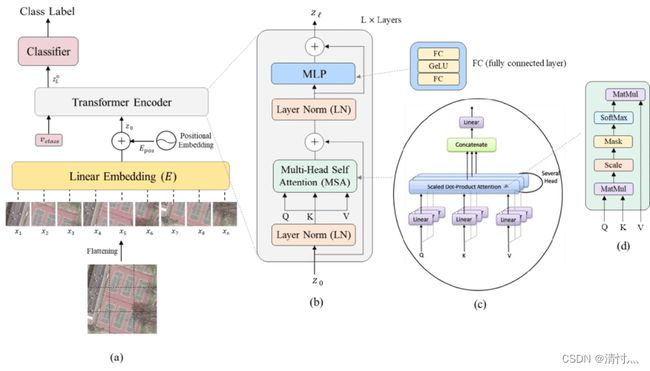
这是在Vision Transformers for Remote Sensing Image Classification中发表的图片,我来借用一下
通过这张图片,可以看到a被分开成从x1-x9 9张图片,并且它们是等长的。这些子图像都经过线性嵌入,这些子图像现在只是一个一维向量,同时也可以看到这些图片从x1-x9是按顺序从原图片上分开的,这点很重要,之后,在这些token也就是向量中加入位置信息,网络通过这些子图才能还原出图片原本的样子
嵌入位置信息后,这些tokens和一个用于分类的token一起传入到transformer encoder中,这也就是为什么在传入数据的时候会+1,这个1就是分类token。在这个transformer encoder中含有一层归一化(LN),多头自注意力(MSA)和一个残差连接(resdiual connection),然后再来第二个LN,一个多层感知器(MLP),一个残差。一般来说,encoder里面的块可以重复多次,类似于Resnet。最后,一个用于分类的MLP块来对当初传入的特殊分类标记进行分类,就是一个分类的玩意。
现在回过头看上面的图,是不是感觉思路通畅一点了
一、Patch and Linear map
首先第一个问题就是如何将一张图片变为类似于一个英语句子,作者的方法是将其分为多个子图,并按照位置序列映射到向量上面
举个例子,这里有一张3*224*224的图片(3是通道数 RGB)我们可以把它分成14*14的patch,每一个patch大小为16*16
(N,C,H,W)→(N, 3, 224, 224)→ (N, pathes, patch_dim) → (N, 14*14, 16*16)
现在输入的3*224*224的图片就变为 (196, 256),每个patch的维度是16*16,我们现在的patch就可以通过线性映射来反馈出每一个子图片,并且,线性映射可以映射到任意的向量,称之为隐藏维度,再这里,我们可以将256 映射为 8 256→8,注意映射的维度要可以整除
二、Adding classification token
之前说 在tokens传入transformer encoder中时要加入一个分类token,它的作用是捕捉关于其他标记的信息,这会在MSA中发生。当所有图像传入完成后,我们可以仅仅使用这一个classification token来对图像进行分类
还是刚刚3*224*224的例子,上面说到
(N, 196, 256)→(N, 196+1, 256)
这边加的1就是分类token
三、Positional encoding
当网络接受到这每一个patch输入,它是如何知道每一个patch在原始图像中的位置的呢
Vaswani等人的研究表明,可以只用添加正弦波和余弦波来实现这一点
同时,标记大小为(N, 197, 256)前面的N就是将(197, 256)这个位置编码重复N次
四、LN, MSA and Residual Connection
LN:给定一个输入,减去其平均值并除以标准差
MSA:将每一个patch映射到3个不同向量:q,k and v,映射之后,通过q与k之间的点乘再除以dim的平方根,softmax这些结果(注意力点),最后将每个注意力线索与v相乘,最后相加(感觉很枯燥)
同时,对每个自注意力头数创建不同的Q,K,V映射函数
还是用例子来说明
(N, 197, 256)→(N, 197, 16, 16)→ nn.Linear(16, 16) → (N, 197, 256)
输入的是(N, 197,256),通过多头注意力(这里用了16个头)将向量变为(N, 197, 16, 16),此时还需要一个nn.Linear(16, 16)来将其映射成(N, 197, 256)
Residual Connection:残差
之前说过在传入transformer encoder时会加入一个classification token,那这些token是如何获取其他token的信息呢,在经过LN,MSA和残差操作后,这个classification token就有了关于其他token的信息。
五、LN、MLP and Residual Connection
之前提到在transformer enconder块中第一步加入LN, MSA和残差,在这里是第二步,加入LN、 MLP 和 残差
六、Classification MLP
在经过一系列操作后,我们的网络有很多权重指数和数据,在MLP中,我们可以从N个序列中只提取分类标记(token),并使用token来获得分类
例如,之前我们选择的每一个token是16dim的向量,要分的类是5类,我们可以用MLP创建一个16*5的矩阵,并用softmax函数激活
整个vit网络的构建至此已经全部结束
PY代码如下
class MyViT(nn.Module):
def __init__(self, input_shape, n_patches=14, hidden_d=8, n_heads=2, out_d=5, device=None):
super(MyViT, self).__init__()
self.device = device
self.input_shape = input_shape
self.n_patches = n_patches
self.n_heads = n_heads
assert input_shape[1] % n_patches == 0,
assert input_shape[2] % n_patches == 0,
self.patch_size = (input_shape[1] / n_patches, input_shape[2] / n_patches)
self.hidden_d = hidden_d
# 1) Linear mapper
self.input_d = int(input_shape[0] * self.patch_size[0] * self.patch_size[1])
self.linear_mapper = nn.Linear(self.input_d, self.hidden_d)
# 2) Classification token
self.class_token = nn.Parameter(torch.rand(1, self.hidden_d))
