CTC算法详解
前言
CTC全称Connectionist temporal classification,是一种常用在语音识别、文本识别等领域的算法,用来解决输入和输出序列长度不一、无法对齐的问题。在CRNN中,它实际上就是模型对应的损失函数。CRNN的模型结构如下图所示:
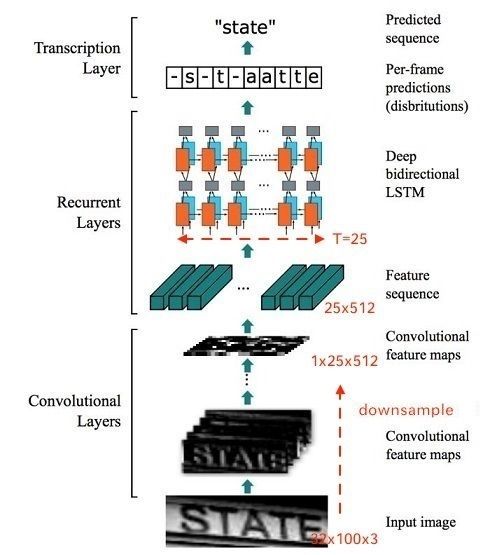
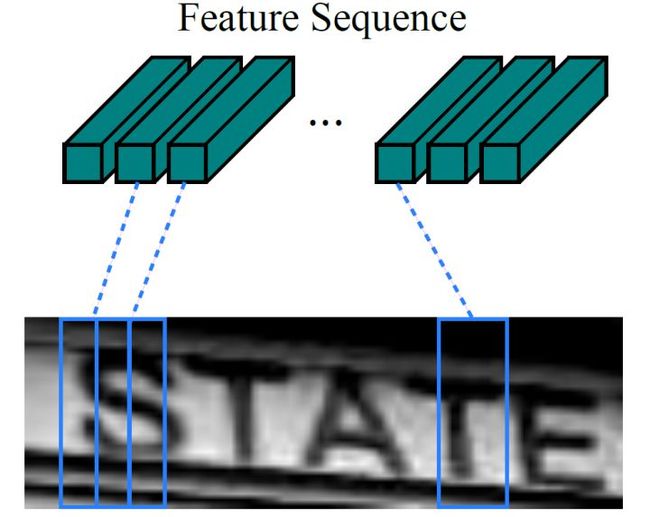
其中的Feature sequence即为下文所说的x输入变量,Predicted sequence即为下文所说的y输出变量,此时x和y的长度是不一样的,所以CTC主要做的工作就是x和y的对齐。
再进行进一步叙述前,这里需要做几点说明。不管是在语音识别还是文本识别领域,CTC通常接在RNN的后面,与RNN结合使用,就像CRNN中一样。所以后面除非特别说明,否则提到的CTC均是将RNN和CTC当整体看待。
RNN在CRNN模型中代表的就是BiLSTM,它接受经过CNN提取的特征向量,大小为 。 即上文提到的特征图的宽度,由于高度为1,所以被去掉了, 即为特征图的通道数。为了便于理解,后面将 也记作 ,也可以简写为 ,即CTC中常涉及的概念——时间步。输出序列的大小为 ,序列长度与输入一致。而每个分量(向量)的维度均为 ,在这里等于字符字典的个数,表示字典个数的概率分布。概率分布经过变换便可以得到最终的预测结果。
为方便叙述,假设输入的序列为 ,对应的输出序列为 ,在这里希望找到 到 的映射关系。
如果使用一般的监督学习算法,会面临诸多的问题,主要可以概括为以下几点:
- 和 的长度是可变的。
- 和 的长度比例也是可变的。
- 和 对应元素之间不能找到严格的对齐关系。
而CTC正是一种可以解决这些问题的算法。对于一个给定的输入 ,它可以计算对应所有可能的 的概率分布。通过该概率分布,可以预测最大概率对应的输出或者某个特定输出的概率
由此可以引出损失函数的定义。对于一个给定的输入 ,转录层需要最大化对应 的后验概率 。当然为了能够正常地训练模型, 应该是可导的。由于训练模型通常以最小化损失函数为目标,所以将优化目标转为最小化 的负对数似然值,即:
其中 表示训练集。
而在预测阶段,每给定一个输入x,CRNN要找到最大概率对应的输出,即
不难想到,如果序列长度稍长,所有概率分布的计算量是及其巨大的,因此这里需要一个速度更快的算法。
前面说过,对于给定的输入 ,转录层需要计算所有可能的 的概率分布,而关键的问题在于如何处理 与 间的对齐问题。所以下面先分析CTC的对齐方式。
CTC的训练目标

CTC的训练过程,本质上是通过梯度 调整LSTM的参数 ,使得对于输入样本为 时使得 取得最大。
