Yolov5训练自己的数据集+TensorRT加速+Qt部署
本人由于项目要求,需要利用Yolov5网络训练自己的目标检测与分类模型,并利用TensorRT加速将其部署到Qt界面上。目前已经实现了整个流程,写下这篇博客供需要的各位参考。(本文描述的重点主要是在后续对经过加速的模型进行打包后在Qt中进行部署实现,其余过程可以参考文中相应链接的博客与视频)
目录
一、环境配置
二、在Pycharm中利用Yolov5网络进行模型训练
2.1 Yolov5下载
2.2 训练自己的数据集
三、利用TensorRT进行模型的加速
3.1 生成.wts文件
3.2 生成.engine文件
四、对模型进行封装
五、利用Qt进行部署
5.1 Qt的安装
5.2 Qt与VS2017相关联
5.3 进行模型的部署
5.3.1 在VS中创建新的Qt项目
5.3.2 进行环境的配置
5.3.3 添加.cu文件
5.3.4编写Qt代码
一、环境配置
该项目工程配置的环境是:
Win10
cuda 11.3
cudnn 8.2.0
TensorRT 8.2.1.8
Visual Studio 2017
Opencv 4.1.0
Qt 5.14.2
二、在Pycharm中利用Yolov5网络进行模型训练
2.1 Yolov5下载
Yolov5的源代码下载链接:https://github.com/ultralytics/yolov5
在下载Yolov5源代码时,需要留意下载的版本(需要与后续利用TensorRT加速的版本相同),笔者这里当时也不太了解,因此就是直接下载了master,也就是默认。
2.2 训练自己的数据集
训练自己的数据集,需要先使用labelImg进行图像标注,然后进行数据集的划分以及相应配置文件的更改。具体的步骤可以参考这位大佬写的博客:Yolov5训练自己的数据集(详细完整版)_缔宇diyu的博客-CSDN博客_yolov5训练自己的数据集
也可以观看这个视频了解学习Yolov5的网络架构和训练:带你一行行读懂yolov5代码,yolov5源码_哔哩哔哩_bilibili
调整好自己相应的模型和数据集之后,在Pycharm的Terminal中输入命令:
python train.py --weights weights/yolov5s.pt --cfg models/yolov5s.yaml --data data/myvoc.yaml --batch-size 8 --img 640 --device 0可以根据自己的需要去修改相应的参数,模型训练完成后会得到.pt文件,后面会利用该文件生成.wts文件去进行模型的加速。
三、利用TensorRT进行模型的加速
本文采用的技术路线是:.pt文件→.wts文件→.engine文件。利用TensorRT进行Yolov5模型推理,需要下载tensorrtx,具体的下载链接:https://github.com/wang-xinyu/tensorrtx,注意!笔者个人理解这里的tensorrtx版本最好与之前下载的Yolov5版本相同,因为不同版本之间的网络架构是存在一些差异的,可能会导致后续生成的.engine文件与采用的网络架构不同而出现一系列报错。笔者这里同样是下载的master(默认)。
3.1 生成.wts文件
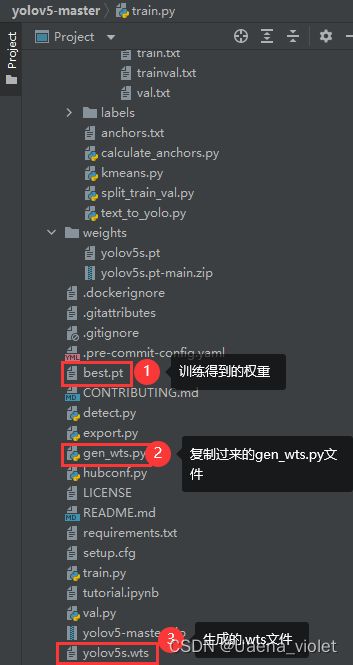
下载完成后,将文件中yolov5子文件中的gen_wts.py文件复制到Yolov5工程目录下,运行该文件生成.wts文件。
具体方法:打开Pycharm的Terminal,输入命令:
python gen_wts.py -w yolov5s.pt -o yolov5s.wts .pt文件就是之前Yolov5网络训练完成生成的文件,根据自己的文件名修改即可。命令后半部分就是生成的.wts文件,同样可以根据自己的需要更改命名。
3.2 生成.engine文件
详细的操作可以参照这位大佬写的文章来进行操作,实战教程:win10环境下用TensorRT推理YOLOv5_脆皮茄条的博客-CSDN博客_tensorrt yolov5
这位大佬写的十分详细,包括从环境配置到工程编译的全过程。如果需要针对自己的数据集进行更改,需要在VS中打开yololayer.h文件,对分类种类数目进行更改。笔者仅仅是对种类数量进行了更改,可以根据需要修改输入图像的尺寸等其他参数。
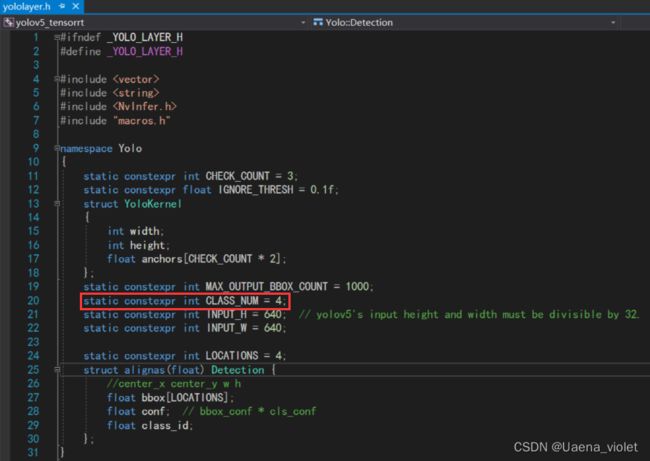
修改完成后,利用Win+R运行cmd,将当前目录切换到该工程目录下,同时将之前生成的.wts文件复制到该文件夹下。输入命令:
yolov5_tensorrt.exe -s yolov5s.wts yolov5s.engine s
生成.engine文件,利用该.engine文件输入命令进行模型预测:
yolov5_tensorrt.exe -d yolov5s.engine ./image_dir
进行预测得到的结果,由于是自己的项目训练集,不方便展示效果图。

四、对模型进行封装
在Qt中调用经过TensorRT推理加速后的模型,需要对模型进行封装,即封装成动态链接库(.dll)的形式在Qt中进行调用。我这里是将yolov5模型封装成了一个类,并且其中包含了两个成员函数,一个是初始化函数inital(),另外一个是推理检测函数detect()。在VS中创建与调用动态链接库的方法可以参考以下几篇博客:
VS2017创建动态链接库与调用_北斗星辰001的博客-CSDN博客_vs2017创建动态链接库
抽象类作为接口使用的DLL实现方法_Christo3的博客-CSDN博客
私有类封装为DLL的方法_Christo3的博客-CSDN博客
这是我自己封装模型时的头文件和源文件,可以根据自己的情况去任意修改。
头文件YoloV5.h:
// 任何项目上不应定义此符号。这样,源文件中包含此文件的任何其他项目都会将
// YOLOV5_API 函数视为是从 DLL 导入的,而此 DLL 则将用此宏定义的
// 符号视为是被导出的。
#ifdef YOLOV5_EXPORTS
#define YOLOV5_API __declspec(dllexport)
#else
#define YOLOV5_API __declspec(dllimport)
#endif
#pragma once
#define USE_FP16 // set USE_INT8 or USE_FP16 or USE_FP32
#define DEVICE 0 // GPU id
#define NMS_THRESH 0.4
#define CONF_THRESH 0.5
#define BATCH_SIZE 1
#define NET s // s m l x
#define NETSTRUCT(str) createEngine_##str
#define CREATENET(net) NETSTRUCT(net)
#define STR1(x) #x
#define STR2(x) STR1(x)
#include
#include
#include "cuda_runtime_api.h"
#include "logging.h"
#include "common.hpp"
#include "utils.h"
#include "calibrator.h"
#include "cuda_utils.h"
using namespace std;
using namespace cv;
#define USE_FP16 // set USE_INT8 or USE_FP16 or USE_FP32
#define DEVICE 0 // GPU id
#define NMS_THRESH 0.4
#define CONF_THRESH 0.5
#define BATCH_SIZE 1
#define NET s // s m l x
#define NETSTRUCT(str) createEngine_##str
#define CREATENET(net) NETSTRUCT(net)
#define STR1(x) #x
#define STR2(x) STR1(x)
YOLOV5_API class YoloV5
{
public:
YOLOV5_API YoloV5();
YOLOV5_API ~YoloV5();
YOLOV5_API bool inital(const string& enginePath);
YOLOV5_API void detect(const Mat& inputImg, vector& vRect);
private:
char* trtModelStream;
size_t size;
Logger gLogger;
int INPUT_H;
int INPUT_W;
int CLASS_NUM;
int OUTPUT_SIZE;
const char* INPUT_BLOB_NAME;
const char* OUTPUT_BLOB_NAME;
void* buffers[2];
float* data;
float* prob;
IExecutionContext* context;
cudaStream_t stream;
private:
YOLOV5_API void doInference(IExecutionContext& context, cudaStream_t& stream, void **buffers, float* input, float* output, int batchSize);
cv::Rect get_rect(cv::Mat& img, float bbox[4]);
float iou(float lbox[4], float rbox[4]);
//bool cmp(const Yolo::Detection& a, const Yolo::Detection& b);
void nms(std::vector& res, float *output, float conf_thresh, float nms_thresh = 0.5);
};
inline bool cmp_1(const Yolo::Detection& a, const Yolo::Detection& b) {
return a.conf > b.conf;
}
extern YOLOV5_API int nYoloV5;
YOLOV5_API int fnYoloV5(void); 源文件YoloV5.cpp:
// YoloV5.cpp : 定义 DLL 的导出函数。
