拯救pandas计划(24)——数据框形状的转换:列转行,行转列
拯救pandas计划(24)——数据框形状的转换:列转行,行转列
-
- / 数据需求
- / 需求拆解
- / 总结
最近发现周围的很多小伙伴们都不太乐意使用pandas,转而投向其他的数据操作库,身为一个数据工作者,基本上是张口pandas,闭口pandas了,故而写下此系列以让更多的小伙伴们爱上pandas。
系列文章说明:
系列名(系列文章序号)——此次系列文章具体解决的需求
平台:
- windows 10
- python 3.8
- pandas >=1.2.4
/ 数据需求
目前有这么一个数据框,需要将部分列转换成行数据上,再将一列的数据转换成列名。

类似于这个数据框,左图转换成右图,简单的意思就是将时间跟品种的位置做一个调换。
/ 需求拆解
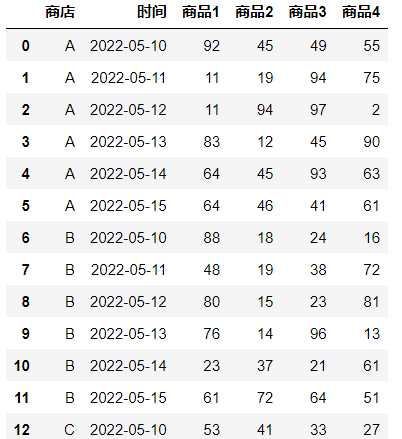
先生成一个模拟数据框:
import numpy as np
import pandas as pd
np.random.seed(2022)
data = {'商店': np.repeat(['A', 'B', 'C'], 4),
'品种': ['商品1', '商品2', '商品3', '商品4'] * 3,
'2022-05-10': np.random.randint(0, 100, 12),
'2022-05-11': np.random.randint(0, 100, 12),
'2022-05-12': np.random.randint(0, 100, 12),
'2022-05-13': np.random.randint(0, 100, 12),
'2022-05-14': np.random.randint(0, 100, 12),
'2022-05-15': np.random.randint(0, 100, 12)}
df = pd.DataFrame(data)
首先处理方式就是将列的部分转换成行,又叫宽表转长表,转换类型的函数在pandas里有很多,如pd.melt、pd.wide_to_long、pd.lreshape、pd.DataFrame().stack等方法。
在该数据框中,时间的列都有相同的特点,可以通过一些函数方法进行获取,比如:
df.columns.str.extract(r'(\d+-.*)', expand=False).dropna()
轻松地获取了日期的所有列。
- melt + pivot
以pd.melt为例,主要接受两个参数,id_vars不需要转换的列,value_vars需要转换成行的列,对应的name则是生成后的数据的列名。
df1 = df.melt(['商店', '品种'], df.columns.str.extract(r'(\d+-.*)', expand=False).dropna(), var_name='时间')
print(df1)

首次转换的结果如上,还需要将品种列转换成列名,才能生成目标结果。
在列转行中,方法也有很多,常用的有pd.pivot和pd.DataFrame().unstack,以pd.pivot为例,接受三个参数,index, columns, values分别为结果的索引,列名及值。
print(df1.pivot(['商店', '时间'], '品种', values='value'))
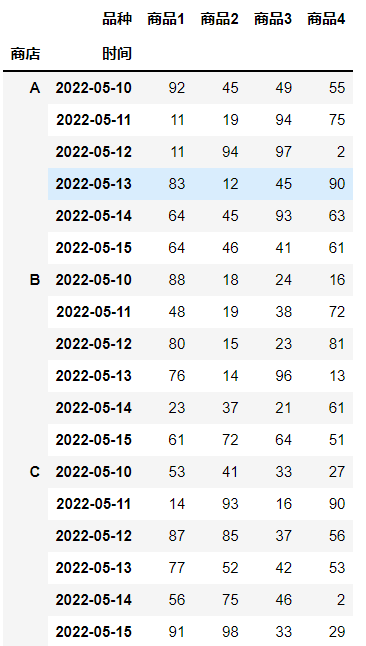
