网络模型剪枝-论文阅读-Network Slimming
论文地址:Learning Efficient Convolutional Networks through Network Slimming
这篇论文是在2017年的ICCV发表的,可以看做是之前讲过的channel pruning方法的变种,但是更加简单有效。
简单来说,这篇论文的剪枝方式是,给每个通道加上权重,在训练的过程中使用L1正则化对通道权重进行稀疏化,然后对于最终通道权重低于阈值的通道剪枝,最后重新训练得到剪枝模型。论文非常聪明的就是对batch normliization(BN)层的 γ \gamma γ参数进行L1稀疏化,所以很容易就能加入到现有网络架构中,并且很少损失精度。接下来就详细叙述该方法。
方法
之前的channel pruning方法需要计算所有卷积核的额外的正则化梯度,容易造成非平凡解,所以该论文提出了对每个通道引入 γ \gamma γ作为比例因子,以乘积的方式应用到通道中;然后同时训练网络权重和这些比例因子,并且使用稀疏正则化对比例因子进行选择;最后剪枝掉 γ \gamma γ值比较小的通道并且重训练剪枝后的网络。如图所示:

当一个通道被剪枝后,前一层和后一层中与其相关的通道和卷积核都会被移除,这样就得到了一个窄网络。
目标函数为:
L = ∑ ( x , y ) l ( f ( x , W ) , y ) + λ ∑ γ ∈ Γ g ( γ ) L = \sum_{(x,y)}l(f(x,W),y) + \lambda\sum_{\gamma \in \Gamma}g(\gamma) L=(x,y)∑l(f(x,W),y)+λγ∈Γ∑g(γ)
其中(x,y)为训练输入和输出,W为可训练的权重;上式第一项为CNN的常规损失函数,g(·)是稀疏惩罚项, λ \lambda λ是平衡系数。在实验中, g ( ⋅ ) = ∣ s ∣ g(·) = |s| g(⋅)=∣s∣,即L1-norm。在优化过程中,使用次梯度下降优化非平滑L1惩罚项,或者是使用smooth-L1作为惩罚项。
在BN层中应用比例因子
Batch Normalization是CNN中非常常用的一种优化方式,一般作用在激活层之前,它能使网络快速收敛和增加泛化性能。令zin和zout分别是BN层的输入和输出,B是当前的mini-batch,BN层是这样使用的:
z ^ = z i n − μ B σ B 2 + ϵ ; z o u t = γ z ^ + β \hat z = \frac {z_{in} - \mu_B}{\sqrt{\sigma_B^2 + \epsilon}};\ \ \ \ z_{out} = \gamma\hat z + \beta z^=σB2+ϵzin−μB; zout=γz^+β
其中 μ B \mu_B μB和 σ B \sigma_B σB是B的均值和标准差, γ \gamma γ和 β \beta β是可训练的仿射变换参数(scale和shift),它们提供了恢复任意尺度线性转换的可能性。
因为BN的作用就是对所有batch中的相同通道进行normalization操作,所以论文直接使用BN中的 γ \gamma γ参数当作网络剪枝的比例因子。论文分析了不这样做的后果:
- 如果直接使用 γ \gamma γ而不使用BN层,那么 γ \gamma γ对于通道来说仅仅是线性变换,即使缩小 γ \gamma γ也可以放大相应通道权重来弥补,无法达到特征选择目的;
- 如果在BN层之前使用 γ \gamma γ,该参数会被BN层完全抵消;
- 如果在BN层之后使用 γ \gamma γ,每个通道就会存在连续的两个比例参数。