//
#include "YoloV5.h"
YOLOV5_API YoloV5::YoloV5()
{
}
YOLOV5_API YoloV5::~YoloV5()
{
}
YOLOV5_API bool YoloV5::inital(const string& enginePath)
{
INPUT_H = Yolo::INPUT_H;
INPUT_W = Yolo::INPUT_W;
CLASS_NUM = Yolo::CLASS_NUM;
OUTPUT_SIZE = Yolo::MAX_OUTPUT_BBOX_COUNT * sizeof(Yolo::Detection) / sizeof(float) + 1;
INPUT_BLOB_NAME = "data";
OUTPUT_BLOB_NAME = "prob";
data = new float[BATCH_SIZE * 3 * INPUT_H * INPUT_W];
prob = new float[BATCH_SIZE * OUTPUT_SIZE];
std::ifstream file(enginePath, std::ios::binary);
if (file.good()) {
file.seekg(0, file.end);
size = file.tellg();
file.seekg(0, file.beg);
trtModelStream = new char[size];
assert(trtModelStream);
file.read(trtModelStream, size);
file.close();
}
IRuntime* runtime = createInferRuntime(gLogger);
assert(runtime != nullptr);
ICudaEngine* engine = runtime->deserializeCudaEngine(trtModelStream, size);
assert(engine != nullptr);
context = engine->createExecutionContext();
assert(context != nullptr);
delete[] trtModelStream;
assert(engine->getNbBindings() == 2);
// In order to bind the buffers, we need to know the names of the input and output tensors.
// Note that indices are guaranteed to be less than IEngine::getNbBindings()
const int inputIndex = engine->getBindingIndex(INPUT_BLOB_NAME);
const int outputIndex = engine->getBindingIndex(OUTPUT_BLOB_NAME);
assert(inputIndex == 0);
assert(outputIndex == 1);
// Create GPU buffers on device
CUDA_CHECK(cudaMalloc(&buffers[inputIndex], BATCH_SIZE * 3 * INPUT_H * INPUT_W * sizeof(float)));
CUDA_CHECK(cudaMalloc(&buffers[outputIndex], BATCH_SIZE * OUTPUT_SIZE * sizeof(float)));
// Create stream
CUDA_CHECK(cudaStreamCreate(&stream));
return true;
}
YOLOV5_API void YoloV5::detect(const Mat& inputImg, vector& vRect)
{
Mat imgCopy;
inputImg.copyTo(imgCopy);
cv::Mat pr_img = preprocess_img(imgCopy, INPUT_W, INPUT_H); // letterbox BGR to RGB
int i = 0;
int b = 0;
for (int row = 0; row < INPUT_H; ++row) {
uchar* uc_pixel = pr_img.data + row * pr_img.step;
for (int col = 0; col < INPUT_W; ++col) {
data[b * 3 * INPUT_H * INPUT_W + i] = (float)uc_pixel[2] / 255.0;
data[b * 3 * INPUT_H * INPUT_W + i + INPUT_H * INPUT_W] = (float)uc_pixel[1] / 255.0;
data[b * 3 * INPUT_H * INPUT_W + i + 2 * INPUT_H * INPUT_W] = (float)uc_pixel[0] / 255.0;
uc_pixel += 3;