再重置索引,就能得到目标结果:
df1.pivot(['商店', '时间'], '品种', values='value').reset_index()
- stack + unstack
stack和unstack,一个将列转换成行,一个将行转换成列。pd.melt的方法结果生成仍然平摊在值上,跟pd.pivot结合也稍显方便,当然首先将部分列置在索引上,也能得到想要的结果。
df.set_index(['商店', '品种'])
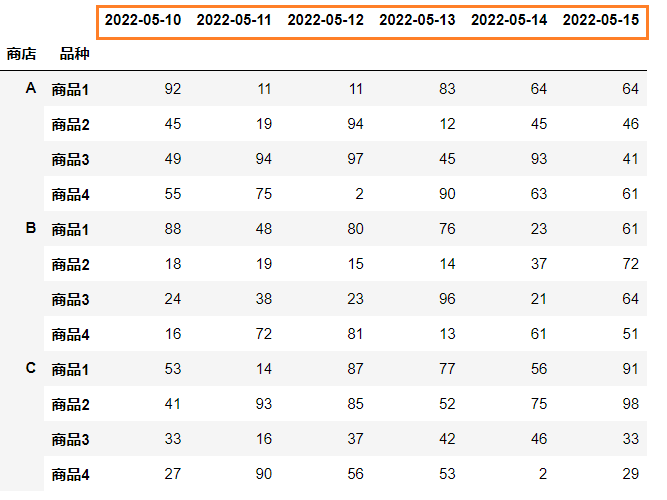
剩下的列都是需要转换的,直接用.stack()就行,与此同时,使用unstack('品种')将索引’品种’转换成列名。
df1 = df.set_index(['商店', '品种']).stack().unstack('品种')
print(df1)
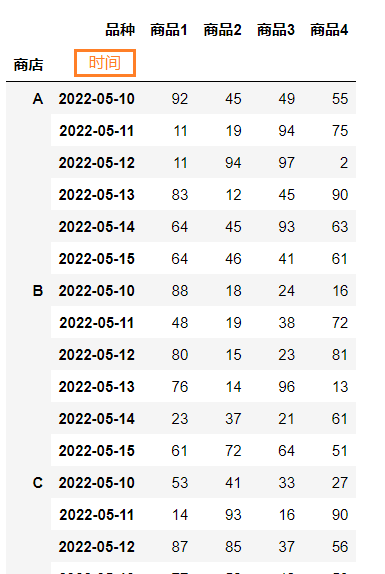
与结果相差一个列名时间缺失,并且需要将索引置为值类型,在stack和unstack中都没有能为列转行的行为进行赋值名称的过程。
df1.columns = df1.columns.values
df1.index.set_names('时间', level=-1, inplace=True)
df1.reset_index(inplace=True)
print(df1)
首先去除列名部分的name值,再将最后一级的索引名称赋值为时间,最后重置索引为值,得到目标结果。
(手动水印:原创CSDN宿者朽命,https://blog.csdn.net/weixin_46281427?spm=1011.2124.3001.5343, 公众号A11Dot派)
- wide_to_long + unstack
wide_to_long可以直接在数据框中选定列作为索引,按正则表达式进行条件筛选选定转换成行的列。
pd.wide_to_long(
df: 'DataFrame',
stubnames, # 需要将宽表的列转换为行的列名的前缀名
i, # 作为索引的列
j, # 转换为行后的那列的列名
sep: 'str' = '', # 需要转换为行的列名的分隔符,分隔符后的部分作为值
suffix: 'str' = '\\d+', # 正则表达式筛选列名的后缀
) -> 'DataFrame'
个人对各参数的一些理解。在该例中用法如下:
df1 = pd.wide_to_long(df, '', ['商店', '品种'], '时间', suffix=r'\d{4}-\d{2}-\d{2}')
print(df1)
这个结果相对stack的方式多了列名称’时间’,再将品种索引转换到列名上:
df1 = df1.unstack('品种')
最后将索引重置到值上:
df1.columns = df1.columns.get_level_values('品种').values
df1.reset_index(inplace=True)
print(df1)
生成目标结果。
/ 总结
本篇通过对数据框的行列转换需求介绍了pandas中可以将列转换为行及行转换成列名的函数方法,包括wide_to_long、melt、stack、unstack、pivot,力求简单明了的了解各种方法并解决同一个需求,从中理解各个方法的转换逻辑。
-问题是无穷的,方法也是无穷的。-
于二零二二年八月十三日作