【代码复现】NER之GlobalPointer解析
前言
在NER任务中,主要分为三类实体:嵌套实体、非嵌套实体、不连续实体,今天分享方法以end-to-end的方式解决前两个问题,GlbalPointer,它利用全局归一化的思路来进行命名实体识别(NER),可以无差别地识别嵌套实体和非嵌套实体,在非嵌套(Flat NER)的情形下它能取得媲美CRF的效果,而在嵌套(Nested NER)情形它也有不错的效果。
核心思想

GlobalPointer是一种基于span分类的解码方法,它将首尾视为一个整体去进行判别,所以它更有“全局观”(更Global)。而且也保证了训练、预测、上线评估都是以实体级进行评测。
任务建模,按照实体类型数量和max_len的长度生成三维矩阵**(ent_type_size, max_seq_len, max_seq_len)**,按照实体类型dix,实体start_idx, 实体end_idx填入三维矩阵中并赋值为1
import numpy as np
labels = np.zeros((3,12,12)) # 代表 3种实体类型 句子长度为12
labels[1][0][1] = 1 # 实体类型为1 (start_idx,end_idx)=(0,1)填写为1
模型架构
模型 torch代码如下:
class GlobalPointer(nn.Module):
def __init__(self, encoder, ent_type_size, inner_dim, RoPE=True):
super().__init__()
self.encoder = encoder
self.ent_type_size = ent_type_size
self.inner_dim = inner_dim
self.hidden_size = encoder.config.hidden_size
self.dense = nn.Linear(self.hidden_size, self.ent_type_size * self.inner_dim * 2)
self.RoPE = RoPE # 是否使用RoPE
def sinusoidal_position_embedding(self, batch_size, seq_len, output_dim):
position_ids = torch.arange(0, seq_len, dtype=torch.float).unsqueeze(-1)
indices = torch.arange(0, output_dim // 2, dtype=torch.float)
indices = torch.pow(10000, -2 * indices / output_dim)
embeddings = position_ids * indices
embeddings = torch.stack([torch.sin(embeddings), torch.cos(embeddings)], dim=-1)
embeddings = embeddings.repeat((batch_size, *([1]*len(embeddings.shape))))
embeddings = torch.reshape(embeddings, (batch_size, seq_len, output_dim))
embeddings = embeddings.to(self.device)
return embeddings
def forward(self, input_ids, attention_mask, token_type_ids):
self.device = input_ids.device
context_outputs = self.encoder(input_ids, attention_mask, token_type_ids)
# last_hidden_state:(batch_size, seq_len, hidden_size)
last_hidden_state = context_outputs[0]
batch_size = last_hidden_state.size()[0]
seq_len = last_hidden_state.size()[1]
# outputs:(batch_size, seq_len, ent_type_size*inner_dim*2)
outputs = self.dense(last_hidden_state)
outputs = torch.split(outputs, self.inner_dim * 2, dim=-1)
# outputs:(batch_size, seq_len, ent_type_size, inner_dim*2)
outputs = torch.stack(outputs, dim=-2)
# qw,kw:(batch_size, seq_len, ent_type_size, inner_dim)
qw, kw = outputs[...,:self.inner_dim], outputs[...,self.inner_dim:] # TODO:修改为Linear获取?
if self.RoPE:
# pos_emb:(batch_size, seq_len, inner_dim)
pos_emb = self.sinusoidal_position_embedding(batch_size, seq_len, self.inner_dim)
# cos_pos,sin_pos: (batch_size, seq_len, 1, inner_dim)
cos_pos = pos_emb[..., None, 1::2].repeat_interleave(2, dim=-1)
sin_pos = pos_emb[..., None,::2].repeat_interleave(2, dim=-1)
qw2 = torch.stack([-qw[..., 1::2], qw[...,::2]], -1)
qw2 = qw2.reshape(qw.shape)
qw = qw * cos_pos + qw2 * sin_pos
kw2 = torch.stack([-kw[..., 1::2], kw[...,::2]], -1)
kw2 = kw2.reshape(kw.shape)
kw = kw * cos_pos + kw2 * sin_pos
# logits:(batch_size, ent_type_size, seq_len, seq_len)
logits = torch.einsum('bmhd,bnhd->bhmn', qw, kw)
# padding mask
pad_mask = attention_mask.unsqueeze(1).unsqueeze(1).expand(batch_size, self.ent_type_size, seq_len, seq_len)
# pad_mask_h = attention_mask.unsqueeze(1).unsqueeze(-1).expand(batch_size, self.ent_type_size, seq_len, seq_len)
# pad_mask = pad_mask_v&pad_mask_h
logits = logits*pad_mask - (1-pad_mask)*1e12
# 排除下三角
mask = torch.tril(torch.ones_like(logits), -1)
logits = logits - mask * 1e12
return logits/self.inner_dim**0.5
生成RoPE:
GlobalPoint核心思想是引入了RoPE(旋转式位置编码):
对于位置 m m m,RoPE会计算出一个正交矩阵 R m R_{m} Rm,将 R m R_{m} Rm与 q q q相乘便实现对 q q q进行旋转,如果 q q q 是二维,有:
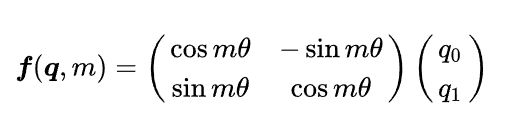
对于高阶偶数维的 q q q ,有:

