搭建Hadoop分布式集群
搭建Hadoop分布式集群
【系统配置说明】
1)系统环境:CentOS-7-x86-Minimal
2)集群部署:一主三从(master/slave1/slave2/slave3)
3)Java环境:jdk-7u79-linux-x86
4)Hadoop :hadoop-2.6.2.tar.gz
【配置Linux系统环境】
(1)网络环境配置
1) 首先配置四台虚拟机的网络环境,设置为静态IP,IP地址分别如下:
– master:192.168.216.101
– slave1 :192.168.216.102
– slave2 :192.168.216.103
– slave3 :192.168.216.104
2) 配置网络地址的命令如下:
sudo vi /etc/sysconfig/network-scripts/ifcfg-ens33
3) 需要改动的地方如下(以master为例,其余节点配置过程类似):
BOOTPROTO=static
DEVICE=ens33
ONBOOT=yes
IPADDR=192.168.216.101
NETMASK=255.255.255.0
GATEWAY=192.168.216.2
DNS1=114.114.114.114
DNS2=8.8.8.8
4) 重启网络服务
sudo systemctl restart network
ifconfig
(2)修改主机名称
sudo vi /etc/hostname
将主机名称修改为master(从节点保持一致), reboot之后可见主机名称改变
(3)关闭防火墙并禁止开机自启动
sudo systemcl stop firewalld
sudo systemcl disablefirewalld
(4)配置hosts列表
下边以主机为例,从节点相同
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.216.101 master
192.168.216.102 slave1
192.168.216.103 slave2
192.168.216.104 slave3
验证是否修改成功
ping slave1
(5)安装JDK
1)下载 jdk-7u79-linux-x64.tar.gz
2)通过xtfp将jdk文件传送到master的/usr/src目录下
3)安装JDK,步骤如下:
su
cd /usr
mkdir java
mv ./src/jdk-7u79-linux-x64.tar.gz ./java
tar -zxvf jdk-7u79-linux-x64.tar.gz
cd jdk1.7.0_79
pwd #复制此处显示路径
vi /etc/profile
添加环境变量如下
export JAVA_HOME=/usr/java/jdk1.7.0_79
export PATH=$PATH:$JAVA_HOME/bin
保存退出
source /etc/profile
(6)免密钥登录配置(Master节点)
在此步骤之前切换到普通用户身份下
su master
ssh-keygen -t rsa #在终端生成密钥
cd /home/master/.ssh #生成的密钥在此目录下,id_rsa为私钥,id_rsa.pub为公钥
cat id_rsa.pub >> authorized_keys #复制公钥到authorized_keys文件
chmod 600 authorized_keys #修改密钥文件的权限
scp authorized_keys master@slave1:/home/master/.ssh/ #将公钥分发给其他三个从节点
ssh master@slave1 #验证免密钥登录
【Hadoop的配置部署】
【注】:本部分的安装部署是在普通用户的身份下进行的,请先切换;
Hadoop集群搭建时,每个节点上的配置都相同,所以只要在master节点上操作配置,配置完成之后复制到slave节点上
就好了。
(1)解压Hadoop安装文件
cd /home/master/local/src
tar -zxvf hadoop-2.6.2.tar.gz
cd hadoop-2.6.2
(2)配置环境变量 hadoop-env.sh
vi ./etc/hadoop/hadoop-env.sh #打开环境配置文件
找到以下代码
export JAVA_HOME=${JAVA_HOME}
将其替换为以下代码
export JAVA_HOME=/usr/jave/jdk1.7.0_79
保存退出,Hadoop的环境变量hadoop-env.sh配置成功,此时Hadoop具备了运行时的环境。
(3)配置环境变量 yarn-env.sh
vi ./etc/hadoop/yarn-env.sh
找到以下代码
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/
去掉注释,修改为以下代码
export JAVA_HOME=/home/java/jdk1.7.0_79
保存退出,Hadoop的YARN环境变量配置成功。此时,Hadoopd YARN模块具备了运行时的环境。
(4)配置核心组件 core-site.xml
这个xml文件是Hadoop集群的核心配置,是关于集群中分布式文件系统的入口地址和分布式文件系统中数据落地到服务器本地磁盘位置的配置。
vi core-site.xml
在
<property>
<name>fs.default.namename>
<value>hdfs://master:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/home/master/var/hadoop/tmpvalue>
property>
至此,hadoop集群的核心配置完成(slave节点的要设置对应的路径)。
(5)配置文件系统 hdfs-site.xml
vi hdfs-site.xml
在
<property>
<name>dfs.name.dirname>
<value>/home/master/var/hadoop/dfs/namevalue>
property>
<property>
<name>dfs.data.dirname>
