论文笔记 Feature Selective Anchor-Free Module for Single-Shot Object Detection - CVPR 2019
2019 FSAF Feature Selective Anchor-Free Module for Single-Shot Object Detection
Chenchen Zhu, Yihui He CVPR, 2019 PDF
19年的这几篇论文非常相似,针对启发式 Anchor-Based 网络只能获取次优解的问题,提出了 Anchor Free 的网络,以下是19年的四篇 Anchor-Free 的模型:
| Anchor-Free | Feature Selective Anchor-Free Module for Single-Shot Object Detection | CVPR, 2019 |
| FCOS: Fully Convolutional One-Stage Object Detection | ICCV, 2019 | |
| FoveaBox: Beyond Anchor-based Object Detector | TIP, 2019 | |
| Center and Scale Prediction: Anchor-free Approach for Pedestrian and Face Detection | CVPR, 2019 |
想想还是有点有趣,YOLO V2 使用 Faster R-CNN 中的 anchor 提升了模型的性能,但是基于 Anchor-Based 的模型,基于人工经验规则将不同尺寸的 Anchor-Boxes 分散到了不同的特征层,这样的结果显然就是 Sub-Optimal 的。
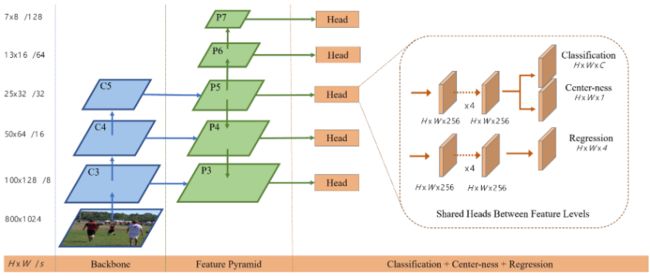
以下是这四个模型的 detection head,基本都是 2 个分支,一个预测类别,输出 H × W × K H\times W\times K H×W×K,另一个预测边框的相对坐标,输出大小为 H × W × 4 H\times W\times 4 H×W×4。方法 2 除了这两个分支之外,还增加了一个 regression branch 来预测每个点到 ground truth 中心的远近程度。



更多关于 Anchor-Based 和 Anchor-Free 可参照参考博文1.
摘要
FSAF 模块解决了传统的 Anchor-Based 的检测带来的两个限制:
- heuristic-guided feature selection
- overlap-based anchor sampling
FSAF 的基本概念是,将 online feature selection 应用在 multi-level anchor-free branches 的训练中。即特征金字塔的每一层都跟有一个 anchor-free branch,从而可以在任何一个特征层对 box 进行编码解码。在训练期间,我们动态地将每个 ground-true box 分配给最合适的特征层(这也就是 online feature selection 了)。在推理时,FSAF 模块可以通过并行输出预测与 anchor-based branch 联合工作。
1. Introduction
对象检测的一个具有挑战性的问题是尺度变化。为了实现尺度不变性,SOTA的检测器构建feature pyramids或multi-level feature towers。并且特征图的多个尺度级别正在并行生成预测。此外,anchor boxes可以进一步处理尺度变化。anchor boxes设计用于将所有可能的实例框的连续空间离散为具有预先设定的位置、比例和纵横比的有限数量的框。instance boxes 通过 IoU 被匹配到 anchor boxes。
One challenging problem for object detection is scale variation. To achieve scale invariability, state-of-the-art detectors construct feature pyramids or multi-level feature towers. And multiple scale levels of feature maps are generating predictions in parallel. Besides, anchor boxes can further handle scale variation. Anchor boxes are designed for discretizing the continuous space of all possible instance boxes into a finite number of boxes with predefined locations, scales and aspect ratios. And instance boxes are matched to anchor boxes based on the Intersection-over-Union (IoU) overlap.
