Kaggle-泰坦尼克号项目 | 小白修炼之路的开始
前言
作为一名萌生转行想法大概2个月的小白,第一个月艰难的学习了execl,python,mysql的基础用法,第二个月开始尝试在不断学习的过程中,增加一些实践的部分,所以这篇文章就诞生了!所以也就是说这篇文章菲比个人开启自己转行之路的里程碑式文章,哈哈哈!
选择泰坦尼克号项目的原因有二,一则是泰坦尼克号是kaggle非常经典的一个项目,相信很多人都是从这个项目开始自己机器学习or数据分析的旅途的,二则是这个项目比较‘接地气’,毕竟卡梅隆的电影大家都看过,对于业务的理解不会那么晦涩难懂
因为此文章是处女作,第一目标是完成,最终完成之后的准确率为0.77751,排名在3000-4000之间(很菜,所以想要冲准确率的朋友们请忽略此篇菜鸟文)
数据读取
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.svm import SVC
import seaborn as sns在做好了上述设置之后,先来看一看泰坦尼克号这个项目给我们的数据文件:共3个文件,分别为train.csv(训练集),test.csv(测试集),gender_submission.csv(输入结果集)
/kaggle/input/titanic/train.csv
/kaggle/input/titanic/test.csv
/kaggle/input/titanic/gender_submission.csv
训练集:用于数据分析+特征工程+模型构建等一系列操作,目标是通过训练集训练出一个模型,用于泰坦尼克项目的生存结果预测
测试集:用于测试通过训练集训练的模型的准确率
在数据分析、模型构建阶段我们需要的对训练集进行操作,同时虽然测试集仅用于测试,但是因为他要套用训练集训练的模型,故在数据预处理,特征工程这两个阶段需要两个数据集做统一的操作
基于以上分析
1、使用pd.read_csv()先将训练集和测试集分别进行读取
2、分别在data_train,data_test 中加一列 'is train' ,用于区分
3、使用pd.concat()将训练集和测试集拼接在一起用于后续的统一操作
data_real_train = pd.read_csv('/kaggle/input/titanic/train.csv') data_real_test = pd.read_csv('/kaggle/input/titanic/test.csv') data_real_train['is_train'] = 1 data_real_test['is_train'] = 0 datas = pd.concat([data_real_train, data_real_test], ignore_index = True) datas.head()

初步数据分析
初步看一下数据,数据是否空缺值?数据有哪些类型?数据有哪些明显特征?数据之间简单的关系是怎么样的?
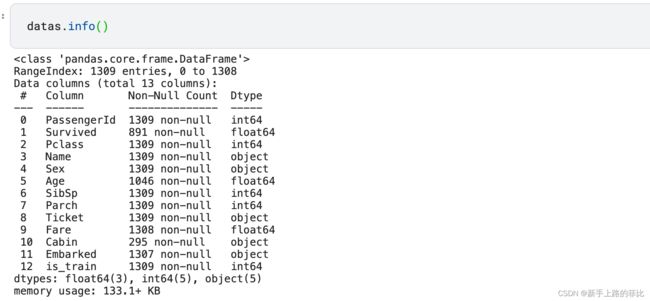
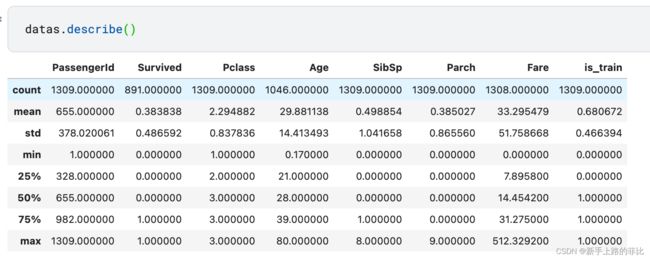
1、使用datas.info() 和 datas.describe() 先简单看下数据
- 训练集+测试集一共1309条数据,存活率38.38%
- 存在空缺值:'Pclass' 'Age' 'Cabin' 'Embarked' 'Fare'
- 3种数据类型:int,float,object
2、使用sns.pairplot() 快速画出两两特征(好多图,先简单看看吧,不做深入分析)
通过自己和自己的图,判断下数据类型:
- 与业务无关数据:'passengerid' 'is_train'(通过常识得出,在图中看也没有什么信息)
