202203Self-Supervised Pretraining and Controlled Augmentation Improve RareWildlife Recognition inUAV
目录
一、key-word
1.1 Pretext task
1.2 MoCo
1.3 CLD
二、SSL(self- supervised learning) framework
2.1 Augmentation
2.2 Kuzikus Wildlife Dataset Pre-training (KWD-Pre)
2.3 Kuzikus Wildlife Dataset Long-Tail distributed (KWD-LT)
一、key-word
self-supervised pretraining(Pretext task)、MoCo、CLD
1.1 Pretext task
是一种为达到特定训练任务而设计的间接任务。比如训练一个网络来对ImageNet分类,可以表达为 f θ ( x ) : x → y ,目的是获得具有语义特征提取/推理能力的 θ。假设有另外一个任务(也就是pretext),它可以近似获得这样的[公式],比如,Auto-encoder(AE),表示为: g θ ( x ) : x → x 。为什么AE可以近似 θ 呢?因为AE要重建 x就必须学习 x中的内在关系,而这种内在关系的学习又是有利于我们学习 [公式]的。这种方式也叫做预训练,为了在目标任务上获得更好的泛化能力,一般还需要进行fine-tuning(微调)等操作。
因此,Pretext task的好处就是简化了原任务的求解,在深度学习里就是避免了人工标记样本,实现无监督的语义提取,下面进一步解释。
Pretext任务可以进一步理解为:对目标任务有帮助的辅助任务。而这种任务目前更多的用于所谓的Self-Supervised learning,即一种更加宽泛的无监督学习。这里面涉及到一个很强的动机:训练深度学习需要大量的人工标注的样本,这是费时耗力的。而自监督的提出就是为了打破这种人工标注样本的限制,目的是在没有人工标注的条件下也能高效的训练网络,自监督的核心问题是如何产生伪标签(Pseudo label),而这种伪标签的产生是不涉及人工的,比如上述的AE的伪标签就是 [公式] 自身。举几个在视觉任务里常用的pretext task伪标签的产生方式:
·Rotation(图片旋转)
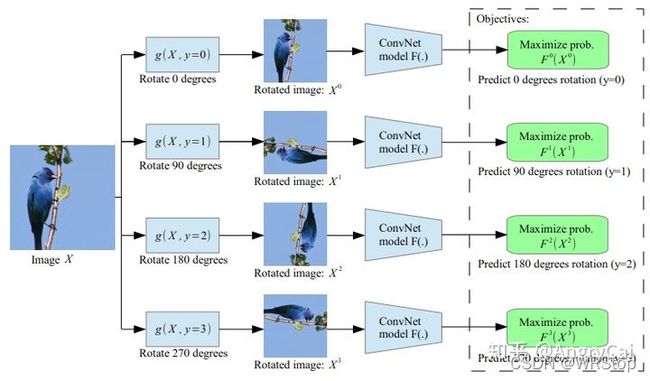
[1] S. Gidaris, P. Singh, and N. Komodakis, “Unsupervised representation learning by predicting image rotations,” ICLR, 2018.·Colorization(图片上色)
·Colorization(图片上色)
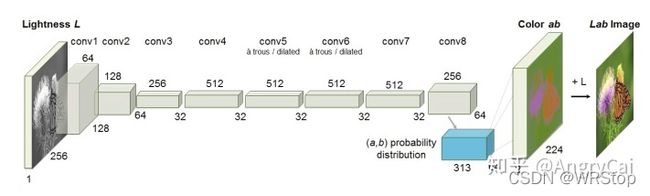
[2] R. Zhang, P. Isola, and A. A. Efros, “Colorful Image Colorization,” in ECCV, Cham, 2016, pp. 649-666.
·Inpainting(图片补全)
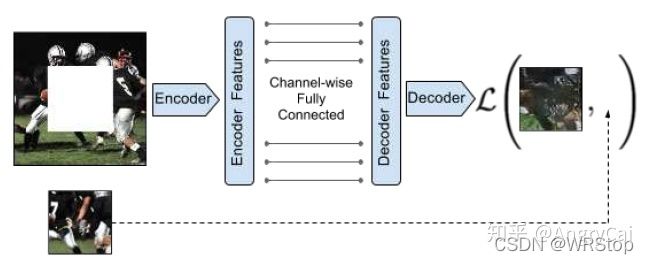
[3] D. Pathak, P. Krahenbuhl, J. Donahue, T. Darrell, and A. A. Efros, “Context Encoders: Feature Learning by Inpainting,” CVPR, 2016.
·Jigsaw Puzzle/Context Prediction(关系预测/上下文预测)
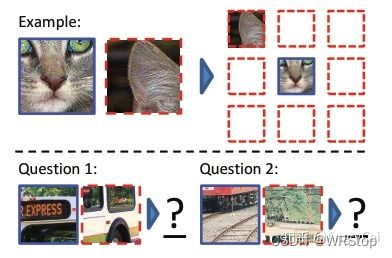
[4] C. Doersch, A. Gupta, and A. A. Efros, “Unsupervised Visual Representation Learning by Context Prediction,” ICCV, 2015.