在训练期间,我们动态地将每个 ground-true box 分配给最合适的特征层(这也就是 online feature selection 了)。在推理时,FSAF 模块可以通过并行输出预测与 anchor-based branch 联合工作。
During training, we dynamically select the most suitable level of feature for each instance based on the instance content instead of just the size of instance box. The selected level of feature then learns to detect the assigned instances. At inference, the FSAF module can run independently or jointly with anchor-based branches.
2. 相关工作
Recent object detectors often use feature pyramid or multi-level feature tower as a common structure. SSD first proposed to predict class scores and bounding boxes from multiple feature scales. FPN and DSSD proposed to enhance low-level features with high-level semantic feature maps at all scales. RetinaNet addressed class imbalance issue of multi-level dense detectors with focal loss. DetNet designed a novel backbone network to maintain high spatial resolution in upper pyramid levels. However, they all use pre-defined anchor boxes to encode and decode object instances. Other works address the scale variation differently. Zhu et al enhanced the anchor design for small objects. He et al modeled the bounding box as Gaussian distribution for improved localization.
The idea of anchor-free detection is not new. DenseBox first proposed a unified end-to-end fully convolutional framework that directly predicted bounding boxes. UnitBox proposed an Intersection over Union (IoU) loss function for better box regression. Zhong et al proposed anchor-free region proposal network to find text in various scales, aspect ratios, and orientations. Recently CornerNet proposed to detect an object bounding box as a pair of corners, leading to the best single-shot detector. SFace proposed to integrate the anchor-based method and anchor-free method. However, they still adopt heuristic feature selection strategies.
3. Feature Selective Anchor-Free Module
Without lose of generality, we apply the FSAF module to the state-of-the-art RetinaNet and demonstrate our design from the following aspects:
- how to create the anchor-free branches in the network (3.1);
- how to generate supervision signals for anchor-free branches (3.2);
- how to dynamically select feature level for each instance (3.3);
- how to jointly train and test anchor-free and anchor-based branches (3.4).
3.1. Network Architecture
3.2. Ground-truth and Loss
Given an object instance, we know that:
-
class label: k k k -
ground truth box coordinates: b = [ x , y , w , h ] b=[x, y, w, h] b=[x,y,w,h], where ( x , y ) (x, y) (x,y) is the center of the box, and w w w, h h h are box width and height respectively. -
ground truth box在特征层 P l P_l Pl上的投影projected box: b p l = [ x p l , y p l , w p l , h p l ] b_{p}^{l}=\left[x_{p}^{l}, y_{p}^{l}, w_{p}^{l}, h_{p}^{l}\right] bpl=[xpl,ypl,wpl,hpl], i.e. b p l = b / 2 l b_{p}^{l}=b / 2^{l} bpl=b/2l. -
effective box: b e l = [ x e l , y e l , w e l , h e l ] = ϵ e ⋅ b b_{e}^{l}=\left[x_{e}^{l}, y_{e}^{l}, w_{e}^{l}, h_{e}^{l}\right]=\epsilon_e \cdot b bel=[xel,yel,wel,hel]=ϵe⋅b, i.e. ϵ e = 0.2 \epsilon_e=0.2 ϵe=0.2. -
ignoring box: b i l = [ x i l , y i l , w i l , h i l ] = ϵ i ⋅ b b_{i}^{l}=\left[x_{i}^{l}, y_{i}^{l}, w_{i}^{l}, h_{i}^{l}\right]=\epsilon_i\cdot b bil=[xil,yil,wil,hil]=ϵi⋅b, i.e. ϵ e = 0.5 \epsilon_e=0.5 ϵe=0.5.

