大数据分析与人工智能实验室8.26培训记录
1.1 人工智能 > 机器学习 > 人工智能
- 深度学习是机器学习的一个分支
- 机器学习是人工智能的一个分支

Artificial Intelligence,也就是人工智能。虽然计算机技术已经取得了长足的进步,但是到目前为止,还没有一台电脑能产生“自我”的意识。
自 2006 年以来,机器学习领域,取得了突破性的进展。图灵试验,至少不是那么可望而不可及了。至于技术手段,不仅仅依赖于云计算对大数据的并行处理能力,而且依赖于算法。这个算法就是,Deep Learning。借助于 Deep Learning 算法,人类终于找到了如何处理“抽象概念”这个亘古难题的方法。

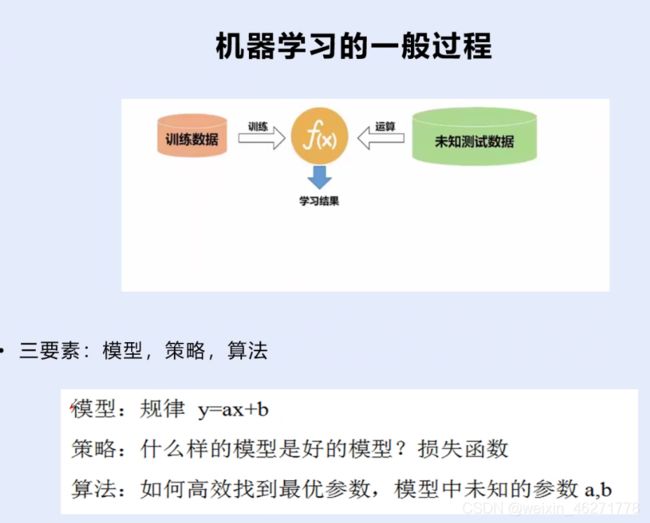
线性:y=ax+b 重点,本质
非线性:y=ax^2+bx+c 或 其他
a,b,c为参数,如何高效的找到模型中最优的参数a和b,即为深度学习的算法广义
策略是找到好的模型,可以通过
global step 300, epoch: 16, batch: 15, loss: 0.00298, acc: 0.99896
#开始训练
global_step = 0
with LogWriter(logdir="./log") as writer:
for epoch in range(1, epochs + 1):
for step, batch in enumerate(train_loader, start=1): #从训练数据迭代器中取数据
input_ids, segment_ids, labels = batch
logits = model(input_ids, segment_ids)
loss = criterion(logits, labels) #计算损失
probs = F.softmax(logits, axis=1)
correct = metric.compute(probs, labels)
metric.update(correct)
acc = metric.accumulate()
global_step += 1
if global_step % 100 == 0 :
print("global step %d, epoch: %d, batch: %d, loss: %.5f, acc: %.5f" % (global_step, epoch, step, loss, acc))
#记录训练过程
writer.add_scalar(tag="train/loss", step=global_step, value=loss)
writer.add_scalar(tag="train/acc", step=global_step, value=acc)
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_gradients()
eval_loss, eval_acc = evaluate(model, criterion, metric, dev_loader)
#记录评估过程
writer.add_scalar(tag="eval/loss", step=epoch, value=eval_loss)
writer.add_scalar(tag="eval/acc", step=epoch, value=eval_acc)
运行后输出:

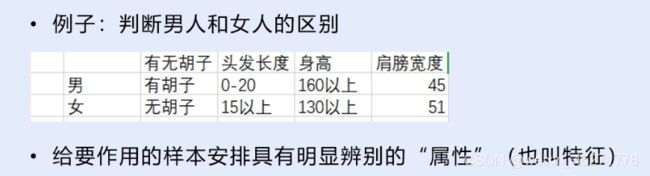
2. 机器学习的类别
2.1 有监督学习
在监督式学习下,输入数据被称为“训练数据”,每组训练数据有一个明确的标识或结果,如对防垃圾邮件系统中“垃圾邮件”“非垃圾邮件”,对手写数字识别中的“1“,”2“,”3“,”4“等。在建立预测模型的时候,监督式学习建立一个学习过程,将预测结果与“训练数据”的实际结果进行比较,不断的调整预测模型,直到模型的预测结果达到一个预期的准确率。监督式学习的常见应用场景如分类问题和回归问题。常见算法有逻辑回归(Logistic Regression)和反向传递神经网络(Back Propagation Neural Network)

