keras构建卷积神经网络
输入相关的库
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
print("TensorFlow version:", tf.__version__)TensorFlow version: 2.6.4
导入数据
fashion_mnist = tf.keras.datasets.fashion_mnist
(x_train, y_train),(x_test, y_test) = fashion_mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
x_train = x_train[..., tf.newaxis].astype("float32")
x_test = x_test[..., tf.newaxis].astype("float32")
train_ds = tf.data.Dataset.from_tensor_slices(
(x_train, y_train)).shuffle(10000).batch(128)
test_ds = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(128)2022-10-17 02:24:49.792549: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2022-10-17 02:24:49.895220: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2022-10-17 02:24:49.896028: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2022-10-17 02:24:49.902715: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 AVX512F FMA To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags. 2022-10-17 02:24:49.903033: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2022-10-17 02:24:49.903894: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2022-10-17 02:24:49.904866: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2022-10-17 02:24:52.155655: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2022-10-17 02:24:52.156422: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2022-10-17 02:24:52.157115: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2022-10-17 02:24:52.157726: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1510] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 15401 MB memory: -> device: 0, name: Tesla P100-PCIE-16GB, pci bus id: 0000:00:04.0, compute capability: 6.0
inputs = keras.Input(shape=(28,28,1))
x = inputs
for size in [32,64,128]:
x = layers.Conv2D(size, 3, strides=1, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
x = layers.MaxPooling2D((2, 2))(x)
x = layers.Conv2D(256, 3, strides=1, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
x = layers.GlobalAveragePooling2D()(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(10, activation='softmax')(x)
model = keras.Model(inputs, outputs)
model.summary()2022-10-17 02:39:04.385252: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2022-10-17 02:39:04.503544: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2022-10-17 02:39:04.504713: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2022-10-17 02:39:04.506969: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 AVX512F FMA To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags. 2022-10-17 02:39:04.507300: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2022-10-17 02:39:04.508303: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2022-10-17 02:39:04.509206: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2022-10-17 02:39:07.153982: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2022-10-17 02:39:07.155140: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2022-10-17 02:39:07.156582: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2022-10-17 02:39:07.157460: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1510] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 15401 MB memory: -> device: 0, name: Tesla P100-PCIE-16GB, pci bus id: 0000:00:04.0, compute capability: 6.0
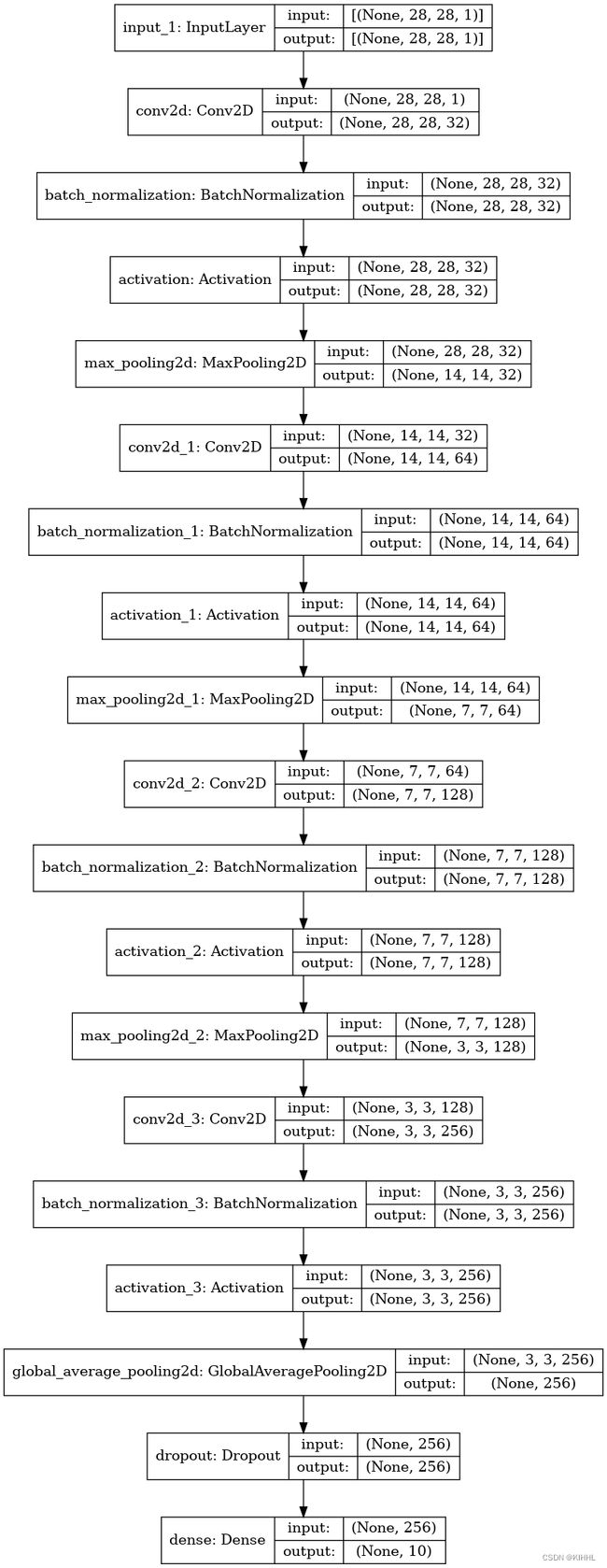