Classification Output
The instance affects k k kth ground-truth map in three ways
effective boxb e l b^l_e bel 表示 positive 区域,在图中以白色区域表示。ignoring region( b i l − b e l ) (b^l_i− b^l_e) (bil−bel) 在图中以灰色区域表示,该区域内的像素不参与梯度的反向传播。- 相邻特征层的
ignoring boxes也是ignoring region(如果存在)。
ignoring boxes b i l b_{i}^{l} bil 以外的区域表示 negative 区域,在图中以黑色区域表示,特征图区域用 0 0 0 填充。
分类损失采用 Focal Loss:
F L ( p t ) = − α t ( 1 − p t ) γ log ( p t ) , w h e r e α = 0.25 a n d γ = 2.0 \mathrm{FL}\left(p_{\mathrm{t}}\right)=-\alpha_{\mathrm{t}}\left(1-p_{\mathrm{t}}\right)^{\gamma} \log \left(p_{\mathrm{t}}\right),\quad where \, \alpha=0.25\, and\, \gamma=2.0 FL(pt)=−αt(1−pt)γlog(pt),whereα=0.25andγ=2.0
The ground-truth for the classification output is K K K maps, with each map corresponding to one class. The instance affects k k kth ground-truth map in three ways. First, the effective box b e l b^l_e bel region is the positive region filled by ones shown as the white box in“car” class map, indicating the existence of the instance. Second, the ignoring box excluding the effective box ( b i l − b e l ) (b^l_i− b^l_e) (bil−bel) is the ignoring region shown as the grey area, which means that the gradients in this area are not propagated back to the network. Third, the ignoring boxes in adjacent feature levels ( b i l − 1 , b i l + 1 ) (b^{l−1}_i , b^{l+1}_i) (bil−1,bil+1) are also ignoring regions if exists. Note that if the effective boxes of two instances overlap in one level, the smaller instance has higher priority. The rest region of the ground-truth map is the negative (black) area filled by zeros, indicating the absence of objects. Focal loss is applied for supervision with hyperparameters α = 0.25 \alpha = 0.25 α=0.25 and γ = 2.0 \gamma = 2.0 γ=2.0. The total classification loss of anchor-free branches for an image is the summation of the focal loss over all non-ignoring regions, normalized by the total number of pixels inside all effective box regions.
Box Regression Output
The ground-truth for the regression output are 4 4 4 offset maps agnostic to classes. The instance only affects the b e l b^l_e bel region on the offset maps. For each pixel location ( i , j ) (i, j) (i,j) inside b e l b^l_e bel, we represent the projected box b p l b^l_p bpl as a 4-dimensional vector d i , j l = [ d t i , j l , d l i , j l , d b i , j l , d r i , j l ] {\bf d}^l_{i,j} = [d^l_{t_{i,j}} , d^l_{l_{i,j}} , d^l_{b_{i,j}} , d^l_{r_{i,j}} ] di,jl=[dti,jl,dli,jl,dbi,jl,dri,jl], where d t l , d l l , d b l , d r l d^l_t, d^l_l, d^l_b, d^l_r dtl,dll,dbl,drl are the distances between the current pixel location ( i , j ) (i, j) (i,j) and the top, left, bottom, and right boundaries of b p l b^l_p bpl, respectively. Then the 4 4 4-dimensional vector at ( i , j ) (i, j) (i,j) location across 4 4 4 offset maps is set to d i , j l / S {\bf d}^l_{i,j}/S di,jl/S with each map corresponding to one dimension. S S S is a normalization constant and we choose S = 4.0 S = 4.0 S=4.0 in this work empirically. Locations outside the effective box are the grey area where gradients are ignored. IoU loss is adopted for optimization. The total regression loss of anchor-free branches for an image is the average of the IoU loss over all effective box regions.
