基于聚类算法的话术挖掘技术及在营销服场景的落地应用
关键词:话术挖掘、云呼叫中心、智能客服、智能质检、智能陪练、智能助手、金牌销售、提升业绩
聚类算法介绍
聚类的概念
聚类是数据挖掘中的一个概念,是按照某个特定标准(如距离)把一个数据集分割成为不同的类或者簇,使得同一个类内的数据对象的相似性尽可能大,同时不在同一个类内的数据对象的差异性也尽可能得大。即聚类后的同一类数据尽可能聚集到一起,不同类的数据尽量分离。
聚类分析在许多产品或服务场景内均有很重要的用途,如谷歌新闻等很多应用都将聚类算法作为主要实现手段,利用大量未标注数据构建强大的主题聚类;再比如用户画像产品中,也依赖聚类分析对目标客户群体进行多指标的群里划分,只有进行正确的分类,才能有效的进行个性化和精细化的运营服务。
聚类和分类的区别
聚类,简单地说就是把相似的数据分到一类,聚类的时候并不关心某一类具体是什么,聚类需要实现的目标只是把相似的数据聚到一起。
分类,通常对应一个或多个已经提前定义好的分类,只需要将数据划分为某个分类内即可。
聚类就是无监督学习(unsupervisedlearning)的一种,对于无标签的数据,我们可以发现无标签数据中的潜在信息;而分类却是一种典型的监督学习(supervisedlearning),对于有标签的数据,我们需进行有监督的学习,从而具备对未知数据进行分类的能力。
常见的聚类算法介绍
聚类算法的种类较多,按照不同的划分方式会有多种分法,这里简单介绍几种业内较为典型且应用最多的算法:
K-Means算法
K-Means是较为基础的聚类算法,其需预先指定聚类数目或聚类中心,反复迭代逐步降低目标函数误差值直至收敛,得到最终结果,如下图示意:
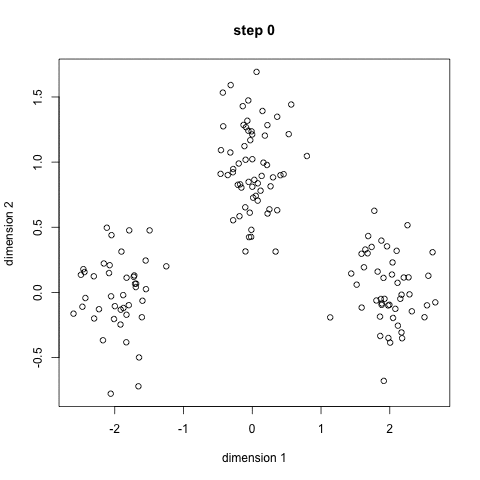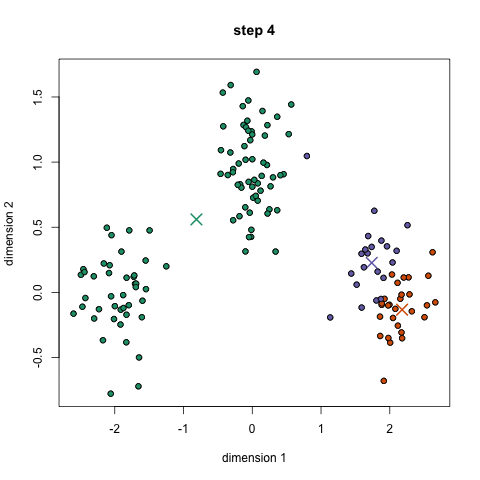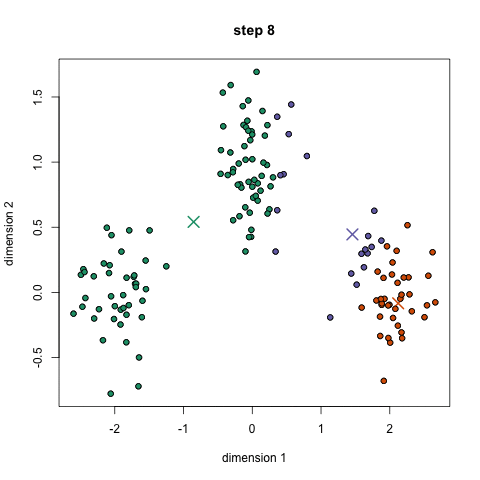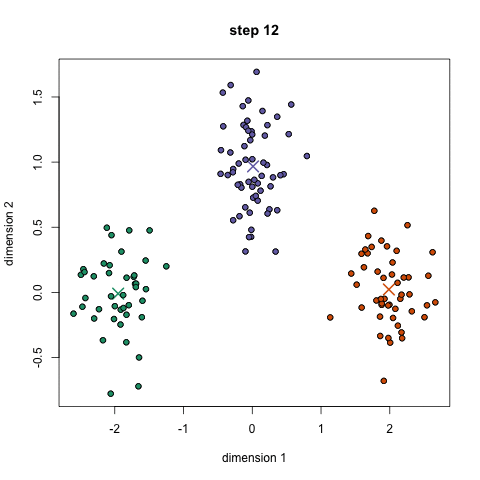
K-Means的主要优势在于性能优异,速度非常快,因为只是计算点与群中心之间的距离。但缺点也较为明显,首先K-Means必须指定有多少类,即分类的个数,其次因为K-Means是随机选择的聚类中心后开始处理的,所以它有可能在不同的算法中产生不同的聚类结果,因此结果可能不可重复且缺乏一致性。
