【论文速读】基于投影方法的激光雷达点云处理比较
点云PCL免费知识星球,点云论文速读。
文章:LiDAR point-cloud processing based on projection methods: a comparison
作者:Guidong Yang , Simone Mentasti , Mattia Bersani ,
翻译:particle
本文仅做学术分享,如有侵权,请联系删除。欢迎各位加入免费知识星球,获取PDF论文,欢迎转发朋友圈分享快乐。
论文阅读模块将分享点云处理,SLAM,三维视觉,高精地图相关的文章。公众号致力于理解三维视觉领域相关内容的干货分享,欢迎各位加入我,我们一起每天一篇文章阅读,开启分享之旅,有兴趣的可联系微信[email protected]。
●论文摘要
精准、快速的感知系统是自动驾驶汽车安全行驶的基础。三维目标检测方法处理激光雷达传感器获取的点云信息为每次感知系统提供精确的深度和位置信息,以及障碍物的尺寸和分类。而后,这些信息被用于目标跟踪车辆周围的车辆和其他障碍物,并为确保避免碰撞和运动规划的控制系统提供有用信息。目前,目标检测系统可分为两大类。第一种是基于几何的方法,通过对三维点云的几何和形态操作来检索障碍物。第二种是基于深度学习的,它可以直接处理3D点云,或者3D点云的其他表示形式,使用深度学习技术来检测障碍物。本文对这两种方法进行了比较,给出了每种方法在实际自动驾驶车辆上的实现方法。在实际的开发板上进行了实验测试,对算法的估计精度进行了评估。车辆和障碍物的位置由GPS传感器给出,并进行RTK校正,保证了比较准确的地面真实性。这两种算法都已在ROS上实现,并在笔记本电脑上运行。

车顶安装激光雷达的实验车
●内容介绍
基于点云的目标检测方法可以分为三个子类:基于投影的方法、基于体素卷积的方法和基于原始点云的方法。
三种方式的比较
基于投影的方法实现三维点云的单视图或多视图投影,生成二维网格,然后对其进行处理以找到具有所需置信度的目标物。然后,这个网格由2dcnn处理,或者通过传统的算法处理。复杂的YOLO,BirdNet,PIXOR将点云映射到鸟瞰图(BEV)。LMNet,VeloFCN以点云的正视图(FV)为输入。MV3D同时采用点云的BEV和FV作为输入。BEV图因其转换后具有较低的遮挡信息而被广泛应用。基于投影的方法通过投影缩小点云的维度和计算成本,同时不可避免地造成空间信息的丢失。这些方法实际上实现了精度和计算成本之间的权衡。体积卷积方法首先进行点云体素化,将三维点云表示为规则间隔的三维体素网格。点强度、高度、密度和占用率等特征都是从相应的特定体素单元内的点云手动提取的。然后采用三维卷积来处理这些体素。这些方法对点云的空间信息进行了清晰的编码,与基于投影的方法相比,信息丢失少,从而获得了较高的检测精度。然而,由于三维卷积的计算代价昂贵,以及点云稀疏导致的空体素,体积卷积方法耗时且效率低下。基于投影的方法和体素卷积方法的目的是将点云转换为二维图像或三维体素网格。不同的是,基于原始点云的方法直接处理点云,以最小化空间信息损失。大多数基于原始点云的方法都是PointNet的衍生,广泛用于对象分类和语义分割。PointNet++是PointNet的升级版本,可以有效地提取局部特征,而 Frustum PointNet允许基于图像平面上的2D检测构造点云子集。然后将这些子集直接送入PointNet进行分类和预测。综上所述,基于投影的方法由于与成熟的二维目标检测方法相似,在自动驾驶场景中得到了很好的研究。即使基于人工的特征提取,它们在时间复杂性和检测性能之间提供了很好的折衷。
本文比较了在自动驾驶车辆的状态估计算法中实现的两种不同的基于投影的方法。第一个解决方案基于开源的基于Apollo-FCNN的目标检测算法;第二个解决方案是该实验室开发的基于几何的3D点云处理方案。实验车装有1线激光雷达传感器。验证和比较方法的真值是基于用RTK校正的目标物体的GPS测量值。这两种算法都是在ROS上实现的,基于深度学习的方法在NVIDIA GTX 1050Ti上运行,而几何算法只在CPU上运行。
FCNN-BASED 目标检测的方法
Apollo 是一个开放式的自主驾驶平台,它发布了实现自主驾驶的所有最重要的模块。关于感知任务,Apollo使用全卷积神经网络(FCNN)对激光雷达传感器提供的点云进行分割。Apollo利用大规模数据集训练和测试了基于fcnn的目标检测模型,确保了高水平的鲁棒性和准确性。