++i;
}
}
// Run inference
auto start = std::chrono::system_clock::now();
YoloV5::doInference(*context, stream, buffers, data, prob, BATCH_SIZE);
auto end = std::chrono::system_clock::now();
std::cout << std::chrono::duration_cast(end - start).count() << "ms" << std::endl;
int fcount = 1;
std::vector> batch_res(fcount);
for (int b = 0; b < fcount; b++) {
auto& res = batch_res[b];
nms(res, &prob[b * OUTPUT_SIZE], CONF_THRESH, NMS_THRESH);
}
for (int b = 0; b < fcount; b++) {
auto& res = batch_res[b];
//std::cout << res.size() << std::endl;
Mat img;
inputImg.copyTo(img);
if (inputImg.channels() == 1)
{
cv::cvtColor(img, img, cv::COLOR_GRAY2BGR);
}
for (size_t j = 0; j < res.size(); j++) {
cv::Rect r = get_rect(img, res[j].bbox);
if (res[j].class_id == 0)
{
vRect.push_back(r);
}
cv::rectangle(img, r, cv::Scalar(0, 0, 255), 2);
if ((int)res[j].class_id == 0)
{
cv::putText(img, "First", cv::Point(r.x - 50, r.y - 1), cv::FONT_HERSHEY_PLAIN, 1.2, cv::Scalar(0, 0, 255), 2);
cv::putText(img, std::to_string((float)res[j].conf), cv::Point(r.x + 50, r.y - 1), cv::FONT_HERSHEY_PLAIN, 1.2, cv::Scalar(0, 0, 255), 2);
}
if ((int)res[j].class_id == 1)
{
cv::putText(img, "Second", cv::Point(r.x - 50, r.y - 1), cv::FONT_HERSHEY_PLAIN, 1.2, cv::Scalar(0, 0, 255), 2);
cv::putText(img, std::to_string((float)res[j].conf), cv::Point(r.x + 50, r.y - 1), cv::FONT_HERSHEY_PLAIN, 1.2, cv::Scalar(0, 0, 255), 2);
}
if ((int)res[j].class_id == 2)
{
cv::putText(img, "Third", cv::Point(r.x - 50, r.y - 1), cv::FONT_HERSHEY_PLAIN, 1.2, cv::Scalar(0, 0, 255), 2);
cv::putText(img, std::to_string((float)res[j].conf), cv::Point(r.x + 50, r.y - 1), cv::FONT_HERSHEY_PLAIN, 1.2, cv::Scalar(0, 0, 255), 2);
}
if ((int)res[j].class_id == 3)
{
cv::putText(img, "Fourth", cv::Point(r.x - 50, r.y - 1), cv::FONT_HERSHEY_PLAIN, 1.2, cv::Scalar(0, 0, 255), 2);
cv::putText(img, std::to_string((float)res[j].conf), cv::Point(r.x + 50, r.y - 1), cv::FONT_HERSHEY_PLAIN, 1.2, cv::Scalar(0, 0, 255), 2);
}
}
//img.copyTo(outputImg);
cv::imwrite("E:\\res.jpg", img);
}
}
YOLOV5_API void YoloV5::doInference(IExecutionContext& context, cudaStream_t& stream, void **buffers, float* input, float* output, int batchSize) {
// DMA input batch data to device, infer on the batch asynchronously, and DMA output back to host