- 连续&无固定类型数据:'Age' 'Fare'
- 不连续&无固定的数据:'sibsp' 'parch'
- 固定类型的数据:'survived' 'Pclass'
- 字符串(图里没有,根据业务理解得出):
- 无固定类型数据:'Name' ' Ticket' 'cabin'
- 固定类型数据: 'Sex' 'embarked'

 3、使用 datas.corr() 计算两两数据的相关性,并根据计算的相关性画出热力图,可以直观的看出哪些变量的相关比较高
3、使用 datas.corr() 计算两两数据的相关性,并根据计算的相关性画出热力图,可以直观的看出哪些变量的相关比较高
- 与survived相关性比较高的数据类型(>0.1):'pclass'和‘Fare'
- 除survived外,相关性比较高的数据组合:'pcalss'和‘Age’;'pcalss'和'Fare';'sibsp'和'parch'
datas_corr = data_real_train.corr()
sns.heatmap(datas_corr,annot=True)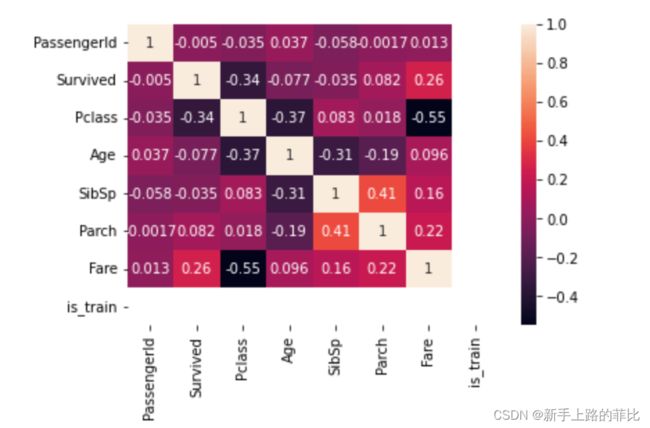
数据预处理(缺失值填充)
存在空缺值的列: 'Age' 'Cabin' 'Embarked' 'Fare'
- 'Age' 空缺263
- 'Cabin' 空缺1014,缺失值很多
- 'Embarked' 空缺2
- 'Fare' 空缺1
这样看来,主要需要处理的是'Age',通过随机森林根据其他特征训练模型进行填充,与Age相关相关性较大的3个特征【Pclass,sibsp,parch】
cabin的数据量太小了此列考虑直接删除,Embarked 和 Fare的空缺值比较小,Embarked用上一条数据来填充,Fare用中位置来填充
#使用ffill填充'Embarked'
datas['Embarked'] = datas['Embarked'].fillna(method='ffill')
#使用中位数填充'Fare'
datas['Fare'] = datas['Fare'].fillna(datas['Fare'].median())
#删除'cabin'这一列
datas = datas.drop('Cabin',axis=1)
#使用随机森林填充'Age'
from sklearn.ensemble import RandomForestRegressor
def set_missing_age(df):
age_df = datas[['Age','Pclass','SibSp','Parch']]
#乘客分成已知年龄和未知年龄两个部分
known_age = age_df[age_df['Age'].notnull()].values
unknown_age = age_df[age_df['Age'].isnull()].values
# 目标数据y,取第一列‘age'
y = known_age[:,0]
# 特征属性数据x,取非‘age'的列
x = known_age[:,1:]
# 利用随机森林进行拟合
rfr = RandomForestRegressor(random_state=0,n_estimators=2000,n_jobs=-1)
rfr.fit(x,y)
# 利用训练的模型进行预测
predictedAges = rfr.predict(unknown_age[:,1::])
# 填补缺失的原始数据
df.loc[(datas['Age'].isnull()),'Age'] = predictedAges
return df
datas = set_missing_age(datas)最后检查一下是否成功完成填充

数据分析+特征工程
