长短期记忆网络(LSTM)原理与实战
1. 前言
本文详解LSTM(Long Short Term Memory)原理,并使用飞桨(PaddlePaddle)基于IMDB电影评论数据集实现电影评论情感分析。
本人全部文章请参见:博客文章导航目录
本文归属于:自然语言处理系列
本系列实践代码请参见:我的GitHub
前文:简单循环神经网络(Simple RNN)原理与实战
后文:循环神经网络的改进:多层RNN、双向RNN与预训练
2. LSTM网络结构
LSTM是一种RNN模型,是对Simple RNN的改进,结构如图一所示。其原理与Simple RNN类似,每当读取一个新的输入 x x x,就会更新状态向量 h h h。

LSTM网络结构比Simple RNN复杂很多,其使用传输带(Conveyor Belt,见图二)将过去的信息送到下一个时刻,并使用“门(Gate)”结构遗忘传输带上的信息或向传输带上添加新的信息。这种结构设计,缓解了梯度消失问题,从而获得比Simple RNN更长的记忆能力。

2.1 遗忘门(Forget Gate)
“门”是一种让信息选择式通过的结构,包含一个Sigmoid操作和一个Elementwise Multiplication(两个同样大小矩阵对应元素相乘,得到一个新的同样大小的矩阵)操作。
如图三所示,遗忘门决定过去哪些信息被遗忘,其读取 h t − 1 h_{t-1} ht−1和 x t x_t xt,输出 f t 为 f_t为 ft为一个与传输带状态向量 C t − 1 C_{t-1} Ct−1大小相同且每个元素均在0到1之间的向量。
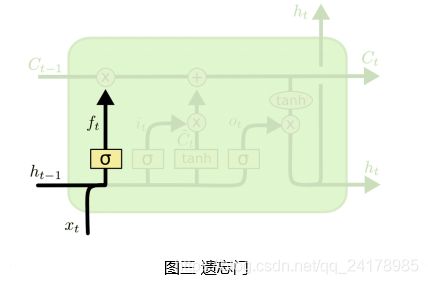
遗忘门 f t f_t ft的具体计算过程如下,将上一时刻状态向量 h t − 1 h_{t-1} ht−1和当前时刻输入向量 x t x_t xt拼接,然后左乘参数矩阵 W f W_f Wf,并使用激活函数Sigmoid作用在得到的新矩阵的每一个元素上(示意图中没考虑添加偏置情况,但公式中加上了偏置项,下同),得到一个与传输带状态向量 C t − 1 C_{t-1} Ct−1大小相同的向量 f t f_t ft, f t = σ ( W f [ h t − 1 , x t ] + b f ) f_t=\sigma(W_f[h_{t-1}, x_t]+b_f) ft=σ(Wf[ht−1,xt]+bf)。
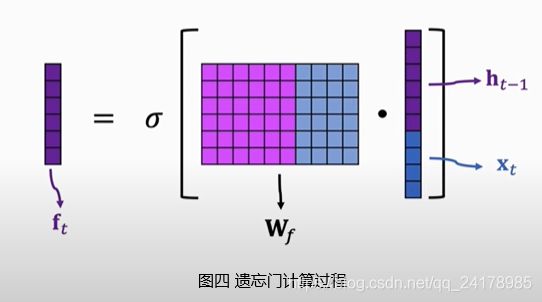
2.2 输入门(Input Gate)
如下图所示, C t ~ \tilde{C_t} Ct~可以看做输入 h t − 1 h_{t-1} ht−1和 x t x_t xt生成的输入信息,输入门的输出 i t i_t it与生成的输入值向量 C t ~ \tilde{C_t} Ct~做Elementwise Multiplication,决定向传输带上添加哪些新的信息。
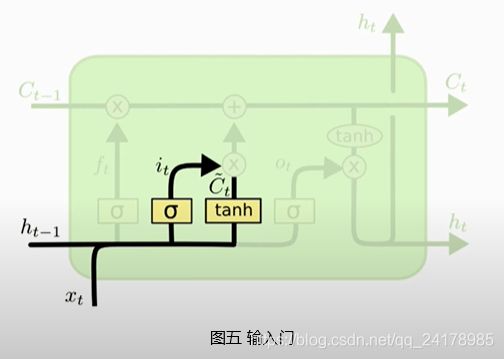
生成的输入值向量 C t ~ \tilde{C_t} Ct~和输入门 i t i_t it的具体计算过程如下。将上一时刻状态向量 h t − 1 h_{t-1} ht−1和当前时刻输入向量 x t x_t xt拼接,然后分别左乘参数矩阵 W c W_c Wc和 W i W_i Wi,再分别使用激活函数tanh和Sigmoid作用在得到的新矩阵的每一个元素上,得到 C t ~ \tilde{C_t} Ct~和 i t i_t it, C t ~ = t a n h ( W c [ h t − 1 , x t ] + b c ) \tilde{C_t}=tanh(W_c[h_{t-1}, x_t]+b_c) Ct~=tanh(Wc[ht−1,xt]+bc), i t = σ ( W i [ h t − 1 , x t ] + b i ) i_t=\sigma(W_i[h_{t-1}, x_t]+b_i) it=σ(Wi[ht−1,xt]+bi)。
 ~~~~~~~~~~~~~~~~~~~~~~~~
~~~~~~~~~~~~~~~~~~~~~~~~ 
2.3 传输带状态向量更新
计算得到遗忘门 f t f_t ft,输入门 i t i_t it和生成的输入值向量 C t ~ \tilde{C_t} Ct~,并且知道传输带旧状态向量 C t − 1 C_{t-1} Ct−1,则可按照如下方法更新传输带上的信息:
- 将传输带旧值 C t − 1 C_{t-1} Ct−1与 f t f_t ft做Elementwise Multiplication,遗忘部分信息;
- 将生成的输入值向量 C t ~ \tilde{C_t} Ct~与 i t i_t it做Elementwise Multiplication,得到输入信息;