例如下面图14的训练样本,目标都是使得 时的输出 变大。所以CTC额本质是替代softmaxloss的损失函数,并采用BPTT算法更新LSTM的参数。 
2. 对齐
要说明的是,CTC是不需要输入输出进行对齐的。但是对于给定的输入,为了计算对应 的概率,仍需要对所有可能对齐的概率进行求和,因为可能同一个输出有多个输出路径对应。下面举例进行说明。
例如CRNN的输入 是一张包含单词“cat”的图片,所以对应的输出序列应该为 。那么一种对齐 和 的方式是先对输入的每个分量 对应一个输出字符,然后将相邻的重复字符进行合并,具体如下图所示。
当然这里很容易发现这种对应方式是不合理的。第一个问题是输入的图片可能根本不包含任何字符,即输出的结果应该为空,而强制每个输入分量 对应一个字符显然得不到这样的结果。第二个问题是如果将所有相邻重复字符都进行合并处理的话,将不能产生连续相同字符,导致结果可能是错误的。比如如果将单词tooth进行合并处理,那么最终的输出将是toth而不是tooth。
所以考虑上述问题,CTC算法又引入了一个特殊的字符——占位符,记作 或 。它表示一个占位,不对应任何字符,因此在最终的输出时要将其删除。这样以后这里仍可以采用上述的对齐规则,并同时避免以上的问题,当然最后不要忘了在输出中去掉 。单词hello的对齐过程如下图所示。
可以看出,如果单词存在两个相同的字符,为了能够处理这种情况,需要在这两个字符间插入 。这样就能区分诸如“toth”和“tooth”的对齐方式了。
这样的规则具有以下几种特征。第一,输入 与输出 的对齐是单调的,即当 前进至下一个时间片对应的输入分量 时, 既可以保持不动,也可以移动至下一个时间片对应的输出分量 。第二,输入与最终的输出是一对多的关系,即多个输入分量可能只对应一个输出分量。
所以,输出 的长度一定不大于 。
3. 后验概率
回顾CTC的优化目标,对于一个给定的输入 ,需要最大化 对应 的后验概率 ,所以显然需要先得到后验概率的值。通过上面定义的对齐规则,已经解决了最后序列合并的对齐问题。接下来说明具体如何根据每个时间片的概率,推算出最终输出序列的后验概率 。
具体地,对于一个输入 ,每一时间步对应分量 的特征维度,记为 。 经过BiLSTM输出 ,每个分量 的维度记为 ,表示 个概率。 实际上等于字符集合 的个数,假如需要预测的字符对应的字段包含52个英文字母(包括大小写),考虑之前加入的占位符,则 的值就是53。
对于每个分量 ,都选取一个元素,便可以组成一条输出路径,记为 ,输出路径的空间可表示为 。
定义一个映射 ,表示对中间输出路径进行变换,得到最后的输出 。注意这里的路径不是最终的输出 ,需要经过合并相邻字符以及删除占位符的处理,才会得到 ,所以相当于中间结果。下面举例说明。