BIRCH算法
BIRCH属于层次聚类算法的一种,其利用树结构对数据集进行处理,一开始将每个数据点视为一个单一的聚类,然后依次合并类,直到所有类合并成一个包含所有数据点的单一聚类。
BIRCH不再需要我们指定类或簇的数量,另外该算法对于距离度量标准的选择并不敏感,对于不同的度量标准它的表现同样很好,而对于其他聚类算法,距离度量标准的选择是至关重要的。
均值漂移聚类算法
均值漂移是一种基于滑动窗口(sliding-window)实现的聚类算法,通过将目标定位在每个组/类的中心点,中心点的候选点更新为滑动窗口内点的均值,之后在后处理阶段对这些候选窗口进行过滤以消除近似重复,形成最终的中心点集及其相应的组。

均值漂移算法与K-Means相比,其不需要设定分类数量,因为它自动发现这一点,这是一个很大的优势;聚类中心收敛于最大密度点的事实也是非常可取的,因为它非常直观地理解并适合于一种自然数据驱动。缺点是选择窗口大小/半径r是非常关键的,所以不能疏忽。
中关村科金聚类算法的最新研究实践成果
SCCL框架介绍
目前业内传统的聚类模型(Clustering)整体效果还不错,但相邻类别黏在一起,无法区分的现象仍然存在,实际使用下来效果并不是太理想,如下图所示:
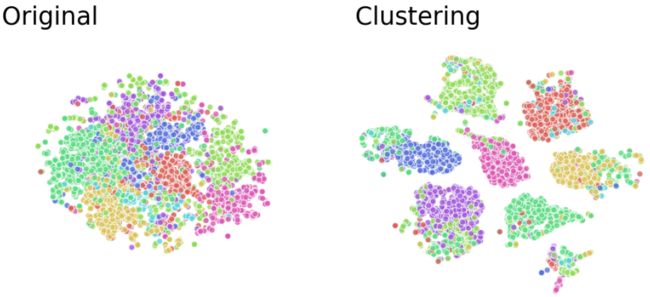
传统聚类模型(Clustering)的效果分布
我们推出的话术挖掘产品,采用了当前业内最新的SCCL训练框架将对比学习(Instance-CL)和聚类模型(Clustering)相结合,相比传统的训练框架,SCCL在多个评估指标上均效果更优,其主要的框架流程如下图所示:
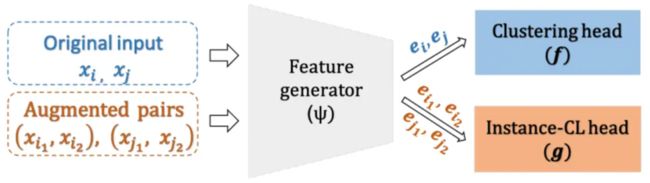
SCCL由3部分组成:神经网络特征抽取层、clusteringhead 和Instance-CLhead。特征抽取层将输入映射到向量表示空间,SCCL是使用SentenceTransformer 发布的distilbert-base-nli-stsb-mean-tokens预训练模型;clusteringhead则是一个线性映射层,维度是768*K,其中K是聚类的类别数量。Instance-CLhead (记为g)和clusteringhead (记为f)中,分别使用contrastiveloss 和clusteringloss。Instance-CLhead由[单层MLP]组成,其激活函数使用的是ReLU,输入维度是768,输出维度是128。所以如上图所示,整体网络结构非常简洁明了。