- 令 C t = f t ⊗ C t − 1 + i t ⊗ C t ~ C_t=f_t\otimes C_{t-1}+i_t\otimes \tilde{C_t} Ct=ft⊗Ct−1+it⊗Ct~,得到新传输带状态向量。

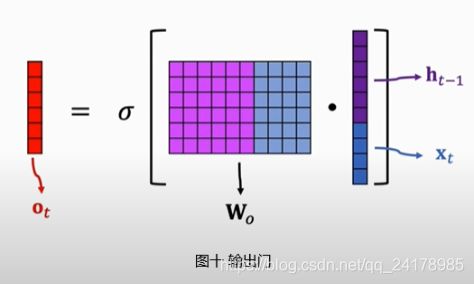
2.4 输出门(Output Gate)
如图九所示,输出门决定传输带上哪些信息被输出, o t = σ ( W o [ h t − 1 , x t ] + b o ) o_t=\sigma(W_o[h_{t-1}, x_t]+b_o) ot=σ(Wo[ht−1,xt]+bo)。将tanh函数作用与新传输带状态向量 C t C_t Ct,然后将结果与 o t o_t ot做Elementwise Multiplication,即得到 t t t时刻输出 h t h_t ht。

具体计算过程如下图所示:
 ~~
~~ 
3. 遗忘问题缓解机制
LSTM使用了传输带结构设计,使得过去的信息很容易传输到下一时刻,从而获得了比Simple RNN更长的记忆能力。根据前文所述内容,LSTM模型计算公式可总结如下:
遗 忘 门 f t : f t = σ ( W f [ h t − 1 , x t ] + b f ) ( 1 ) 输 入 门 i t : i t = σ ( W i [ h t − 1 , x t ] + b i ) ( 2 ) 输 出 门 o t : o t = σ ( W o [ h t − 1 , x t ] + b o ) ( 3 ) 生 成 的 输 入 值 向 量 C t ~ : C t ~ = t a n h ( W c [ h t − 1 , x t ] + b c ) ( 4 ) 新 传 输 带 状 态 向 量 C t : C t = f t ⊗ C t − 1 + i t ⊗ C t ~ ( 5 ) 状 态 向 量 h t : h t = o t ⊗ t a n h ( C t ) ( 6 ) 遗忘门f_t:f_t=\sigma(W_f[h_{t-1}, x_t]+b_f)~~~~~~~~~~~~~~~~~~~(1)\\ 输入门i_t:i_t=\sigma(W_i[h_{t-1}, x_t]+b_i)~~~~~~~~~~~~~~~~~~~~(2)\\ 输出门o_t:o_t=\sigma(W_o[h_{t-1}, x_t]+b_o)~~~~~~~~~~~~~~~~~~~(3)\\ 生成的输入值向量\tilde{C_t}:\tilde{C_t}=tanh(W_c[h_{t-1}, x_t]+b_c)~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~(4)\\ 新传输带状态向量C_t:C_t=f_t\otimes C_{t-1}+i_t\otimes \tilde{C_t}~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~(5)\\ 状态向量h_t:h_t=o_t\otimes tanh(C_t)~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~(6) 遗忘门ft:ft=σ(Wf[ht−1,xt]+bf) (1)输入门it:it=σ(Wi[ht−1,xt]+bi) (2)输出门ot:ot=σ(Wo[ht−1,xt]+bo) (3)生成的输入值向量Ct~:Ct~=tanh(Wc[ht−1,xt]+bc) (4)新传输带状态向量Ct:Ct=ft⊗Ct−1+it⊗Ct~ (5)状态向量ht:ht=ot⊗tanh(Ct) (6)
RNN使用相同的计算单元重复作用于不同时刻的输入向量 x t x_t xt与状态向量 h t − 1 h_{t-1} ht−1,产生下一时刻的新状态向量 h t h_t ht。 h t h_t ht是 x t x_t xt和 h t − 1 h_{t-1} ht−1的函数。因此, ∂ h t ∂ x t − k \frac{\partial h_t}{\partial x_{t-k}} ∂xt−k∂ht的计算公式必定存在 ∂ h t ∂ h t − 1 ∂ h t − 1 ∂ h t − 2 ⋯ ∂ h t − k + 1 ∂ h t − k \frac{\partial h_t}{\partial h_{t-1}}\frac{\partial h_{t-1}}{\partial h_{t-2}}\cdots\frac{\partial h_{t-k+1}}{\partial h_{t-k}} ∂ht−1∂ht∂ht−2∂ht−1⋯∂ht−k∂ht−k+1沿时间轴传播链式计算部分。