During inference, it is straightforward to decode the predicted boxes from the classification and regression outputs. At each pixel location ( i , j ) (i, j) (i,j), suppose the predicted offsets are [ o ^ t i , j , o ^ l i , j , o ^ b i , j , o ^ r i , j ] [\hat{o}_{t_{i,j}},\hat{o}_{l_{i,j}} ,\hat{o}_{b_{i,j}},\hat{o}_{r_{i,j}}] [o^ti,j,o^li,j,o^bi,j,o^ri,j]. Then the predicted distances are S ⋅ [ o ^ t i , j , o ^ l i , j , o ^ b i , j , o ^ r i , j ] S\cdot [\hat{o}_{t_{i,j}},\hat{o}_{l_{i,j}} ,\hat{o}_{b_{i,j}},\hat{o}_{r_{i,j}}] S⋅[o^ti,j,o^li,j,o^bi,j,o^ri,j]. And the top-left corner and the bottom-right corner of the predicted projected box are ( i − S o ^ t i , j , j − S o ^ l i , j ) (i− S\hat{o}_{t_{i,j}}, j− S\hat{o}_{l_{i,j}}) (i−So^ti,j,j−So^li,j) and ( i + S o ^ b i , j , j + S o ^ r i , j ] ) (i + S\hat{o}_{b_{i,j}} , j + S\hat{o}_{r_{i,j}}]) (i+So^bi,j,j+So^ri,j]) respectively. We further scale up the projected box by 2 l 2^l 2l to get the final box in the image plane. The confidence score and class for the box can be decided by the maximum score and the corresponding class of the K-dimensional vector at location ( i , j ) (i, j) (i,j) on the classification output maps.
3.3. Online Feature Selection
The design of the anchor-free branches allows us to learn each instance using the feature of an arbitrary pyramid level P l P_l Pl. To find the optimal feature level, our FSAF module selects the best P l P_l Pl based on the instance content, instead of the size of instance box as in anchor-based methods.
classification loss L F L I ( l ) = 1 N ( b e l ) ∑ i , j ∈ b e l F L ( l , i , j ) box regression loss L I o U I ( l ) = 1 N ( b e l ) ∑ i , j ∈ b e l IoU ( l , i , j ) \begin{aligned} \text{classification loss}&\quad L_{F L}^{I}(l)=\frac{1}{N\left(b_{e}^{l}\right)} \sum_{i, j \in b_{e}^{l}} F L(l, i, j) \\ \text{box regression loss}&\quad L_{I o U}^{I}(l)=\frac{1}{N\left(b_{e}^{l}\right)} \sum_{i, j \in b_{e}^{l}} \operatorname{IoU}(l, i, j) \end{aligned} classification lossbox regression lossLFLI(l)=N(bel)1i,j∈bel∑FL(l,i,j)LIoUI(l)=N(bel)1i,j∈bel∑IoU(l,i,j)
where N ( b e l ) N (b^l_e) N(bel) is the number of pixels inside b e l b^l_e bel region, and F L ( l , i , j ) F L(l, i, j) FL(l,i,j), I o U ( l , i , j ) {\rm IoU} (l, i, j) IoU(l,i,j) are the focal loss and I o U {\rm IoU} IoU loss at location ( i , j ) (i, j) (i,j) on P l P_l Pl respectively.
下图展示了在线特征选择过程。首先,实例 I I I 通过特征金字塔的每一层。然后,计算所有anchor-free branch 的总损失,选择总损失最小的学习实例。Finally, the best pyramid level P l ∗ P_{l∗} Pl∗ yielding the minimal summation of losses is selected to learn the instance, i . e . i.e. i.e.
 Figure 6: Online feature selection mechanism. Each instance is passing through all levels of anchor-free branches to compute the averaged classification (focal) loss and regression (IoU) loss over effective regions. Then the level with minimal summation of two losses is selected to set up the supervision signals for that instance.
Figure 6: Online feature selection mechanism. Each instance is passing through all levels of anchor-free branches to compute the averaged classification (focal) loss and regression (IoU) loss over effective regions. Then the level with minimal summation of two losses is selected to set up the supervision signals for that instance.
l ∗ = arg min l L F L I ( l ) + L I o U I ( l ) l^{*}=\arg \min _{l} L_{F L}^{I}(l)+L_{I o U}^{I}(l) l∗=arglminLFLI(l)+LIoUI(l)
For a training batch, features are updated for their correspondingly assigned instances. The intuition is that the selected feature is currently the best to model the instance. Its loss forms a lower bound in the feature space. And by training, we further pull down this lower bound. At the time of inference, we do not need to select the feature because the most suitable level of feature pyramid will naturally output high confidence scores.