剪枝和fine-tuneing
在通道级别的稀疏化后,很多比例因子接近于0,就可以通过移除所有相应输入、输出通道和对应的权重来把这些比例因子对应的通道剪枝。文中使用一个**全局阈值比例70%**来计算每一层的比例因子剪枝阈值。
当剪枝比例高的时候,剪枝可能会导致临时的精度损失,但是这些损失可以通过fine-tune大幅度地补偿,有时候甚至能达到更高的精度。
多次剪枝优化
如图所示,也可以使用多次优化的方式进行剪枝,使网络更加窄。实验证明,多次优化能得到更好的剪枝结果。

处理跨层连接和pre-activation结构
对于ResNet和DenseNet这种结构,BN层可能在卷积层之前(如下图中的resnet_v2的basicblock)。
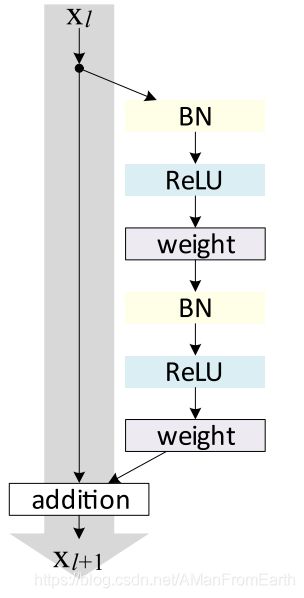
对于这种情况,稀疏化被应用在每层的最后,即该层会选择性地使用输入特征的某些通道。为了减少参数和计算,文中使用了一个channel selection层去除了被正则化稀疏掉的通道。
这里论文里说的不是很清楚,看pytorch源码分析吧:
对于bn2来说,正常使用剪枝,因为其输入通道是变化的(cfg参数变化);但是对于bn1来说,其输入通道是固定的,这是因为它输入之前的特征是参与shortcut的,所以不能直接进行剪枝使得通道数降低。对于这种情况,算法使用channel_selection模块,具体做法是对bn1未剪枝掉的通道进行选择(22行),选择后的结果就是剪枝结果,然后进行后续操作;同时shortcut中的residual没有被剪枝,就能进行相加操作(37行);对于bn3所对应的卷积核,输入通道进行剪枝,但是输出不进行剪枝。
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, cfg, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.bn1 = nn.BatchNorm2d(inplanes)
self.select = channel_selection(inplanes)
self.conv1 = nn.Conv2d(cfg[0], cfg[1], kernel_size=1, bias=False)
self.bn2 = nn.BatchNorm2d(cfg[1])
self.conv2 = nn.Conv2d(cfg[1], cfg[2], kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn3 = nn.BatchNorm2d(cfg[2])
self.conv3 = nn.Conv2d(cfg[2], planes * 4, kernel_size=1, bias=False)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.bn1(x)
out = self.select(out)
out = self.relu(out)
out = self.conv1(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn3(out)
out = self.relu(out)
out = self.conv3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
return out
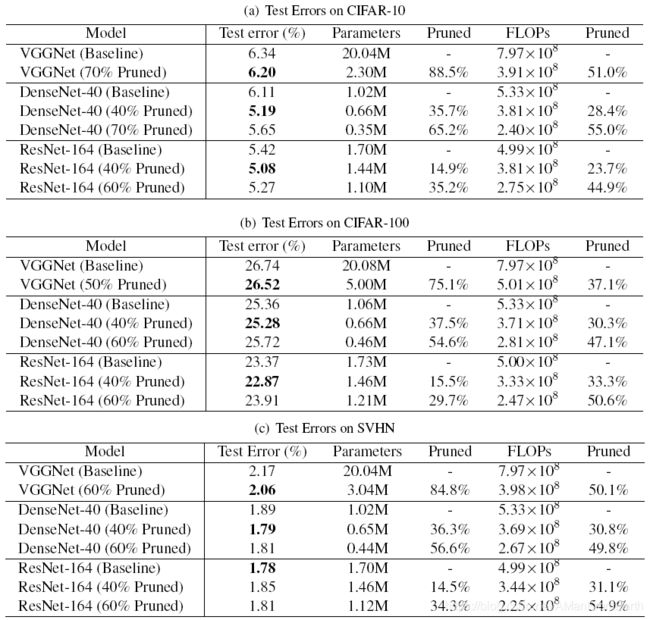
实验
实验看下面的表格就行了,结果还是挺好的。
以上就是该论文的主要内容了。