而SCCL框架用到的对比学习(Instance-CL),主要是通过数据增强去生成和原句语义相似的句子,两个增强句子来自同一个原句子,那么它们是同源的,否则是不同源的;通过将同源句子在向量空间内拉近,将非同源句子在向量空间中远离,从而达到更优的聚类效果。
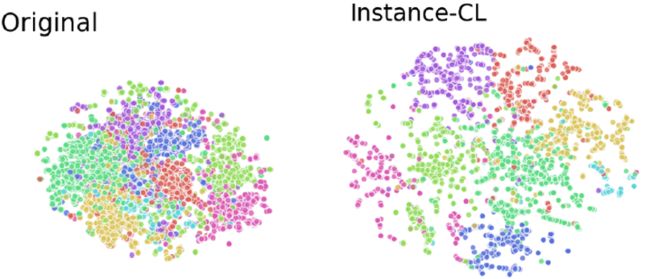
对比学习(Instance-CL)分散后的效果分布
更进一步,我们将对比学习(Instance-CL)和聚类模型(Clustering)相结合,会发现不仅可以更好的区分类别,而且通过拉近同一类数据的距离,可以促进类内距离更加紧凑,从而达到更优质的聚类效果。
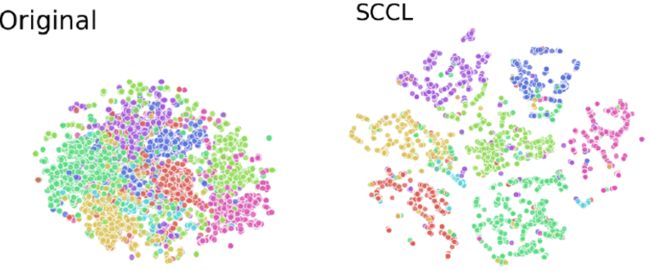
Instance-CL和Clustering结合成SCCL的效果分布
该方法的步骤为:
-
在原始样本集合上,对每一个样本进行增强两个样本;
-
将原始样本和增强后的样本通过Featuregenerator来获得对应的向量表示特征;
-
对增强得到的样本经过Instance-CLhead,并计算其loss。这个loss中,我们希望同一样本增强得到的新样本之间的距离更近,不同样本增强得到的新样本距离更远;
-
对原始样本经过Clusteringhead,进行聚类,并计算loss;
-
结合对比学习的loss和聚类的loss,训练模型,最终得到效果较优的聚类结果。
实验结果对比
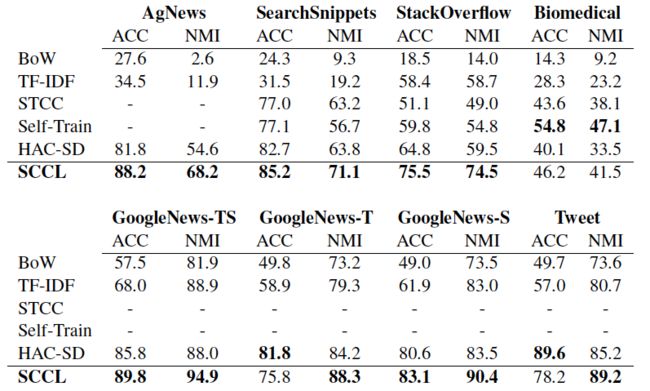
为了验证SCCL的效果,我们选择STTC、Self-Train等几个代表了最新技术的模型作为基线,在八个用于短文本聚类的基准数据集上进行对比实验,采用ACC(Accuracy)和NMI(NormalizedMutual Information)两个评估指标来衡量聚类效果,SCCL在大多数的数据集上的表现均优于所有基线,综合效果得到了显著提升。
基于聚类算法落地实现的话术挖掘
话术挖掘介绍
多渠道的数据对接