CUDA_CHECK(cudaMemcpyAsync(buffers[0], input, batchSize * 3 * INPUT_H * INPUT_W * sizeof(float), cudaMemcpyHostToDevice, stream));
context.enqueue(batchSize, buffers, stream, nullptr);
CUDA_CHECK(cudaMemcpyAsync(output, buffers[1], batchSize * OUTPUT_SIZE * sizeof(float), cudaMemcpyDeviceToHost, stream));
cudaStreamSynchronize(stream);
}
cv::Rect YoloV5::get_rect(cv::Mat& img, float bbox[4]) {
int l, r, t, b;
float r_w = Yolo::INPUT_W / (img.cols * 1.0);
float r_h = Yolo::INPUT_H / (img.rows * 1.0);
if (r_h > r_w) {
l = bbox[0] - bbox[2] / 2.f;
r = bbox[0] + bbox[2] / 2.f;
t = bbox[1] - bbox[3] / 2.f - (Yolo::INPUT_H - r_w * img.rows) / 2;
b = bbox[1] + bbox[3] / 2.f - (Yolo::INPUT_H - r_w * img.rows) / 2;
l = l / r_w;
r = r / r_w;
t = t / r_w;
b = b / r_w;
}
else {
l = bbox[0] - bbox[2] / 2.f - (Yolo::INPUT_W - r_h * img.cols) / 2;
r = bbox[0] + bbox[2] / 2.f - (Yolo::INPUT_W - r_h * img.cols) / 2;
t = bbox[1] - bbox[3] / 2.f;
b = bbox[1] + bbox[3] / 2.f;
l = l / r_h;
r = r / r_h;
t = t / r_h;
b = b / r_h;
}
return cv::Rect(l, t, r - l, b - t);
}
float YoloV5::iou(float lbox[4], float rbox[4]) {
float interBox[] = {
(std::max)(lbox[0] - lbox[2] / 2.f , rbox[0] - rbox[2] / 2.f), //left
(std::min)(lbox[0] + lbox[2] / 2.f , rbox[0] + rbox[2] / 2.f), //right
(std::max)(lbox[1] - lbox[3] / 2.f , rbox[1] - rbox[3] / 2.f), //top
(std::min)(lbox[1] + lbox[3] / 2.f , rbox[1] + rbox[3] / 2.f), //bottom
};
if (interBox[2] > interBox[3] || interBox[0] > interBox[1])
return 0.0f;
float interBoxS = (interBox[1] - interBox[0])*(interBox[3] - interBox[2]);
return interBoxS / (lbox[2] * lbox[3] + rbox[2] * rbox[3] - interBoxS);
}
void YoloV5::nms(std::vector& res, float *output, float conf_thresh, float nms_thresh) {
int det_size = sizeof(Yolo::Detection) / sizeof(float);
std::map> m;
for (int i = 0; i < output[0] && i < Yolo::MAX_OUTPUT_BBOX_COUNT; i++) {
if (output[1 + det_size * i + 4] <= conf_thresh) continue;
Yolo::Detection det;
memcpy(&det, &output[1 + det_size * i], det_size * sizeof(float));
if (m.count(det.class_id) == 0) m.emplace(det.class_id, std::vector());
m[det.class_id].push_back(det);
}
for (auto it = m.begin(); it != m.end(); it++) {
//std::cout << it->second[0].class_id << " --- " << std::endl;
auto& dets = it->second;