结合上文了解到的数据信息,进一步进行数据分析,目标通过数据分析完成对原数据的特这个特征工程工作
初步列出几个需要解决的问题:
- 'Sex'特征:字符串数据(famale,male),只有2个类别的特征没必要one hot的必要,将他们用两个数字(0,1)
- 'Passengerid' 特征:这一列因考虑到没有信息,可以直接删除掉
- 'SibSp'和'Parch'两个特征:相加得出'Family'(这么做的依据是通过corr发现这两个特征相关性很高,且结合实际情况判断这两个)
- ‘Age’特征:连续数据,通过画图看一下不同区间生存情况,将连续数据进行分桶,后续进行one hot
- 'Fare'特征:与Pclass的相关性较高,需要思考是否要做处理?先通过画图看一下票价与生存率情况,再思考是否与Pcalss合并
- 'Name'特征:Name需要做两个处理,计算名字长度+取名字中间代表身份的单词取出来
- Ticket看下是否要做处理
- 将适合one hot的特征 get dummy
1、'Sex'特征:字符串数据(famale,male),2个特征考虑到没必要one hot的必要,将他们用两个数字(0,1)
datas['Sex'] = datas['Sex'].apply (lambda x:1 if x =='male' else 0)
2、'Passengerid' 特征:这一列因考虑到没有信息,可以直接删除掉
datas = datas.drop('PassengerId',axis = 1 )3、'SibSp'和'Parch'两个特征:相加得出'Family'(这么做的依据是通过corr发现这两个特征相关性很高,且结合实际情况判断这两个)
datas['Family'] = datas['SibSp'] + datas['Parch']4、‘Age’特征:连续数据,通过画图看一下不同区间生存情况,将连续数据进行分桶,后续进行one hot
sns.displot(data=datas,x='Age',hue='Survived')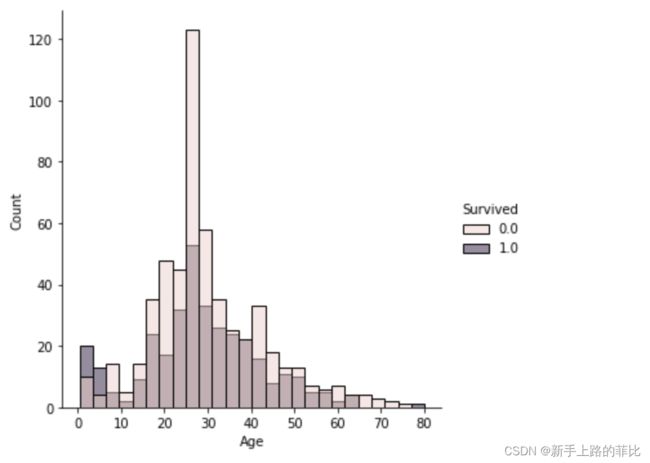
通过分布区间,判断用国际标准进行分桶比较合理
- 0-17岁 少年
- 17-44岁 青年
- 45~59岁为中年人
- 60以上 老人
def age_transform(x):
if x <18:
x = '少年'
elif x <45:
x = '青年'
elif x <60:
x = '中年'
else:
x = '老年'
return x
datas['Age'] = datas['Age'].apply(age_transform)5、'Fare'特征:与Pclass的相关性较高,需要思考是否要做处理?先通过画图看一下票价与生存率情况,再思考是否与Pcalss合并
sns.boxplot(data=datas,x='Pclass',y='Fare',hue='Survived')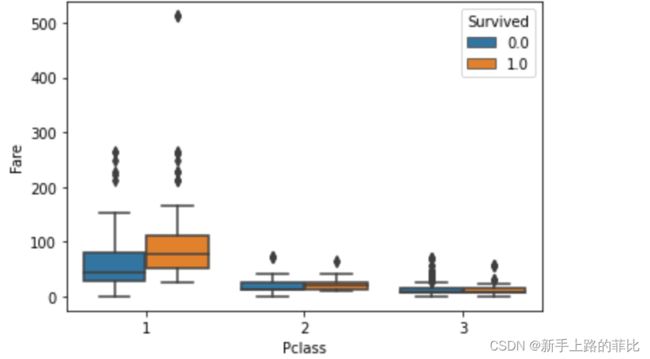
一等舱的存活和死亡的人,在票价上会有一些差异,故基于此,目标将Fare和Pclass合并
sns.displot(data=datas[datas['Pclass']==1],x='Fare',hue='Survived',palette='Set3')
#将Fare和Pcalss结合组成一个特征,之后进行one hot
- 一等舱
- 一等舱白嫖票
- 一等舱打折票
- 一等舱普通票
- 一等舱高价票
- 一等舱离谱高阶票
- 二等舱
- 三等舱
def some_func_deal_with_a_row(row):
if row['Pclass'] == 2:
return '二等舱'
elif row['Pclass'] == 3:
return '三等舱'