<value>/home/master/var/hadoop/dfs/datavalue>
property>
<property>
<name>dfs.replicationname>
<value>2value>
property>
<property>
<name>dfs.permissionsname>
<value>falsevalue>
property>
至此,Hadoop集群的HDFS分布式文件系统数据块副本数配置完成。
(6)配置YARN资源系统 yarn-site.xml
vi yarn-site.xml
在
<property>
<name>yarn.resourcemanager.hostnamename>
<value>mastervalue>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.addressname>
<value>${yarn.resourcemanager.hostname}:8032value>
property>
<property>
<name>yarn.resourcemanager.scheduler.addressname>
<value>${yarn.resourcemanager.hostname}:8030value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.addressname>
<value>${yarn.resourcemanager.hostname}:8031value>
property>
<property>
<name>yarn.resourcemanager.admin.addressname>
<value>${yarn.resourcemanager.hostname}:8033value>
property>
<property>
<name>yarn.resourcemanager.webapp.addressname>
<value>${yarn.resourcemanager.hostname}:8088value>
property>
<property>
<name>yarn.resourcemanager.webapp.https.addressname>
<value>${yarn.resourcemanager.hostname}:8090value>
property>
<property>
<name>yarn.scheduler.maximum-allocation-mbname>
<value>2048value>
property>
<property>
<name>yarn.nodemanager.vmem-pmem-rationame>
<value>2.1value>
property>
<property>
<name>yarn.nodemanager.resource.memory-mbname>
<value>2048value>
property>
<property>
<name>yarn.nodemanager.vmem-check-enabledname>
<value>falsevalue>
property>
(7)配置计算框架 mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
在
<property>
<name>mapred.job.trackername>
<value>master:49001value>
property>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapred.local.dirname>
<value>/home/master/var/hadoop/varvalue>
property>
1)在master节点配置slaves
vi ./slaves
用下面的内容替换salves文件中的内容
slave1
slave2
slave3
2)复制到从节点
(8)配置 Hadoop 启动的系统环境变量
主从节点均执行以下操作
vi ~/.bash_profile
添加以下内容
export HADOOP_HOME=/home/master/local/hadoop-2.6.2
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source ~/.bash_profile
(9)创建数据目录
主从节点均执行以下操作
cd ~
mkdir var
cd var
mkdir hadoop
cd hadoop
mkdir tmp dfs var
cd dfs
mkdir name data
(10)启动Hadoop集群
Hadoop集群包含两个基本模块:分布式文件系统HDFS和分布式并行计算框架MapReduce。启动集群时,首先要做的就是在master节点上格式化分布式文件系统HDFS。
1)格式化文件系统
hdfs namenode -format
2)启动 Hadoop
start-all.sh
3)查看进程是否启动
jps
master 节点显示Jps,ResourceManager,SecondaryNameNode,NameNode表示主节点进程启动成功。
slave节点显示Jps,DataNode,NodeManager表示从节点启动成功。
4)Web UI查看集群启动是否成功
浏览器地址栏输入 http://192.168.216.101:50070
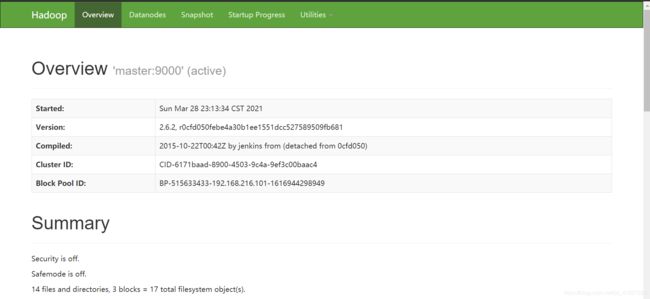
浏览器地址栏输入 http://192.168.216.101:8088

5)运行PI实例检查集群安装是否成功
cd ~/local/hadoop-2.6.2/share/hadoop/mapreduce/
hadoop jar hadoop-mapreduce-examples-2.6.2.jar pi 10 10
结果如下所示即为安装成功
Job Finished in 79.37 seconds
Estimated value of Pi is 3.20000000000000000000
至此,Hadoop集群安装启动成功。