std::sort(dets.begin(), dets.end(), cmp);
for (size_t m = 0; m < dets.size(); ++m) {
auto& item = dets[m];
res.push_back(item);
for (size_t n = m + 1; n < dets.size(); ++n) {
if (iou(item.bbox, dets[n].bbox) > nms_thresh) {
dets.erase(dets.begin() + n);
--n;
}
}
}
}
}
资源管理器:
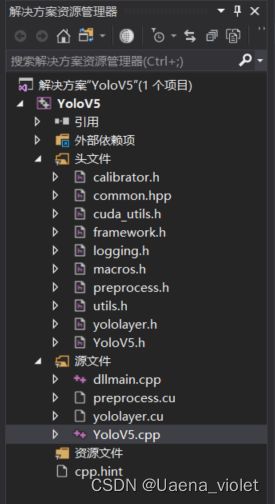
该项目同样需要引入yolov5文件夹中的头文件和.cu文件。配置好相应的环境(与3.2节中在VS中生成.engine文件的环境配置相同),编写好封装的函数后(YoloV5.h和YoloV5.cpp),在Release环境下开始进行编译运行,会生成yolov5.dll的动态链接库文件以及对应的lib文件。
完成之后,可以先在VS中进行检测封装好的模型是否能够运行。创建一个test项目,创建一个新的源文件Test.cpp,并且将yololayer.cu添加进项目中,同样需要跟之前一样配置相应的环境才能够正常运行。
源文件Test.cpp:
// Test.cpp : 定义控制台应用程序的入口点。
//
#pragma warning(disable:4996)
#include
#include "..//Yolov5/YoloV5.h"
#include "..//Yolov5/dirent.h"
int main()
{
YoloV5 yolov5_1;
string enginePath = "E:\\PyTorch\\TensorRT\\C_VS\\yolov5_tensorrt\\x64\\Release\\yolov5s.engine";
yolov5_1.inital(enginePath);
vector vImgPath;
string filter = "E:\\PyTorch\\淘汰的网络\\make_dataset_Faster_RCNN\\photo\\12.jpg";
glob(filter, vImgPath);
for (auto i = 0; i < vImgPath.size(); i++)
{
//cout << "vImgPath.size() : " << vImgPath.size() << endl;
Mat img = imread(vImgPath[i]);
if (img.channels() == 1)
{
cvtColor(img, img, cv::COLOR_GRAY2BGR);
}
vector res1;
yolov5_1.detect(img, ref(res1));
}
return 0;
}
运行Test.cpp文件,可以看到生成的检测图像。正确生成检测图像之后,就可以开始利用Qt进行模型的部署了。
五、利用Qt进行部署
5.1 Qt的安装
笔者个人建议可以在VS中进行Qt代码的编写以及界面的设计,个人认为相较于在Qt Creator中进行代码编写在VS中更有利于代码的调试。首先需要进行Qt的安装,安装教程可以参考这位老师写的博客:Qt 入门 | 爱编程的大丙 (subingwen.cn)里面的第二章详细描述了Qt的安装。
5.2 Qt与VS2017相关联
由于在VS中进行程序调试更方便一些,因此需要将安装好的Qt与VS进行关联,从而可以在VS中进行Qt代码的编写。Qt与VS相关联的方法可以参考这篇博客:Qt5.11.1安装与VS2017配置_GJXAIOU的博客-CSDN博客_qt vs2017
5.3 进行模型的部署
5.3.1 在VS中创建新的Qt项目
在VS中进行Qt的编写,从而进行模型的部署。先创建一个新项目,选择Qt Widgets Application,点击确定→Next→勾选对应的Qt版本以及开发系统和平台,Next→根据自己的情况命名,Finish→项目→重新生成解决方案。
当看到生成成功时,即代表Qt和VS的关联成功。
5.3.2 进行环境的配置
右键项目,选择属性,进入项目页点击VC++目录,选择包含目录,将TensorRT、CUDA以及Qt的include文件夹路径添加到包含目录中。添加完成后再选择库目录,同样将TensorRT、CUDA以及Qt的lib文件夹路径添加进库目录中。
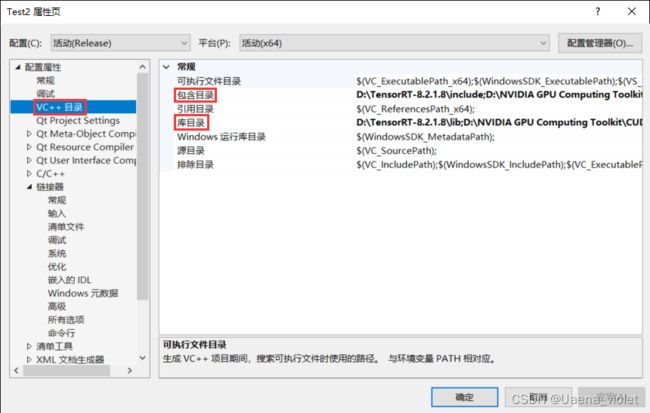
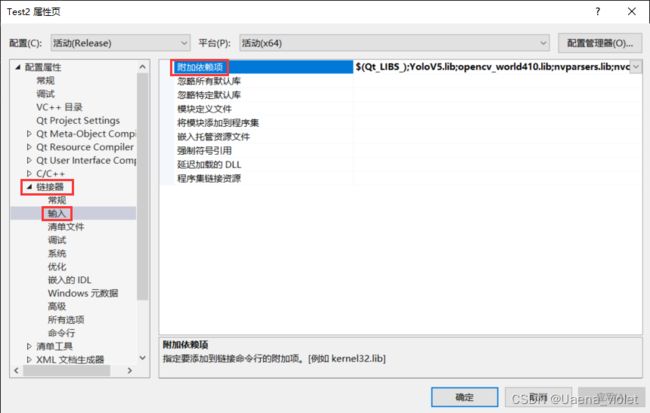
添加完成后点击应用,在选择链接器→输入→附加依赖项,添加上相应的.lib文件,这是笔者添加的文件:
$(Qt_LIBS_)
YoloV5.lib
opencv_world410.lib
nvparsers.lib
nvonnxparser.lib
nvinfer_plugin.lib
nvinfer.lib
cublas.lib
cublasLt.lib
cuda.lib
cudadevrt.lib
cudart.lib
cudart_static.lib
cudnn.lib
cudnn64_8.lib
cudnn_adv_infer.lib