2.2 无监督学习
在此学习方式下,输入数据部分被标识,部分没有被标识,这种学习模型可以用来进行预测,但是模型首先需要学习数据的内在结构以便合理的组织数据来进行预测。应用场景包括分类和回归,算法包括一些对常用监督式学习算法的延伸,这些算法首先试图对未标识数据进行建模,在此基础上再对标识的数据进行预测。如图论推理算法(Graph Inference)或者拉普拉斯支持向量机(Laplacian SVM.)等。
2.3 半监督学习

2.4 强化学习(包括迁移学习)

2.5 多任务学习:

3. 机器学习的一般处理过程
首先处理数据

完整性:有信息缺失等
合法性:性别不能中性
唯一性:性别不能一会男一会女
权威性:不同权重,如学校官方文件权重0.5和小道消息0.1
一致性:单位不一样或相对指标不同
处理流程


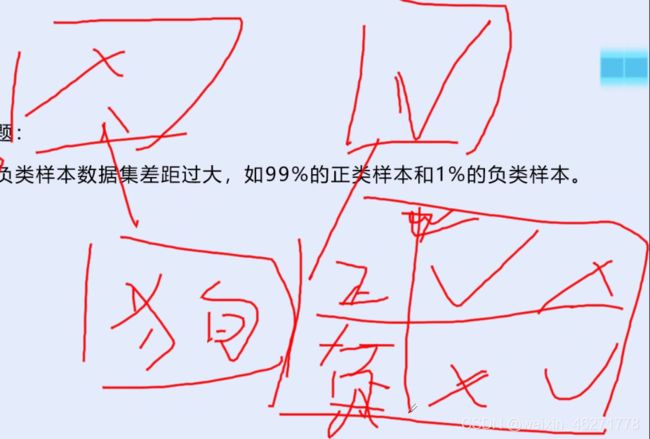
正负类样本:

![]()
根据预测正确与否,将样例分为以下四种:
TP(True positive,真正例)——将正类预测为正类数。
FP(False postive,假正例)——将反类预测为正类数。
TN(True negative,真反例)——将反类预测为反类数。
FN(False negative,假反例)——将正类预测为反类数。
最好是 正与负 1:1

数据分类:
一般分为三种,训练集,验证集,测试集
训练集-----------学生的课本;学生 根据课本里的内容来掌握知识。
验证集------------作业,通过作业可以知道 不同学生学习情况、进步的速度快慢。
测试集-----------考试,考的题是平常都没有见过,考察学生举一反三的能力。
传统上,一般三者切分的比例是:6:2:2,验证集并不是必须的。
trainlst = txt_to_list('train.txt')
devlst = txt_to_list('eval.txt')
testlst = txt_to_list('test.txt')或者 : 训练集:70%*70% 验证集:70%*30% 测试集:30%

- 训练集是用来通过梯度反向传播更新参数的,而验证集和测试集不会通过梯度反向传播更新参数,所以测试集和验证集完全可以是同一个数据集,而他俩都不可以和训练集有交叠,即必须互斥。
有的书里说的是尽量互斥,即允许少量重叠。
#获得标签列表
label_list = train_ds.get_labels()
testlabel_list = test_ds.get_labels()
#看看数据长什么样子,分别打印训练集、验证集、测试集的前3条数据。
print("训练集数据:{}\n".format(train_ds[0:3]))
print("验证集数据:{}\n".format(dev_ds[0:3]))
print("测试集数据:{}\n".format(test_ds[0:3]))
print("训练集样本个数:{}".format(len(train_ds)))
print("验证集样本个数:{}".format(len(dev_ds)))
print("测试集样本个数:{}".format(len(test_ds)))输出结果:
训练集数据:[['微创清除术联合醒脑静治疗脑出血疗效观察', '0'], ['安脑丸治疗急性发热的临床观察', '0'], ['葛根素注射液致肝、肾损害', '1']] 验证集数据:[['白加黑感冒片致变态反应1例', '1'], ['胃心综合征1例', '0'], ['斧标驱风油外用致过敏性休克1例', '1']] 测试集数据:[['过量服用白加黑感冒片中毒致死亡1例', '1'], ['卡托普利致肾功能损害1例', '1'], ['醒脑静注射液治疗急性有机磷农药中毒昏迷患者的疗效观察', '0']] 训练集样本个数:1159 验证集样本个数:495 测试集样本个数:71


https://blog.csdn.net/renhaofan/article/details/83657579?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522162996779716780274156890%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=162996779716780274156890&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-1-83657579.pc_search_result_control_group&utm_term=%E7%89%B9%E5%BE%81%E7%BC%96%E7%A0%81&spm=1018.2226.3001.4187