GEOMETRIC-BASED 目标检测
图示处理从三维点云到二维占用网格的转换,包括聚类、识别和跟踪的最终任务。第一步是去除所有属于地面的检测点,即路面,以减少估计过程中的误报率。为了完成这项任务,平面拟合问题基于RANSAC(随机样本一致性)。一旦地平面被移除,所有剩余点很可能属于障碍物。

● 实验与对比
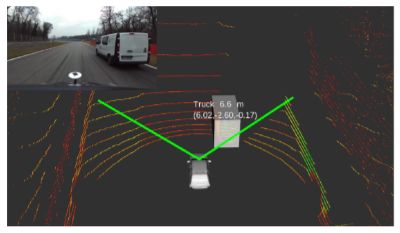

估计值与实际值(GT)的比较
●总结
本文比较了自主驾驶中障碍物状态估计的两种算法。所分析的算法以旋转式激光雷达传感器获取的三维点云作为输入,估计了自动驾驶车辆周围障碍物或者车辆的距离。此外,两种算法都给出了每次检测的主要障碍物尺度的估计值。
资源
三维点云论文及相关应用分享
【点云论文速读】基于激光雷达的里程计及3D点云地图中的定位方法
3D目标检测:MV3D-Net
三维点云分割综述(上)
3D-MiniNet: 从点云中学习2D表示以实现快速有效的3D LIDAR语义分割(2020)
win下使用QT添加VTK插件实现点云可视化GUI
JSNet:3D点云的联合实例和语义分割
大场景三维点云的语义分割综述
PCL中outofcore模块---基于核外八叉树的大规模点云的显示
基于局部凹凸性进行目标分割
基于三维卷积神经网络的点云标记
点云的超体素(SuperVoxel)
基于超点图的大规模点云分割
更多文章可查看:点云学习历史文章大汇总
SLAM及AR相关分享
【开源方案共享】ORB-SLAM3开源啦!
【论文速读】AVP-SLAM:自动泊车系统中的语义SLAM
【点云论文速读】StructSLAM:结构化线特征SLAM
SLAM和AR综述
常用的3D深度相机
AR设备单目视觉惯导SLAM算法综述与评价
SLAM综述(4)激光与视觉融合SLAM
Kimera实时重建的语义SLAM系统
SLAM综述(3)-视觉与惯导,视觉与深度学习SLAM
易扩展的SLAM框架-OpenVSLAM
高翔:非结构化道路激光SLAM中的挑战
SLAM综述之Lidar SLAM
基于鱼眼相机的SLAM方法介绍
往期线上分享录播汇总
第一期B站录播之三维模型检索技术
第二期B站录播之深度学习在3D场景中的应用
第三期B站录播之CMake进阶学习
第四期B站录播之点云物体及六自由度姿态估计
第五期B站录播之点云深度学习语义分割拓展
第六期B站录播之Pointnetlk解读
[线上分享录播]点云配准概述及其在激光SLAM中的应用
[线上分享录播]cloudcompare插件开发
[线上分享录播]基于点云数据的 Mesh重建与处理
[线上分享录播]机器人力反馈遥操作技术及机器人视觉分享
[线上分享录播]地面点云配准与机载点云航带平差
点云PCL更多活动请查看:点云PCL活动之应届生校招群
扫描下方微信视频号二维码可查看最新研究成果及相关开源方案的演示:

如果你对本文感兴趣,请点击“原文阅读”获取知识星球二维码,务必按照“姓名+学校/公司+研究方向”备注加入免费知识星球,免费下载pdf文档,和更多热爱分享的小伙伴一起交流吧!
以上内容如有错误请留言评论,欢迎指正交流。如有侵权,请联系删除

扫描二维码
关注我们
让我们一起分享一起学习吧!期待有想法,乐于分享的小伙伴加入免费星球注入爱分享的新鲜活力。分享的主题包含但不限于三维视觉,点云,高精地图,自动驾驶,以及机器人等相关的领域。
分享及合作方式:群主微信“920177957”(需要按要求备注) 联系邮箱:[email protected],欢迎企业来联系公众号展开合作。
点一下“在看”你会更好看耶