参考:Self-Supervised Learning 自监督学习中Pretext task的理解_AngryCai的专栏-CSDN博客_pretext task
1.2 MoCo
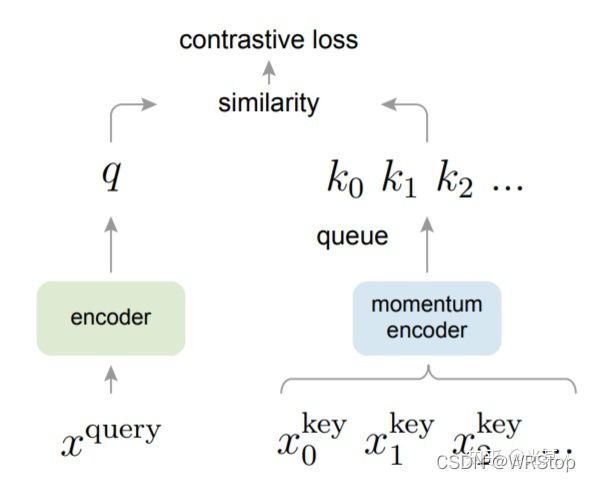
受NLP任务的启发,MOCO将图片数据分别编码成查询向量和键向量,即,查询 q 与键队列 k ,队列包含单个正样本和多个负样本。通过 对比损失来学习特征表示。
主线依旧是不变的:在训练过程中尽量提高每个查询向量与自己相对应的键向量的相似度,同时降低与其他图片的键向量的相似度。
MOCO使用两个神经网络对数据进行编码:encoder和momentum encoder。encoder负责编码当前实例的抽象表示。momentum encoder负责编码多个实例(包括当前实例)的抽象表示。对于当前实例,最大化其encoder与momentum encoder中自身的编码结果,同时最小化与momentum encoder中其他实例的编码结果。
参考:对比学习(Contrastive Learning)综述 - 知乎
1.3 CLD
其核心思想为:首先对instances进行聚类,从而使相似instances被聚类为相同的group,之后进行contrastive learning,从而缓解了对高相似度instance进行错误排斥的情况。
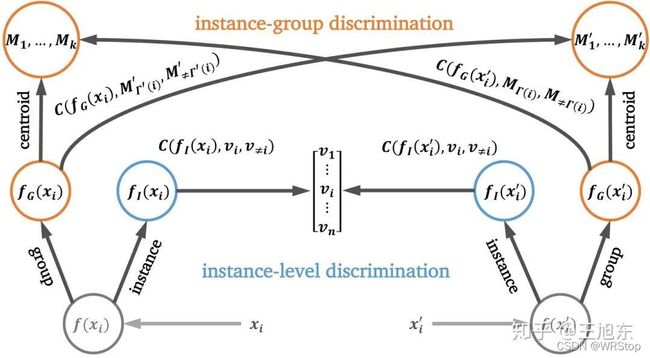
参考:【源头活水】CVPR 2021 | CLD: 通过挖掘实例与聚类间关系进行无监督特征学习 - 云+社区 - 腾讯云
二、SSL(self- supervised learning) framework

模型建立在MoCo[13,5]和跨水平实例群识别(CLD)的工作基础上:
•提出了一种图像级野生动物识别方法,通过自我监督预训练减少标注数量。
•证明了在下游识别任务中,用自监督预训练比监督ImageNet预训练表现更好。
并且发现当将受控增强应用于自监督预训练,并微调具有少量标签的预训练模型,将优于使用所有可用训练标签微调的ImageNet预训练。自我监督预训练比监督预训练更有效地学习自然野生动物场景的表现。
2.1 Augmentation
对同一输入图像应用多个增强[39]。我们对一个特定的增广变换保持不变。例如,I1、I+总是通过相同的颜色但不同的旋转增强来增强,而I2、I+总是通过相同的旋转但不同的颜色增强来增强.
2.2 Kuzikus Wildlife Dataset Pre-training (KWD-Pre)
for pre-training
为每幅原始4000×3000的图像随机裁剪了15块补丁。每个补丁的大小为256×256像素,以节省内存并具有更大的批量大小。如果一张图像包含动物,我们会随机裁剪15个额外的补丁。以这种方式修剪会增加提取包含动物的斑块用于训练的机会。
2.3 Kuzikus Wildlife Dataset Long-Tail distributed (KWD-LT)
for fine-tuning/downstream task
背景类,原始图像随机裁剪程序(512)并验证每个补丁以确保其不包含任何动物。前景(野生动物)类,在地面真实边界框周围随机裁剪(224),确保每个片包含一个完整的动物body。选择了三种不同的随机种子,即训练、测试和验证集,以确保位置不同。