为了验证Online Feature Selection的有效性,文章同时对比了heuristic feature selection,该方法就是经典FPN中所采用人工定义方法:
l ′ = ⌊ l 0 + log 2 ( w h / 224 ) ⌋ l^{\prime}=\left\lfloor l_{0}+\log _{2}(\sqrt{w h} / 224)\right\rfloor l′=⌊l0+log2(wh/224)⌋
3.4. Joint Inference and Training
联合推理 joint Inference
achor-free branch 在将置信度分数阈值化 0.05 后,仅解码每个金字塔级别中最多 1k 个得分最高的box predictions。最后通过阈值为 0.5 的 NMS 结合 anchor-based branch 的结果来获得最终的预测结果。
初始化 Initialization
For conv layers in our FSAF module, we initialize the classification layers with bias − log ( ( 1 − π ) / π ) − \log((1−\pi)/\pi) −log((1−π)/π) and a Gaussian weight filled with σ = 0.01 \sigma = 0.01 σ=0.01, whereπ specifies that at the beginning of training every pixel location outputs objectness scores around π \pi π. We set π = 0.01 \pi = 0.01 π=0.01 following RetinaNet. All the box regression layers are initialized with bias b b b, and a Gaussian weight filled with σ = 0.01 \sigma = 0.01 σ=0.01. We use b = 0.1 b = 0.1 b=0.1 in all experiments. The initialization helps stabilize the network learning in the early iterations by preventing large losses.
优化 Optimization
total optimization loss:
L a b + λ ( L c l s a f + L r e g a f ) L^{a b}+\lambda\left(L_{c l s}^{a f}+L_{r e g}^{a f}\right) Lab+λ(Lclsaf+Lregaf)
where L a b L^{ab} Lab is the total loss of the original anchor-based RetinaNet, L c l s a f L^{af}_{cls} Lclsaf and L r e g a f L^{af}_{reg} Lregaf are the total classification and regression losses of anchor-free branches, λ \lambda λ controls the weight of the anchor-free branches.
Unless otherwise noted, all models are trained for 90 k 90k 90k iterations with an initial learning rate of 0.01 0.01 0.01, which is divided by 10 10 10 at 60 k 60k 60k and again at 80 k 80k 80k iterations. Horizontal image flipping is the only applied data augmentation unless otherwise specified. Weight decay is 0.0001 0.0001 0.0001 and momentum is 0.9 0.9 0.9.
4. Experiments
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-e0ndHLJX-1646615835105)(https://gitee.com/yancilin/figures/raw/master/img/1903.0062-11–1.svg)]
5. 总结
-
anchor-free和每个位置有一个正方形anchor在形式上可以是等价的,也就是利用FCN的结构对feature map的每个位置预测一个框(包括位置和类别)。但anchor-free仍然是有意义的,我们也可以称之为anchor-prior-free。这两者虽然形式上等价,但是实际操作中还是有区别的。在anchor-based的方法中,虽然每个位置可能只有一个anchor,但预测的对象是基于这个anchor来匹配的,而在anchor-free的方法中,通常是基于这个点来匹配的。(此处引用参考博文1) -
anchor-free分支引入了很多的超参数。从实验结果来看,单独的anchor-free分支相对于anchor-based分支并没有太多优势。如何设计更好的anchor-free分支,使超越论文中的bagging策略(anchor-based + anchor-free)呢?(此处引用参考博文2) -
文章从
feature selection角度设计了新的FSAF module来提升性能,从loss角度来看,提升了梯度反向传播的效率,有点类似于SNIP,只更新特定scale内物体对应的梯度,但又和SNIP不一样,效率比SNIP高。(此处引用参考博文3)
参考博文:
-
物体检测的轮回: anchor-based 与 anchor-free
-
论文解读-Feature Selective Anchor-Free Module for Single-Shot Object Detection
-
CVPR2019: FSAF for Single-Shot Object Detection