在Simple RNN中,由于 ∂ h t ∂ h t − 1 = ∂ h t ∂ z t W h ( 其 中 z t = W i x t + W h h t − 1 + b , h t = t a n h ( z t ) ) \frac{\partial h_t}{\partial h_{t-1}}=\frac{\partial h_t}{\partial z_t}W_h(其中z_t=W_ix_t+W_hh_{t-1}+b, h_t=tanh(z_t)) ∂ht−1∂ht=∂zt∂htWh(其中zt=Wixt+Whht−1+b,ht=tanh(zt))中包含 W h W_h Wh,当 k k k较大时, ∂ h t ∂ h t − 1 ∂ h t − 1 ∂ h t − 2 ⋯ ∂ h t − k + 1 ∂ h t − k \frac{\partial h_t}{\partial h_{t-1}}\frac{\partial h_{t-1}}{\partial h_{t-2}}\cdots\frac{\partial h_{t-k+1}}{\partial h_{t-k}} ∂ht−1∂ht∂ht−2∂ht−1⋯∂ht−k∂ht−k+1计算式中相当于存在多个 W h W_h Wh连乘。若 W h W_h Wh值较小,则连乘导致整个计算式值接近于0, ∂ h t ∂ x t − k \frac{\partial h_t}{\partial x_{t-k}} ∂xt−k∂ht值接近于0,即输入向量 x t − k x_{t-k} xt−k发生改变,状态向量 h t h_t ht基本不发生改变, h t h_t ht与 x t − k x_{t-k} xt−k基本不存在相关关系,Simple RNN遗忘了比较久之前的信息。
LSTM使用传输带将 t t t时刻之前的信息送到第 t t t个时刻,状态向量 h t h_t ht是 C t C_t Ct的函数,因此可用 ∂ C t ∂ C t − 1 \frac{\partial C_t}{\partial C_{t-1}} ∂Ct−1∂Ct将后一时刻梯度沿时间轴传播至前一时刻。
公式(5)表明 C t C_t Ct是 f t , C t − 1 , i t , C t ~ f_t,C_{t-1},i_t,\tilde{C_t} ft,Ct−1,it,Ct~的函数。公式(1)、(2)、(4)表明 f t , i t , C t ~ f_t,i_t,\tilde{C_t} ft,it,Ct~是 h t − 1 h_{t-1} ht−1的函数,公式(6)表明 h t − 1 h_{t-1} ht−1是 C t − 1 C_{t-1} Ct−1的函数,即 f t , i t , C t ~ f_t,i_t,\tilde{C_t} ft,it,Ct~是 C t − 1 C_{t-1} Ct−1的函数。因此, ∂ C t ∂ C t − 1 \frac{\partial C_t}{\partial C_{t-1}} ∂Ct−1∂Ct计算如下:
∂ C t ∂ C t − 1 = f t + ∂ f t ∂ C t − 1 C t − 1 + i t ∂ C ~ t ∂ C t − 1 + ∂ i t ∂ C t − 1 C t ~ ( 7 ) \frac{\partial C_t}{\partial C_{t-1}}=f_t+\frac{\partial f_t}{\partial C_{t-1}}C_{t-1}+i_t\frac{\partial{\tilde C_t}}{\partial C_{t-1}}+\frac{\partial i_t}{\partial C_{t-1}}\tilde{C_t}~~~~~~~~~~~~~~~~~~~~~~~~(7) ∂Ct−1∂Ct=ft+∂Ct−1∂ftCt−1+it∂Ct−1∂C~t+∂Ct−1∂itCt~ (7)
据式(7)可知, ∂ C t ∂ C t − 1 \frac{\partial C_t}{\partial C_{t-1}} ∂Ct−1∂Ct由四项相加所得,其中第一项为遗忘门 f t f_t ft的输出,其值上界为1,梯度沿时间轴向前传播的链式计算式中不存在Simple RNN中连乘多次参数矩阵的情况,网络结构上保证了LSTM有联系长距离上下文的能力。在模型训练参数初始化时,一般会将遗忘门初始化为接近1的值,保证梯度能够长距离传播,即初始默认认为所有上下文信息均须保留,而实际情况是否真的需要保存所有上下文信息,交由模型在训练数据中学习。
4. 电影评论情感分析(三)
LSTM模型拥有比Simple RNN更长的记忆能力,而且在实践中可以发现LSTM效果总是比Simple RNN好。虽然在RNN模型领域还存在GRU(Gated Recurrent Unit)等模型设计,但是在一般情况下其它RNN模型效果也不比LSTM效果好多少,因此在需要运用RNN模型时候,一般建议首选LSTM模型。