Model: "model" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) [(None, 28, 28, 1)] 0 _________________________________________________________________ conv2d (Conv2D) (None, 28, 28, 32) 320 _________________________________________________________________ batch_normalization (BatchNo (None, 28, 28, 32) 128 _________________________________________________________________ activation (Activation) (None, 28, 28, 32) 0 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 14, 14, 32) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 14, 14, 64) 18496 _________________________________________________________________ batch_normalization_1 (Batch (None, 14, 14, 64) 256 _________________________________________________________________ activation_1 (Activation) (None, 14, 14, 64) 0 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 7, 7, 64) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 7, 7, 128) 73856 _________________________________________________________________ batch_normalization_2 (Batch (None, 7, 7, 128) 512 _________________________________________________________________ activation_2 (Activation) (None, 7, 7, 128) 0 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 3, 3, 128) 0 _________________________________________________________________ conv2d_3 (Conv2D) (None, 3, 3, 256) 295168 _________________________________________________________________ batch_normalization_3 (Batch (None, 3, 3, 256) 1024 _________________________________________________________________ activation_3 (Activation) (None, 3, 3, 256) 0 _________________________________________________________________ global_average_pooling2d (Gl (None, 256) 0 _________________________________________________________________ dropout (Dropout) (None, 256) 0 _________________________________________________________________ dense (Dense) (None, 10) 2570 ================================================================= Total params: 392,330 Trainable params: 391,370 Non-trainable params: 960 _________________________________________________________________
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(train_ds, epochs=10)Epoch 1/10
2022-10-17 02:32:49.166692: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:185] None of the MLIR Optimization Passes are enabled (registered 2) 2022-10-17 02:32:50.227935: I tensorflow/stream_executor/cuda/cuda_dnn.cc:369] Loaded cuDNN version 8005
469/469 [==============================] - 10s 6ms/step - loss: 0.4292 - accuracy: 0.8470 Epoch 2/10 469/469 [==============================] - 3s 6ms/step - loss: 0.2820 - accuracy: 0.8995 Epoch 3/10 469/469 [==============================] - 3s 6ms/step - loss: 0.2367 - accuracy: 0.9129 Epoch 4/10 469/469 [==============================] - 3s 6ms/step - loss: 0.2112 - accuracy: 0.9231 Epoch 5/10 469/469 [==============================] - 3s 7ms/step - loss: 0.1950 - accuracy: 0.9294 Epoch 6/10 469/469 [==============================] - 3s 6ms/step - loss: 0.1708 - accuracy: 0.9377 Epoch 7/10 469/469 [==============================] - 3s 6ms/step - loss: 0.1561 - accuracy: 0.9434 Epoch 8/10 469/469 [==============================] - 3s 6ms/step - loss: 0.1398 - accuracy: 0.9481 Epoch 9/10 469/469 [==============================] - 3s 6ms/step - loss: 0.1300 - accuracy: 0.9518 Epoch 10/10 469/469 [==============================] - 3s 6ms/step - loss: 0.1137 - accuracy: 0.9586
model.evaluate(test_ds)79/79 [==============================] - 0s 3ms/step - loss: 0.2961 - accuracy: 0.9086