中关村科金使用的话术挖掘对接了得助云呼叫中心、得助智能文本客服、企业微信、得助智能质检、得助智能助手、得助智能陪练等多个产品内的会话数据,且支持用户手动上传数据进行挖掘。
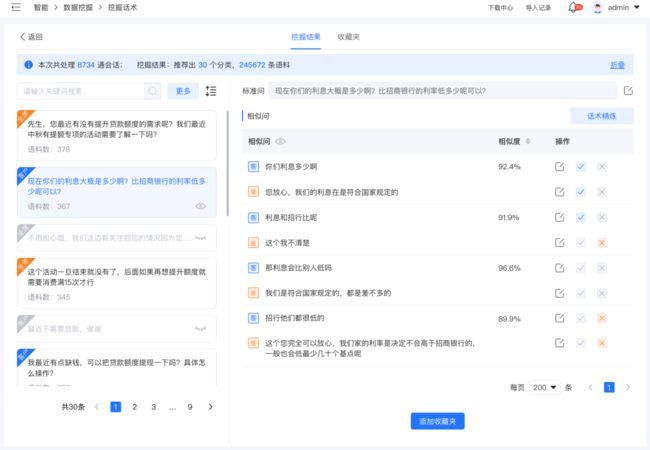
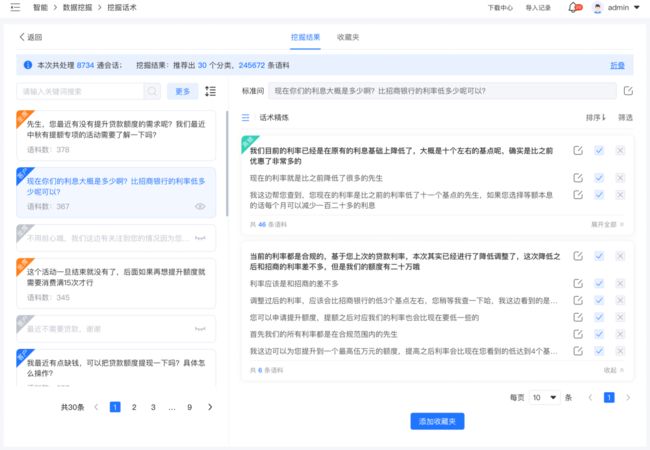
挖掘聚类结果采纳分析
对会话数据进行聚类分析处理,聚类得到的结果分组呈现,用户可按照分组进行采纳分析,有效减少话术整理的工作量。
模型的自训练调优
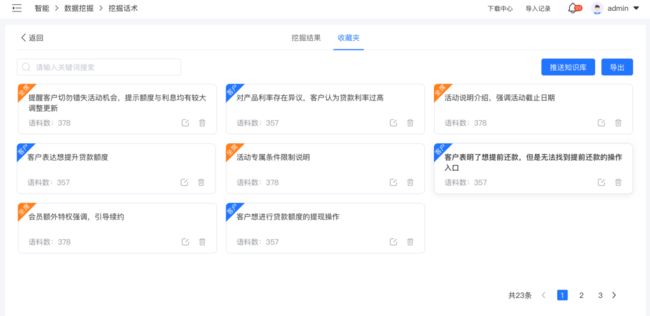
用户在整理标注结果时,产生的一些行为数据,如语料的采纳、舍弃、添加收藏夹等操作,实时收集并自动反哺训练模型,提升聚类模型的效果。
挖掘结果便捷输出
挖掘整理出的结果,可直接推送至助手和陪练机器人的知识库内,也可一键导出数据。
灵活筛选金牌销售会话
对接了各系统的随路字段,支持用户结合各个业务字段筛选会话数据,快速定位到优秀业务人员的会话内容,针对性挖掘优秀话术。
价值点介绍
优秀话术挖掘
通过分析金牌销售的会话数据,挖掘出对成单有促进作用或决定性作用的话术,将其作为优秀话术供团队学习,提升销售业绩,尤其对于绩效较差的销售人员,通过学习培训话术挖掘生产的话术,成单量普遍提升50%以上,整体团队业绩可提升10%以上。
通过前后的数据对比发现,数据挖掘上线之后,平均单个专项话术的生产工作量,由两周左右可缩短至两人天,相比传统话术生产方式更快,不再需要话术团队逐字逐句人工听电话录音,话术生产成本可降低85%。
客户异议应答话术挖掘
客户提出异议后,优秀的业务人员通常会做出更好的异议处理应对,话术挖掘可以帮助话术团队,快速挖掘出优秀的业务人员是如何处理客户异议的,从而丰富话术库,避免潜在客户流失。对此,我们通过某个金融行业客户的销售团队进行验证,帮助该电销团队的客户流失率成功降低了21%。
新意图挖掘
可帮助业务团队发现客户新的意图、疑问、关注点,快速洞察市场趋势,及时补充知识库,调整业务策略。
总结
基于聚类算法的话术挖掘可有效帮助企业的销售团队提升业绩,降低话术生产成本。中关村科金基于业内领先的聚类算法框架打造的话术挖掘产品,已广泛应用于保险电销、银行理财营销、房地产销售案场、汽车门店销售等多个行业的业务场景,帮助企业更有效的利用数据资产赋能业务团队快速发展。