论文速读:AI能从人类的愚蠢中学到什么?

来源:混沌巡洋舰
本文来自对下面论文的编译和解读:

导读:随着机器在某些认知问题上超越人类,人机协作将会带来越来越显著的影响。造成人类偏见的三个主要原因(小而不完整的数据集,从自己的决策结果中学习,以及有偏见的推断和评估过程),也会造成机器学习的算法放大这些错误。研究人类愚蠢的根源,能够让我们避免在机器学习算法设计中犯同样的错。
这篇文献分别讨论了四种人类常犯的错误,本文详述前俩例。准备这篇文章,可以让读者对照反思自己是不是正在被打脸,机器学习和人工智能从业者可以从学习和决策偏差的心理学中学习到如何改进AI的经验。
1)过少的数据集
人类能够从很小的数据集中进行学习,只依靠几次经历就了解一个概念,然而这既是人类认知的强项,也是人类认知的弱点。数据集稀少,人们会由于罕见事件没有出现,而对其低估。例如人们抱着侥幸心理,基于身边没有人患病,对自己患上某种疾病的概率给予过于乐观的估计。在重复博弈中,人们也会由于对尾部风险的认识不足,没有及时做好应对预案。
在我们面对少数人群时,由于数据集过少,也会将对某个人的印象投影到特定的群体上,从而过早的形成刻板印象。当我们看到少数族裔做的好事的时候,由于样本太少,也往往会被淹没在多数群体做的好事中,而不被重视。
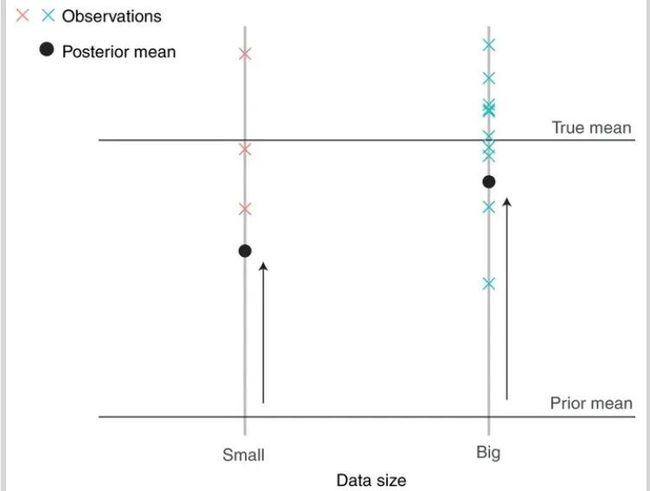
贝叶斯算法在面对小数据集时,也会犯类似的错误,下图中左边和右边都来自相同均值,随机抽样的数据集,当数据量放大之后(从左边到右边),贝叶斯对这组数据集的平均数的判断是数据的平均值变大了,然而这只是由于算法没有考虑小数据集带来的随机波动造成的。
举例来说,面部识别软件在识别深色皮肤的人的性别方面比识别浅色皮肤的人犯了更多的错误,而这是由于训练数据集中对深色皮肤和女性的数据相对较少。 类似于对个人身上的刻板印象的算法,强化了对这个人的刻板印象。减少小数据带来的虚假的关联,不管是个人还是设计AI算法者,都需要记住不同的人群,产生数据的能力是不同的,切不可忽略那些不产生数据的人群。在网课的推广中,由于忽略了那些没有智能设备的人群,因此造成的不公平,是人类愚蠢的一个让人心痛的恶果。
2)从自己的行为中学习,因果倒置
人类的行为很少仅仅是客观的观察,往往受到人类决策的影响。例如,我们只知道我们吃过的饭菜,而不是我们错过的饭菜。机器学习系统也经常在世界上采取行动,并接收数据,这取决于这些行动的后果,在包括机器人,广告,保险,金融和操作的领域。不幸的是,从自己选择的行为中学习,就像从小样本中学习一样,会产生偏见和错误的信念。例如由于人们有部分的能力避开他们不喜欢的人,消极的第一印象往往比积极的第一印象持续的时间更长。
决策者倾向于对具有可变结果的行为做出过于负面的估计,然后尽量避免这种行为,即使其平均结果实际上是正面的。 例如下图中行动的后果有好有坏,是随机出现的,然而如果决策者对某件事的评价一旦低过一个阈值,就不再尝试,从而永远不会得到纠正式反馈。例如你知道从长期来看,股票市场的收益大于银行,但由于某一次跌的太低,从此就远离股市。