elif row['Pclass'] == 1:
if row['Fare']<=40:
return '一等舱白嫖票'
elif 406、'Name'特征:Name先简单做两个动作:计算长度和把名字中间的单词取出来
#做一下处理计算名字长度
datas['Name_Length'] = datas['Name'].apply(lambda x : len(x))
#将中间代表身份的单词取出来
datas['Name_Middle'] = datas['Name'].apply(lambda x: x[x.index(',')+1:x.index('.')])然后看一下名字中间的单词如何进行分组,后续进行one hot
pd.pivot_table(datas,index='Name_Middle',values='Pclass+Fare',aggfunc=len).sort_values('Pclass+Fare',ascending=False)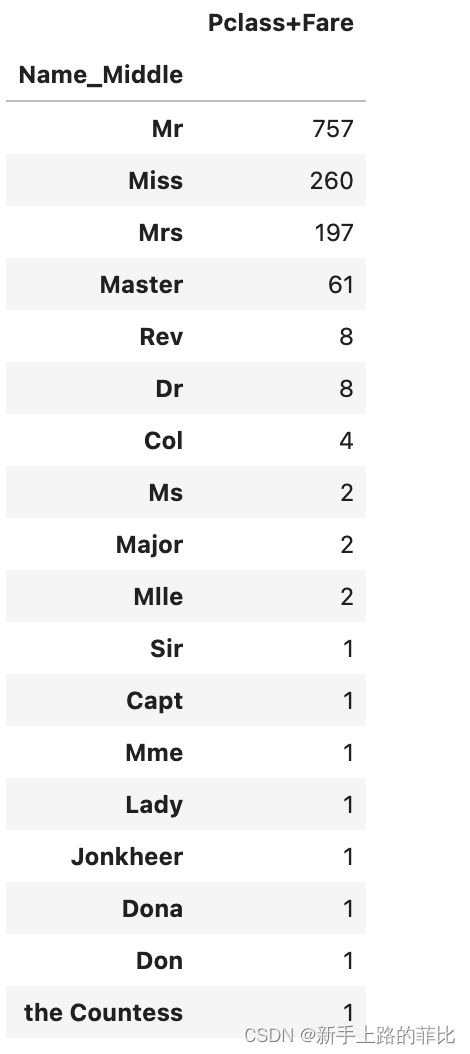
选择保留5个特征,Mr,Miss,Mrs,Master,else
def name_transform(name):
if name == 'Mr':
return 'Mr'
elif name == 'Miss':
return 'Miss'
elif name == 'Mrs':
return 'Mrs'
elif name == 'Master':
return 'Master'
else:
return 'else'
datas['Name_Middle'] = datas['Name_Middle'].apply(name_transform)7、Ticket简单做下处理,将他们纯数字类型的票和非数字类型的票做一下区分,虽然通过数据透视表在生存率上的表现没有很大的差异
datas['kind_of_ticket'] = datas['Ticket'].apply(lambda x: 1 if x.isdigit() else 0 )
pd.pivot_table(data=datas[datas['is_train']==1],index='kind_of_ticket',values='Survived',aggfunc=[np.mean,len])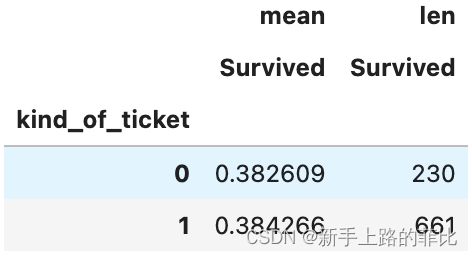
one hot
- 需要dorp掉的特征:'Name','SibSp','Parch','Ticket'
- 保留特征'pclass','Sex','Fare','Family','Name_Length''kind_of_ticket','is_train'
- 需要one-hot的特征:'Age','Embarked','Pclass+Fare''Name_Middle'
datas = datas.drop(['Name','SibSp','Parch','Ticket'],axis=1)
get_dummies_datas = datas[['Age','Embarked','Pclass+Fare','Name_Middle']]
get_dummies_datas.head()
pd.get_dummies(get_dummies_datas)
data2 = datas[['Survived','Pclass','Sex','Fare','Family','Name_Length','kind_of_ticket','is_train']]
all_data = data2.join(pd.get_dummies(get_dummies_datas))
模型构建
导入需要用的模型
(因为还不知道哪些模型好用,哪些模型不好用,所以就把所有的模型导入了,一起操作!)
