FSCIL论文详解 Few-Shot Class-Incremental Learning, CVPR2020
CVPR2020
论文地址:
https://arxiv.org/pdf/2004.10956.pdf
CVPR2020 本篇,FSCIL,西交大提出的。将NG网络运用到增量学习之中。
ECCV2020,TPCIL,也是西交大的同一个人发的,Topology Preserving Class-Incremental learning,同样的框架,即CNN+拓扑结构,部分内容换了一个写法。
CVPR2021与本篇非常类似,Few-Shot Incremental Learning with Continually Evolved Classifiers,南洋理工大学提出,也是运用Graph的知识,将GAT(Graph Attention Network)用于增量学习。
CEC论文详解Few Shot Incremental Learning with Continually Evolved Classifiers. CVPR2021_祥瑞的技术博客-CSDN博客
基于拓扑结构的增量学习:
CVPR2020 ,FSCIL Few-shot Class Incremental Learning。将NG网络运用到增量学习之中。
FSCIL论文详解 Few-Shot Class-Incremental Learning, CVPR2020_祥瑞的技术博客-CSDN博客
ECCV2020,TPCIL,本篇,Topology Preserving Class-Incremental learning,同样的框架,即CNN+拓扑结构,部分内容换了一个写法。
基于拓扑的增量学习Topology Preserving Class-Incremental learning论文详解ECCV2020_祥瑞的技术博客-CSDN博客
CVPR2021与本篇非常类似,Few-Shot Incremental Learning with Continually Evolved Classifiers,南洋理工大学提出,也是运用Graph的知识,将GAT(Graph Attention Network)用于增量学习。
Few Shot Incremental Learning with Continually Evolved Classifiers论文详解 基于持续进化分类器的小样本类别增量学习CVPR2021_祥瑞的技术博客-CSDN博客
目录
一、贡献点
二、方法
2.1 NG网络
2.2 AL loss
2.3 MML loss
四、总结
一、贡献点
作者定义了,小样本增量学习问题few-shot class-incremental learning (FSCIL)
小样本增量学习面临下面这些问题:
- 灾难性遗忘,也是增量学习普遍存在的问题。学习新类会改变旧类在特征空间中的拓扑关系。
- 异质数据差异。此前多种方法采用知识蒸馏来保存旧特征的拓扑结构,但是对于异质性数据而言,知识蒸馏并不能很好的适应。
- 过拟合,因为新增样本过少,导致网络过拟合
作者贡献点分三个:
- NG网络,Neural gas network,此网络不是作者提出的,但是作者把这种拓扑结构的网络用在了增量学习之中
- AL loss(ancher loss),用于解决灾难性遗忘的问题,避免网络经过了增量任务训练之后在base上变化过大
- MML loss (min-max loss),让同类别的样本在拓扑空间中的距离尽可能接近
二、方法
2.1 NG网络
NG网络最早在1991年提出,被作者应用于此任务之中。用拓扑关系来模拟feature空间上的关系。本文将特征提取后的特征空间上的位置做为NG网络的输入。
NG网络由图模型构成,具有节点和边。节点定义为vj,它会有一个质量中心mj, 用来描述该节点在特征空间中的位置。如果节点j和节点i之间的关系是邻接的,那么对应的边eji就是1,不邻接eji相当于0,每个边带有一个年龄参数,aji, 初始化为0,当年龄参数aji大于某一个阈值之后,该节点就会断开。
给定一个输入f,则根据输入到各个节点的距离d(f,mj)分配给最近的节点vj,然后更新其到所有节点的特征质心m
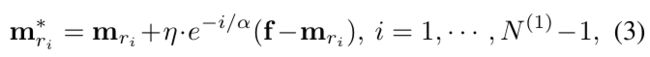
f-m前面的系数是衰减系数,即输入f与其他节点的距离越近,则更新量越多,离其他节点距离越远,则更新越少。接下来更新所有节点之间的边与年龄参数。
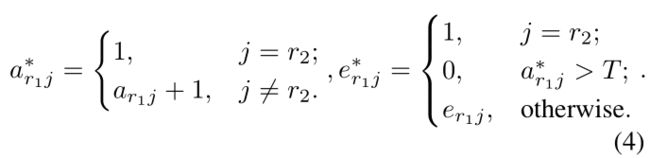
每一次更新,节点之间的年龄增加1,如果年龄大于某个阈值,就断掉该连接。
通过NG网络,即相当于增量样本到来之后,feature空间上越近,则在NG网络中的拓扑关系越近,随着增量样本越来越多,联接关系随之更新。
2.2 AL loss
AL用于解决灾难性遗忘的问题,使得旧模型与新模型尽可能的接近。

AL loss使得模型旧结构与新结构的距离越近越好,减少节点v在特征空间之中的变动。
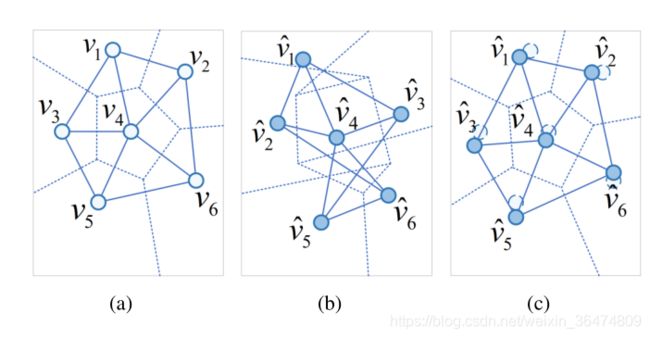
例如图a,不加AL loss训练之后特征空间的关系为图b,节点之间位置关系变化距离。加入AL loss之后变化为图c,节点与节点之间距离更近。
2.3 MML loss
MML用于使得模型更具有区分性。
假定新样本x到来,它是y类的,经过特征提取后位置是f(x;Θ),网络希望它与同类样本的距离越近越好,与非同类样本的距离越远越好。就按照上面的MML loss的形式,拉近同类样本之间的距离,拉远不同类样本之间的距离。

加入MML loss之后的效果如上图,如果不加入MML loss,则f会被误分配给节点v5,但是实际上它与节点v7是同类,因此MML loss会拉近f与v7的距离,同时让非同类的距离v5和v7的距离更远。
最终的loss是交叉熵+AL +MML

四、总结
本文题目较为唬人,很短,小样本增量学习问题,看起来仿佛是ICML或者NIPS级别的论文,以为文中会充满大量的理论论述,但是实际上只是提出了这个问题,并且给出了其中的一种可行的解决方案,所以只能是CVPR级别的论文。
亮点:
- 将新增类别之间的关系转换为了拓扑的关系
- 将拓扑网络(NG网络)应用到了增量学习任务中,因此可以用到一些拓扑的loss,比如ancher loss和min-max loss (AL & MML)
近些年来增量学习大趋势,就是两个分类网络,一个是特征提取,用于提取特征,第二个是分类器或者Graph模型,用于模拟增量特征之间的关系。