其中 θ i \theta_i θi是怎么得到的?
介绍一下Sinusoidal位置编码

RoPE在θi的选择上,采用了Sinusoidal位置编码的方案,即 θ i = 1000 0 ( − 2 i / d ) \theta _i = 10000^{(-2i/d)} θi=10000(−2i/d) 它可以带来一定的远程衰减性。
有关torch.stack可参考这篇文章
def sinusoidal_position_embedding(self, batch_size, seq_len, output_dim):
position_ids = torch.arange(0, seq_len, dtype=torch.float).unsqueeze(-1) # 生成绝对位置信息
indices = torch.arange(0, output_dim // 2, dtype=torch.float) # 由Sinusoidal公式可知 i的范围是 0 -> d/2
indices = torch.pow(10000, -2 * indices / output_dim) # 公式计算得到theta_i
embeddings = position_ids * indices # 生成带theta的embedding
embeddings = torch.stack([torch.sin(embeddings), torch.cos(embeddings)], dim=-1) # 引入cosm sinm 在最后维度进行堆叠
embeddings = embeddings.repeat((batch_size, *([1]*len(embeddings.shape)))) # 扩展到整个batch_size种
embeddings = torch.reshape(embeddings, (batch_size, seq_len, output_dim)) # 修改为输出维度
embeddings = embeddings.to(self.device)
return embeddings
其中stack操作如下图所示:

torch.repeat 操作 可以将1维信息扩展到多维信息中
x = torch.tensor([1, 2, 3])
> tensor([1, 2, 3])
(3, *([1]*len(x.shape)))
> (3, 1)
x = x.repeat((3, *([1]*len(x.shape))))
>tensor([[1, 2, 3],
[1, 2, 3],
[1, 2, 3]])
由苏神的讲解可知,RoPE的计算可以简化为如下图。

在 q q q和 k k k中融入RoPE:
于是以此类推,如果将 k k k 也乘上旋转位置编码,此时span的分数 s ( i , j ) s(i,j) s(i,j) 就会带有相对位置信息(也就是 R i − j R_{i-j} Ri−j):

if self.RoPE:
# pos_emb:(batch_size, seq_len, inner_dim)
pos_emb = self.sinusoidal_position_embedding(batch_size, seq_len, self.inner_dim) # 上一步得到RoPE
# cos_pos,sin_pos: (batch_size, seq_len, 1, inner_dim)
cos_pos = pos_emb[..., None, 1::2].repeat_interleave(2, dim=-1)
sin_pos = pos_emb[..., None,::2].repeat_interleave(2, dim=-1)
qw2 = torch.stack([-qw[..., 1::2], qw[...,::2]], -1)
qw2 = qw2.reshape(qw.shape)
qw = qw * cos_pos + qw2 * sin_pos
kw2 = torch.stack([-kw[..., 1::2], kw[...,::2]], -1)
kw2 = kw2.reshape(kw.shape)
kw = kw * cos_pos + kw2 * sin_pos
有关切片操作可看这篇文章
其中:
… 操作表示自动判断其中得到维度区间
None 增加一维 **
** ::2 两个冒号直接写表示从所有的数据中隔行取数据。从0开始
1::2 两个冒号直接写表示从所有的数据中隔行取数据。从1开始
repeat_interleave操作:复制指定维度的信息
x = torch.tensor([1, 2, 3])
>tensor([1, 2, 3])
x.repeat_interleave(2)
>tensor([1, 1, 2, 2, 3, 3])
y = torch.tensor([[1, 2], [3, 4]])
>tensor([[1, 2],
[3, 4]])
torch.repeat_interleave(y, 2)
>tensor([1, 1, 2, 2, 3, 3, 4, 4])
torch.repeat_interleave(y, 3, dim=1)
>tensor([[1, 1, 1, 2, 2, 2],
[3, 3, 3, 4, 4, 4]])
让我们再次看一遍这个计算公式:
这时可以发现:
cos_pos = pos_emb[..., None, 1::2].repeat_interleave(2, dim=-1) # 是将奇数列信息抽取出来也就是cosm 拿出来并复制
sin_pos = pos_emb[..., None,::2].repeat_interleave(2, dim=-1) # 是将偶数列信息抽取出来也就是sinm 拿出来并复制
qw2 = torch.stack([-qw[..., 1::2], qw[...,::2]], -1) # 奇数列加上负号 得到第二个q的矩阵
qw = qw * cos_pos + qw2 * sin_pos # 最后融入位置信息
计算kw 也是同理步骤
## 最后计算初logits 结果
logits = torch.einsum('bmhd,bnhd->bhmn', qw, kw) # 相等于先对qw做转置 然后qw与kw做矩阵乘法
torch.einsum :
可以简单实现向量内积,向量外积,矩阵乘法,转置和张量收缩(tensor contraction)等张量操作
可参考这篇文章
torch.expand
参考这篇文章
以上就是对GlobalPoint模型主要的要点进行解析,如果你还有什么问题,可以留言,一起讨论啊
参考代码链接:https://github.com/gaohongkui/GlobalPointer_pytorch