假设识别的序列为"taste", 时,那么以下几种路径均满足条件:
因此求taste最终输出对输入的后验概率时 ,就是求这四条路径对应概率之和。进一步推广,给定输入 ,中间结果对应的路径 ,最终输出 ,则 对 的后验概率可以表示为:
假设不同时间步的输出变量相互独立,那么对于输出路径 对 的后验概率可表示为:
表示路径 在 时间步时对应的输出字符,而 表示在 时间步时选取的字符为 的概率。因此,综合上述两式可得:
简单来说,公式表示的含义为 对 的后验概率等于所有对应路径的概率之和,而每条路径对 的后验概率又等于组成该路径的字符出现概率的乘积。
由于连续重复字符以及占位符的存在,每一个特定的输出 都会对应相当多的路径。如果这里逐一遍历进行求解,那么时间的复杂度可达到 , 为前面定义的字符集的个数, 为时间步总长。这是因为有 个步长,而每个步长输出的字符又有 种可能性。所以需要对算法进行改进,这里便借鉴了动态规划的思想。
4. 前向后向算法
对于一个最终输出序列 ,实际上也表示中间路径合并后的结果。定义 表示在序列 所有相邻元素之间插入占位符后的序列。比如:
依然拿上述例子进行说明,如下图所示。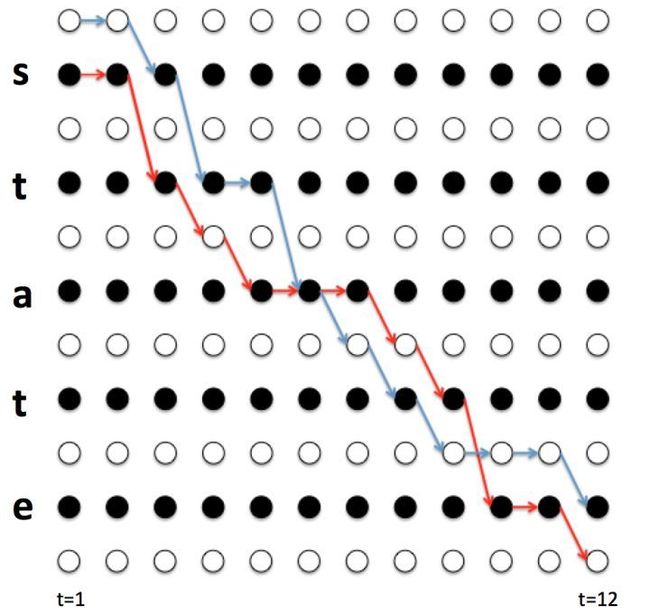
从上图可以看出,四条中间路径 , , , 合并处理后都可以得到state,并且他们都经过字符 。如果将路径蓝色部分记为 ,红色部分记为 ,则不难推出:
由于4条路径都经过 ,所以都包含 项,提取公因式进行合并,令
则公式 可以写成:
当然,这只是包含4条路径的结果,实际上序列state应该对应更多的路径,如下图所示。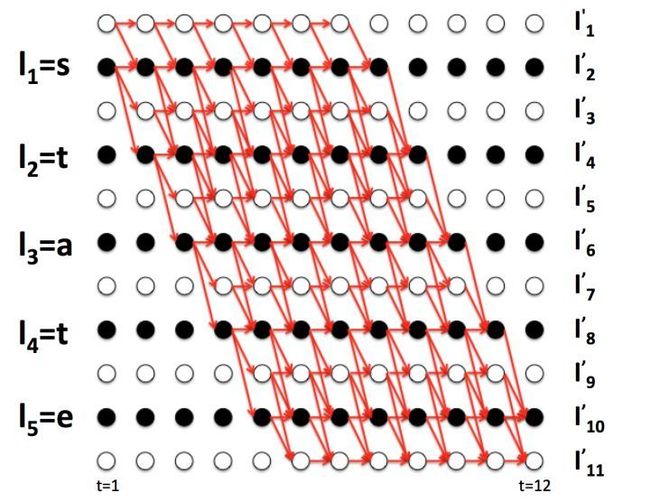
所以上述公式可推广为:
进一步地,这里可以定义 , 表示时间步为 时经过字符 的所有路径在 时刻的概率和,即:
不难分析, 时字符只能占位符或 ,所以可得:
进一步观察可以发现,由于 的限制,时对应的字符只能为 ,或 。所以可得递推公式:
进一步推广可得一般式如下:
类似地,这里可以定义 ,表示时间步为 时经过字符 的所有路径在 时刻的概率和,即:
不难分析, 时字符只能占位符或 ,所以可得初始条件:
类似地,可得 的递推公式为:
由于 对 求导时,只与经过 的路径有关,所以在反向传播对 进行梯度计算时,便可以将公式进行简化:
而由于
所以将其带入可得:
由上面的推导可知, 和 都可以利用动态规划的思想通过递推公式求出,而不用从头开始计算,复杂度从 变为了 ,大大简化了计算。而 只涉及乘法和加法运算,显然是可导的,所以就可以通过上式进行反向传播计算了。
5. 预测