# 3) Positional embedding
# (In forward method)
# 4a) Layer normalization 1
self.ln1 = nn.LayerNorm((self.n_patches ** 2 + 1, self.hidden_d))
# 4b) Multi-head Self Attention (MSA) and classification token
self.msa = MyMSA(self.hidden_d, n_heads)
# 5a) Layer normalization 2
self.ln2 = nn.LayerNorm((self.n_patches ** 2 + 1, self.hidden_d))
# 5b) Encoder MLP
self.enc_mlp = nn.Sequential(
nn.Linear(self.hidden_d, self.hidden_d),
nn.ReLU()
)
# 6) Classification MLP
self.mlp = nn.Sequential(
nn.Linear(self.hidden_d, out_d),
nn.Softmax(dim=-1)
)
def forward(self, images):
n, c, w, h = images.shape
patches = images.reshape(n, self.n_patches ** 2, self.input_d)
tokens = self.linear_mapper(patches)
tokens = torch.stack([torch.vstack((self.class_token, tokens[i])) for i in range(len(tokens))])
tokens += get_positional_embeddings(self.n_patches ** 2 + 1, self.hidden_d).repeat(n, 1, 1).to(self.device)
out = tokens + self.msa(self.ln1(tokens))
out = out + self.enc_mlp(self.ln2(out))
out = out[:, 0]
return self.mlp(out)
def get_positional_embeddings(sequence_length, d):
result = torch.ones(sequence_length, d)
for i in range(sequence_length):
for j in range(d):
result[i][j] = np.sin(i / (10000 ** (j / d))) if j % 2 == 0 else np.cos(i / (10000 ** ((j - 1) / d)))
return result
class MyMSA(nn.Module):
def __init__(self, d, n_heads=2):
super(MyMSA, self).__init__()
self.d = d
self.n_heads = n_heads
assert d % n_heads == 0, f"Can't divide dimension {d} into {n_heads} heads"
d_head = int(d / n_heads)
self.q_mappings = nn.ModuleList([nn.Linear(d_head, d_head) for _ in range(self.n_heads)])
self.k_mappings = nn.ModuleList([nn.Linear(d_head, d_head) for _ in range(self.n_heads)])
self.v_mappings = nn.ModuleList([nn.Linear(d_head, d_head) for _ in range(self.n_heads)])
self.d_head = d_head
self.softmax = nn.Softmax(dim=-1)
def forward(self, sequences):
result = []
for sequence in sequences:
seq_result = []
for head in range(self.n_heads):
q_mapping = self.q_mappings[head]
k_mapping = self.k_mappings[head]
v_mapping = self.v_mappings[head]
seq = sequence[:, head * self.d_head: (head + 1) * self.d_head]
q, k, v = q_mapping(seq), k_mapping(seq), v_mapping(seq)
attention = self.softmax(q @ k.T / (self.d_head ** 0.5))
seq_result.append(attention @ v)
result.append(torch.hstack(seq_result))
return torch.cat([torch.unsqueeze(r, dim=0) for r in result])
本文参考了https://medium.com/mlearning-ai/vision-transformers-from-scratch-pytorch-a-step-by-step-guide-96c3313c2e0c https://medium.com/mlearning-ai/vision-transformers-from-scratch-pytorch-a-step-by-step-guide-96c3313c2e0c
https://medium.com/mlearning-ai/vision-transformers-from-scratch-pytorch-a-step-by-step-guide-96c3313c2e0c
不足之处欢迎指正,源码可以私信或评论,看到就会回复