cudnn_adv_infer64_8.lib
cudnn_adv_train.lib
cudnn_adv_train64_8.lib
cudnn_cnn_infer.lib
cudnn_cnn_infer64_8.lib
cudnn_cnn_train.lib
cudnn_cnn_train64_8.lib
cudnn_ops_infer.lib
cudnn_ops_infer64_8.lib
cudnn_ops_train.lib
cudnn_ops_train64_8.lib
cufft.lib
cufftw.lib
curand.lib
cusolver.lib
cusolverMg.lib
cusparse.lib
nppc.lib
nppial.lib
nppicc.lib
nppidei.lib
nppif.lib
nppig.lib
nppim.lib
nppist.lib
nppisu.lib
nppitc.lib
npps.lib
nvblas.lib
nvjpeg.lib
nvml.lib
nvrtc.lib
OpenCL.lib
kernel32.lib
user32.lib
gdi32.lib
winspool.lib
comdlg32.lib
advapi32.lib
shell32.lib
ole32.lib
oleaut32.lib
uuid.lib
odbc32.lib
odbccp32.lib添加完成后,同样点击应用,完成环境配置。
环境配置好之后,需要将之前封装好的.dll文件与.lib文件复制到当前项目文件夹中。
5.3.3 添加.cu文件
在源文件中添加上之前的yololayer.cu文件,

添加完成后, 右键项目,选择生成依赖项,点击生成自定义,勾选CUDA。
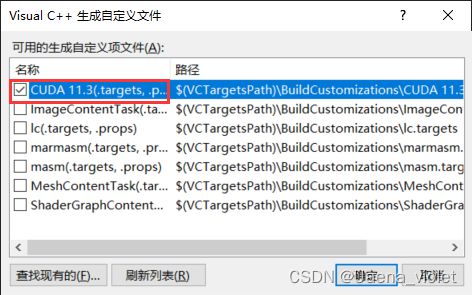
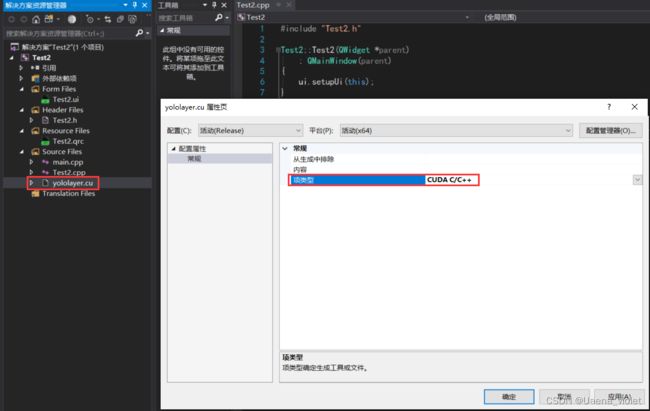
完成后,右键yololayer.cu文件,选择属性,在项类型中选择CUDA C/C++,点击应用,完成.cu文件的生成配置。
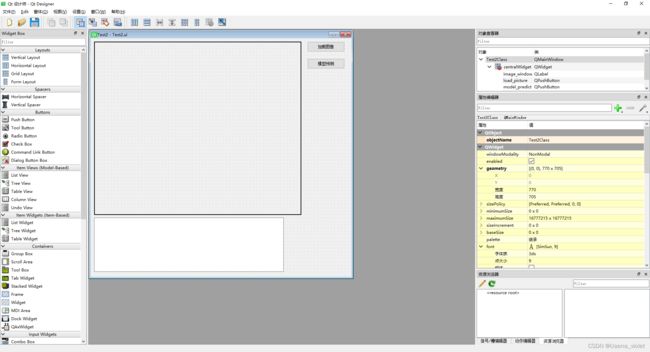
5.3.4编写Qt代码
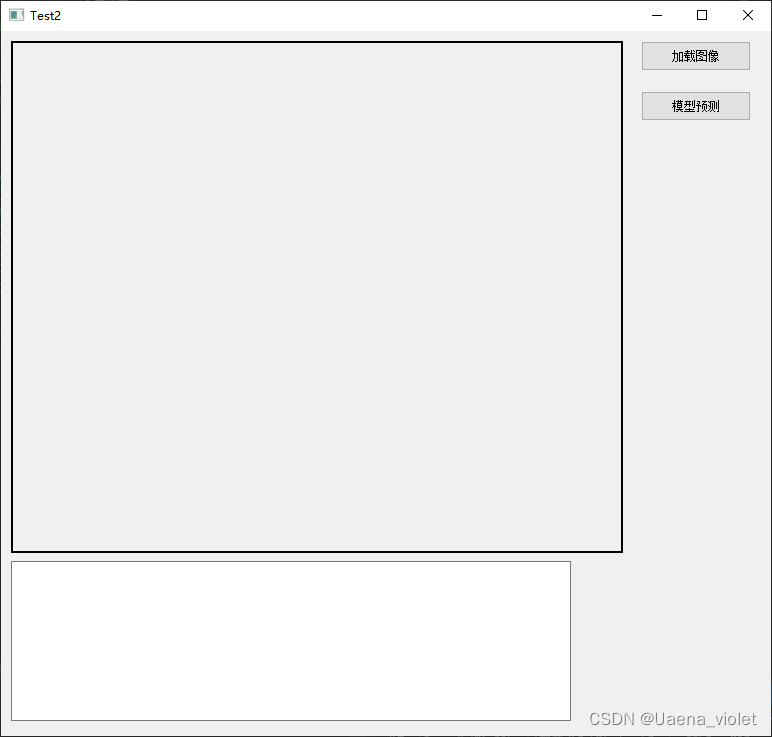
完成相关的环境配置之后,就可以开始进行Qt代码的编写。 首先可以先进入.ui文件中,进行相应控件添加,设计自己的UI界面。
设计完ui界面之后,进行相应代码的编写,分别给每个空间添加上相应的功能。
Test2.h头文件:
#pragma once
#ifndef TEST2_H
#define TEST2_H
#include
#include "ui_Test2.h"
#if _MSC_VER >= 1600
#pragma execution_character_set("utf-8")
#endif
#include "opencv2/opencv.hpp"
#include "opencv.hpp"
using namespace std;
QT_BEGIN_NAMESPACE
namespace Ui { class MainWindow; }
QT_END_NAMESPACE
class Test2 : public QMainWindow
{
Q_OBJECT
public:
Test2(QWidget *parent = nullptr);
~Test2();
// 声明全局变量
// 存放原图像
static cv::Mat image;
private:
Ui::Test2Class *ui;
private slots:
// 载入图像
void on_load_picture_clicked();
// 模型预测
void on_model_predict_clicked();
};
#endif Test2.cpp源文件:
#include "Test2.h"
#include "qfile.h"
#include "E://PyTorch//TensorRT/C_VS/yolov5_dll/YoloV5/YoloV5/YoloV5.h" // 封装模型的头文件路径
#include "E://PyTorch//TensorRT/C_VS/yolov5_dll/YoloV5/YoloV5/dirent.h" // dirent.h的路径
// 定义全局变量
// 存放原图像
Mat Test2::image;
// 构造函数
Test2::Test2(QWidget *parent)
: QMainWindow(parent)
{
ui->setupUi(this);
}
// 析构函数
Test2::~Test2()
{}
// 加载图像
void Test2::on_load_picture_clicked()
{
// 利用Qt的方式去读入图像
QFile file("E:/1.jpg");
//判断当前路径是否存在 一定要添加上if else 判断QFile文件是否读取成功
if (!file.open(QFile::ReadOnly))
{
// 路径不存在 则提示读取失败
ui->textEdit->append(QString("图像载入失败..."));
}