前面提到,在预测阶段,给定一个输入 ,计算最大概率对应的输出序列。如果假设时间片之间相互独立,那么只需将每一时间片对应概率最大的字符作为预测值,然后组成序列,最后做去重等处理得到最终结果。不过这样并没有考虑多个序列经过对齐对应同一个输出结果。例如,假如 和 各自的概率都低于 ,而二者的概率之和高于后者。前者对齐后的结果均为 ,而后者对齐的结果仍为 ,显然输出 比 更合理些。
所以为了避免这一问题的发生,又引入了另一种算法,称为Beam Search。
里面有个参数 ,用来指定每次保留的前缀序列的个数。假如设置 ,则每次选取概率最大的3个前缀序列,比如 时选取概率最大的3个字符, 时也选取概率最大的3个字符,这样便有9种组合方式。当然对齐之后可能会对应相同的输出,所以要将结果相同的前缀序列进行合并(概率也要相加),然后挑出概率最大的3个作为下一次的输出,以此类推。以序列 为例,具体过程如下图所示。
这里要注意的是,当前缀序列的末尾字符与下一个字符相同时,合并可以产生两种有效输出。
比如上图中 时前缀序列为 , 而合并的字符同样为 ,这样既可以输出 ,也可以输出 ,二者都是可能的。因为在 时,其中一个结果占位符 在对齐时被移除了,但是在这里后面又遇到了相同的字符,按照前面定义的规则,此时合并的结果应该为 。 的两种计算情况如下图所示。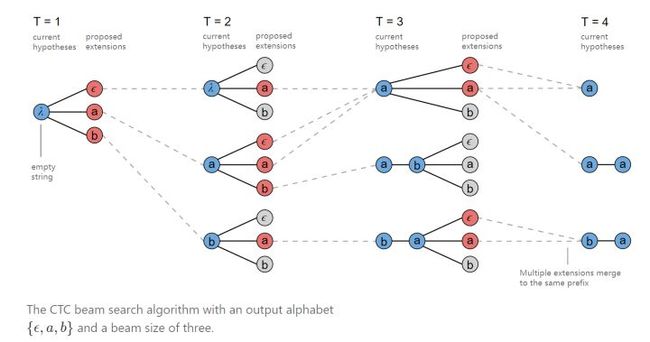
所以,这两种结果应作为两种序列分别进行概率计算。当然,为了能够计算这两种情况对应的概率,需要分别记录以 结尾的前缀序列的概率,以及不以 结尾的前缀序列的概率。
6. 总结
以上便是CTC计算的所有过程。最后,总结CTC的几个特点。
- 条件独立。回顾上面的计算过程,可以发现在进行路径概率计算时,CTC直接将每个时间片对应的概率值进行相乘,也就是说CTC默认每个时间片都是相互独立的。但是,在文本识别中,文本显然是包含上下文信息的,所以模型中才引入了RNN层。当然,结果表明这并没有妨碍到CTC在文本识别领域的优异表现。不过,假如能够在CTC中将输入数据的上下文信息考虑进去,效果应该能得到进一步的提升。
- 单调对齐。CTC的规则决定了输入 与输出 的对齐是单调的。这也导致了CTC无法应用在机器翻译等不符合该约束的领域。
- 多对一映射。输入与最终的输出是一对多的关系,即多个输入分量可能只对应一个输出分量。所以输出 的长度一定不大于 。所以如果遇到 的长度大于 长度的情况,CTC便无法处理了。
参考资料
[1] Sequence Modeling With CTC
[2] CTC(Connectionist Temporal Classification)介绍
[3] 一文读懂CRNN+CTC文字识别