由于将个人选择引入,同样会促进人与人之间的偏见。与例如如家庭成员的亲密群体进行互动和了解通常是不可避免的,因而会对其有更准确的认识,而了解群体之外的成员通常是选择性的,人们会因为偶然的第一印象而持续避免接触某类人,从而固化对其的负面印象。对于诸如幽默感智力这样需要互动才能体现的特质,往往是由于你的行为让和你互动的B显得比C更聪明,但事实上这仅仅因为你预期C无法和你进行有质量的交流,从而促成自我实现的预言。人类和机器面临的另一个共同的偏好是选择低维度数据,而不选择高维数据,从而由于自己的选择性忽视而造成偏见。
假设招聘人员审查有或没有学士学位的申请人(下图中的特征一),以及有或没有两年相关经验的申请人(特征二),并且具有任何一种资格的申请人将在公司表现良好。在雇用了几个人之后,招聘人员可能会注意到,所有拥有学士学位的申请人都表现良好,而一些没有学士学位的申请人则表现不佳,因此假设这是唯一的重要特征。如果招聘人员根据这一假设采取行动,那么未来他们将雇用拥有学士学位的申请人,而拒绝没有学士学位的申请人,因此永远不会知道拥有两年工作经验的申请人也表现良好,即使他们没有学士学位。偶然性的申请人反馈意见使招聘人员只注意到申请的一个方面,从而使他们拒绝合适的申请人,并对申请人应具备的特征产生错误的信念。
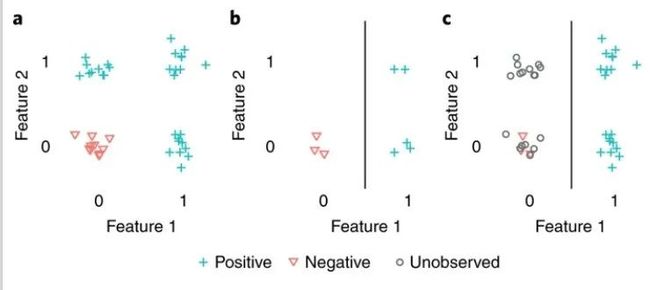
与之类似的是伯克森悖论,即你的选择标准影响你考察的范围,而你考察的范围会影响你的结论。由于伯克森悖论,会让你产生“寒门出贵子”、“为富不仁”这样虚假的关联,从因果推断的角度来看,当你选择控制了碰撞变量之后,你就会得到虚假的相关性。
在人机互动中,类似的错误体现在将警察派往过去发生过犯罪的地方的预警算法,可能会导致警察过度执法,随着时间的推移,会形成一个反馈循环,越来越多的警察被派往少数犯罪热点,从而导致在那里观察到的犯罪比例越来越高。在强化学习中,通过允许一种算法只从其在所作选择和收到的反馈中没有任何作用的抽样数据中学习。为了避免由于少量信息造成了决策固化,强化学习的agent需要从事次优行为,降低短期收益,以求收集额外信息带来的的长期回报。 就维持治安而言,这意味着接受为了确保犯罪更公平地有机会在不同地点被发现,而放弃可能的犯罪减少。
3)总结
另一种人类的错误来自于人类自身,例如人在推理过程中内生的偏差,例如使用启发式方法时面对的问题。这里由于其不具有对个人行动指导价值,没有详述。科学和技术往往是通过启发性的比喻而进步的。最近人们对机器学习和人工智能的兴趣正是源于机器和人类之间的比较,以及基于机器的系统实现了人类认知的某些方面,但却提高了人类的能力。然而,这个观点的也意味着承认这些系统,尽管它们是智能的,但是会像人们一样成为认知陷阱和偏见的受害者。对于人工智能的最新进展,一个健康的态度应该是认识到,不存在没有偏见的系统,对于在一个模糊和不确定的世界中运作的智能适应性agent来说,假设没有偏见反而是最根本性的偏见。
在大多数情况下,心理学家得出的关于人类偏见的结论并不能直接转化为改进的机器学习模型。算法偏见的技术解决方案可能会来自更多的计算领域,就像神经网络和强化学习研究尽管起源于心理学,但在计算机科学部门却蓬勃发展一样。 不过心理学文献可以提供一个路线图,告诉我们偏见可能在哪里以及如何出现,可以做出权衡以减少偏见,以及有偏见但简单的决策可能无害或有益的情况。随着机器学习和人工智能系统进入他们正在做出改变人生的决定的领域,比如医疗和刑事司法,这个路线图非常需要。我们希望,对阿莫斯 · 特沃斯基所说的“天生愚蠢”的研究能够导致更有效、更公平的人工智能。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”