else
{
QByteArray ba = file.readAll();
// 再使用imdecode函数将比特流解码成Mat类
image = imdecode(std::vector(ba.begin(), ba.end()), 1);
ui->textEdit->append(QString("图像载入成功..."));
}
cv::Mat temp;
QImage qImg;
// 将图像的三通道格式从BGR改成RGB
cv::cvtColor(image, temp, COLOR_BGR2RGB);
// 进行图像的缩放
cv::resize(temp, temp, Size(612, 512));
// 将Mat类转换成QImage
QImage Qimg = QImage((const unsigned char*)(temp.data), temp.cols, temp.rows, temp.step, QImage::Format_BGR888);
// 在Label窗口进行显示
// 先清空之前的图像,再显示
ui->image_window->clear();
ui->image_window->setPixmap(QPixmap::fromImage(Qimg));
ui->image_window->resize(Qimg.size());
ui->image_window->show();
}
// 模型检测
void Test2::on_model_predict_clicked()
{
// 输出提示信息
ui->textEdit->append(QString("正在进行模型预测,请耐心等待..."));
// 建立YoloV5模型
YoloV5 yolov5_1;
// 读入.engine模型
string enginePath = "E:\\PyTorch\\TensorRT\\C_VS\\yolov5_tensorrt\\x64\\Release\\yolov5s.engine";
// 模型初始化
yolov5_1.inital(enginePath);
cv::Mat img = image;
// 判断图像是否是单通道图像
if (img.channels() == 1)
{
// 将单通道图像转变为三通道图像
cvtColor(img, img, cv::COLOR_GRAY2BGR);
}
// 存放预测框坐标
vector res1;
// 进行预测
yolov5_1.detect(img, ref(res1));
// 利用Qt的方式去读取图像
QFile file("E:/res.jpg");
// 判断预测结果是否存在 一定要添加上if else 判断QFile文件是否读取成功
if (!file.open(QFile::ReadOnly))
{
// 路径不存在 输出模型预测失败
ui->textEdit->append(QString("模型预测失败..."));
}
else
{
// 输出成功信息
ui->textEdit->append(QString("模型预测成功..."));
// 路径存在 读入图像
QByteArray ba = file.readAll();
// 再使用imdecode函数将比特流解码成mat类
cv::Mat image = imdecode(std::vector(ba.begin(), ba.end()), 1);
cv::Mat temp;
// 将图像的三通道格式从bgr改成rgb
//cv::cvtcolor(image, temp, color_bgr2rgb);
// 进行图像的缩放
cv::resize(image, temp, Size(612, 512));
// 将mat类转换成qimage
QImage Qimg = QImage((const unsigned char*)(temp.data), temp.cols, temp.rows, temp.step, QImage::Format_BGR888);
// 在label窗口进行显示
// 先清空之前的图像,在进行显示
ui->image_window->clear();
ui->image_window->setPixmap(QPixmap::fromImage(Qimg));
ui->image_window->resize(Qimg.size());
ui->image_window->show();
}
}
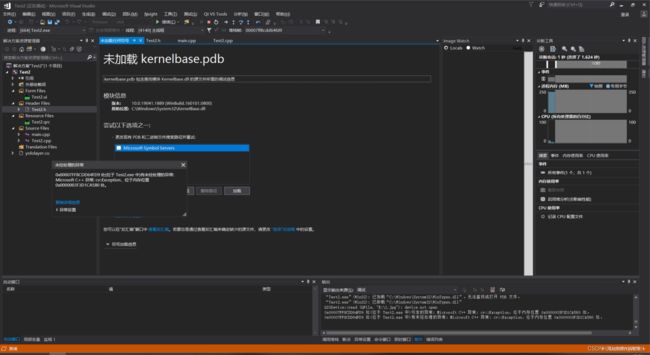
注意!笔者的代码中采用了QFile去进行文件的读取,后面一定要对QFile文件是否读取成功进行判断,即添加上if else的条件判断语句,否则程序在调试时会出现下图的报错情况,并且运行不调试时ui界面会出现闪退的情况。
编写完成后,就可以在Release环境下运行代码了。点击加载图像和模型预测就可以在显示框中显示出图像内容。(这里由于笔者的个人原因,不方便对模型预测后的图像进行展示。)
笔者是对自己项目经历过程中所用到的技术进行了一个粗略的归纳,其中引用了许多位大佬的博客,仅供各位参考,希望能对有需要的人提供一些帮助。文中可能存在笔者有所疏漏或没有说明到的地方,望海涵。欢迎各位在评论区提出问题和建议。