电影评论情感分析(三)使用LSTM模型分析电影评论情感,设计如下:
- 模型结构:Embedding层+LSTM层+Softmax分类器
- 词嵌入维度:16
- 状态向量维度:32
4.1 模型搭建
数据处理与3.1部分相同,直接介绍搭建神经网络模型。定义继承自paddle.nn.Layer的MyLSTM类,在初始化函数__init__中定义网络各层,重写forward方法,实现前向计算流程。代码如下:
# -*- coding: utf-8 -*-
# @Time : 2021/7/4 9:55
# @Author : He Ruizhi
# @File : lstm.py
# @Software: PyCharm
import paddle
from emb_softmax import get_data_loader
import warnings
warnings.filterwarnings('ignore')
class MyLSTM(paddle.nn.Layer):
def __init__(self, embedding_dim, hidden_size):
super(MyLSTM, self).__init__()
self.emb = paddle.nn.Embedding(num_embeddings=5149, embedding_dim=embedding_dim)
self.lstm = paddle.nn.LSTM(input_size=embedding_dim, hidden_size=hidden_size)
self.fc = paddle.nn.Linear(in_features=hidden_size, out_features=2)
self.softmax = paddle.nn.Softmax()
def forward(self, x):
x = self.emb(x)
# LSTM层分别返回所有时刻状态和最后时刻h与c状态,这里只使用最后时刻的h
_, (x, _) = self.lstm(x)
# 去掉第0维,这么处理与PaddlePaddle的LSTM层返回格式有关
x = paddle.squeeze(x, axis=0)
x = self.fc(x)
x = self.softmax(x)
return x
4.2 模型训练
设置超参数seq_len = 200、emb_size = 16,调用get_data_loader函数加载训练和测试数据,实例化模型对象并使用paddle.Model封装。使用model.summary获得模型信息如下:
-----------------------------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===============================================================================================
Embedding-1 [[1, 200]] [1, 200, 16] 82,384
LSTM-1 [[1, 200, 16]] [[1, 200, 32], [[1, 1, 32], [1, 1, 32]]] 6,400
Linear-1 [[1, 32]] [1, 2] 66
Softmax-1 [[1, 2]] [1, 2] 0
===============================================================================================
Total params: 88,850
Trainable params: 88,850
Non-trainable params: 0
-----------------------------------------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.07
Params size (MB): 0.34
Estimated Total Size (MB): 0.41
-----------------------------------------------------------------------------------------------
使用model.prepare进行模型配置,使用paddle.optimizer.Adam优化器、paddle.nn.CrossEntropyLoss损失函数,并添加paddle.metric.Accuracy作为衡量指标。使用model.fit开启模型训练,设置eopchs=5,将test_data_loader作为验证数据。模型训练部分代码如下:
if __name__ == '__main__':