#导入后续需要用到的库文件
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pylab as plt
#使用sklearn做机器学习
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
from sklearn.tree import DecisionTreeClassifier # 决策树分类器
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier # 随机森林分类器,梯度提升决策树分类器
from sklearn.neighbors import KNeighborsClassifier # KNN分类器
from sklearn.linear_model import LogisticRegression, RidgeClassifier # 逻辑回归、岭回归分类器
from sklearn.svm import SVC # 支持向量机分类器
from sklearn.naive_bayes import GaussianNB # 高斯朴素贝叶斯分类器先需要通过is_train 分离训练集&测试集,同时将训练集再分为训练集和自测集
all_data
data_train = all_data[all_data['is_train']==1]
data_test = all_data[all_data['is_train']==0]
X = data_train.iloc[:,1:]
y = data_train.iloc[:,0]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)初始化模型并简单调参(这里还不太会,照猫画虎写的)
dtc = DecisionTreeClassifier()
dtc2 = DecisionTreeClassifier(max_depth=5, min_samples_split=10, min_samples_leaf=5)
rfc = RandomForestClassifier()
rfc2 = RandomForestClassifier(n_estimators=50, max_depth=10)
gbc = GradientBoostingClassifier()
gbc2= GradientBoostingClassifier(n_estimators=50, max_depth=10, learning_rate=0.05)
knn = KNeighborsClassifier()
knn2 = KNeighborsClassifier(n_neighbors=30, weights="distance")
lg = LogisticRegression()
lg2 = LogisticRegression(C=0.1, penalty="l2")
rc = RidgeClassifier()
rc2 = RidgeClassifier(alpha=0.1)
svc = SVC()
svc2 = SVC(degree=2)
gnb = GaussianNB()接下来开始训练了!其实就是用fit这个函数,但是因为魔性太多,所以写了一大堆
dtc.fit(X_train, y_train)
dtc2.fit(X_train, y_train)
rfc.fit(X_train, y_train)
rfc2.fit(X_train, y_train)
gbc.fit(X_train, y_train)
gbc2.fit(X_train, y_train)
knn.fit(X_train, y_train)
knn2.fit(X_train, y_train)
lg.fit(X_train, y_train)
lg2.fit(X_train, y_train)
rc.fit(X_train, y_train)
rc2.fit(X_train, y_train)
svc.fit(X_train, y_train)
svc2.fit(X_train, y_train)
gnb.fit(X_train, y_train)在具体出结果之前,需要看一下在自测集上的表现,如果超过80那就直接应用到真正的测试集了
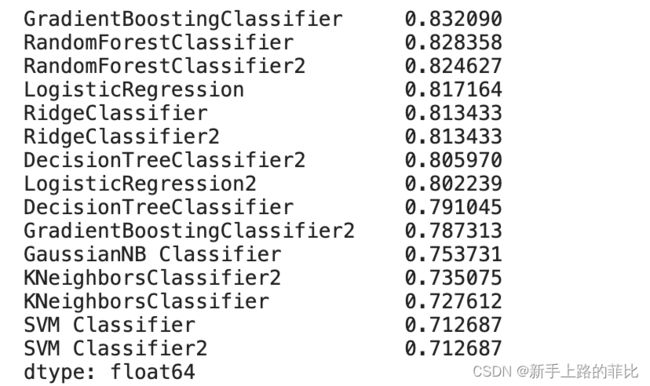
model_scores = {
"DecisionTreeClassifier": dtc.score(X_test, y_test),
"DecisionTreeClassifier2": dtc2.score(X_test, y_test),
"RandomForestClassifier" : rfc.score(X_test, y_test),
"RandomForestClassifier2": rfc2.score(X_test, y_test),
"GradientBoostingClassifier": gbc.score(X_test, y_test),
"GradientBoostingClassifier2": gbc2.score(X_test, y_test),
"KNeighborsClassifier": knn.score(X_test, y_test),
"KNeighborsClassifier2": knn2.score(X_test, y_test),
"LogisticRegression": lg.score(X_test, y_test),
"LogisticRegression2": lg2.score(X_test, y_test),
"RidgeClassifier": rc.score(X_test, y_test),
"RidgeClassifier2": rc2.score(X_test, y_test),
"SVM Classifier": svc.score(X_test, y_test),
"SVM Classifier2": svc2.score(X_test, y_test),
"GaussianNB Classifier": gnb.score(X_test, y_test)
}
pd.Series(model_scores).sort_values(ascending=False)准确率最高的为83.2%,梯度提升决策树模型
将模型用于预测,并将答案以CSV的格式储存
from sklearn.ensemble import VotingClassifier
vc = VotingClassifier([("DecisionTreeClassifier",dtc), ("RandomForestClassifier",rfc), ("GradientBoostingClassifier",gbc), ("KNeighborsClassifier",knn), ("LogisticRegression",lg), ("RidgeClassifier",rc), ("SVM Classifier",svc), ("GaussianNB Classifier",gnb)])
vc.fit(X_train, y_train)
X_test = data_test.iloc[:,1:]
y_test =[int(i) for i in vc.predict(X_test)]
data_real_test['Survived'] = y_test
data_real_test[['PassengerId','Survived']].to_csv('2021206_泰坦尼克号项目.csv',index = False)