seq_len = 200
emb_size = 16
hidden_size = 32
train_data_loader = get_data_loader('train', seq_len=seq_len, data_show=1)
test_data_loader = get_data_loader('test', seq_len=seq_len)
model = paddle.Model(MyLSTM(16, 32))
model.summary(input_size=(None, seq_len), dtype='int64')
model.prepare(optimizer=paddle.optimizer.Adam(learning_rate=0.01, parameters=model.parameters()),
loss=paddle.nn.CrossEntropyLoss(use_softmax=False),
metrics=paddle.metric.Accuracy())
model.fit(train_data_loader, epochs=5, verbose=1, eval_data=test_data_loader)
训练过程信息如下:
The loss value printed in the log is the current step, and the metric is the average value of previous steps.
Epoch 1/5
step 195/195 [==============================] - loss: 0.6897 - acc: 0.5111 - 13ms/step
Eval begin...
step 195/195 [==============================] - loss: 0.6718 - acc: 0.5367 - 7ms/step
Eval samples: 24960
Epoch 2/5
step 195/195 [==============================] - loss: 0.6352 - acc: 0.5819 - 12ms/step
Eval begin...
step 195/195 [==============================] - loss: 0.6926 - acc: 0.6001 - 7ms/step
Eval samples: 24960
Epoch 3/5
step 195/195 [==============================] - loss: 0.3323 - acc: 0.7799 - 12ms/step
Eval begin...
step 195/195 [==============================] - loss: 0.2929 - acc: 0.8358 - 7ms/step
Eval samples: 24960
Epoch 4/5
step 195/195 [==============================] - loss: 0.2136 - acc: 0.8827 - 12ms/step
Eval begin...
step 195/195 [==============================] - loss: 0.2270 - acc: 0.8569 - 7ms/step
Eval samples: 24960
Epoch 5/5
step 195/195 [==============================] - loss: 0.2640 - acc: 0.9167 - 12ms/step
Eval begin...
step 195/195 [==============================] - loss: 0.2964 - acc: 0.8537 - 7ms/step
Eval samples: 24960
经过对训练样本5轮迭代,模型验证准确率可达
85.69%。显然使用LSTM模型效果远远优于Simple RNN模型。
5. 参考资料链接
- https://www.icourse163.org/learn/ZUCC-1206146808?tid=1461395446#/learn/content?type=detail&id=1237779507&cid=1257874386
- https://www.youtube.com/watch?v=vTouAvxlphc&list=PLvOO0btloRnuTUGN4XqO85eKPeFSZsEqK&index=4
- https://blog.csdn.net/nuohuang3371/article/details/111655642