图卷积神经网络笔记——第五章:(2)基于PyG库构造自己的数据集&查阅其他GCN方法
上一小节: 链接.
虽然PyTorch geometry已经包含了许多有用的数据集,但我们可能希望使用自己记录的或非公开可用的数据创建自己的数据集。这一小节看基于PyG库构造自己的数据集和查阅其他GCN方法。
目录
- 一、构造自己的数据集
- 1、创建 “In Memory Datasets”
- 2、创建 “Larger” Datasets
- 二、查阅其他GCN方法
- 1、问题分析
- 2、解决方案
一、构造自己的数据集
PyG为数据集提供了两个抽象类: torch_geometric.data.Dataset和torch_geometric.data.InMemoryDataset。
torch_geometric.data.InMemoryDataset继承torch_geometry .data.Dataset,并且如果整个数据集都能装入内存,则应该使用。
torch_geometry.data.Dataset就是每读取一个Batch就要重新从硬盘读取这些数据放入缓存中,比较适合大规模的数据集。
上面就是这两个类的区别。下面具体看看。
1、创建 “In Memory Datasets”
为了创建torch_geometor.data.InMemoryDataset,需要实现四个基本方法:
(1)torch_geometric.data.InMemoryDataset.raw_file_names()
告诉原始的数据集存放在哪个文件夹下面,如果数据集已经存放进去了,那么就会直接读取。
(2)torch_geometric.data.InMemoryDataset.processed_file_names()
为了进一步使程序加速,提供了已经处理好的数据的文件夹的位置。比如说要进行GCN图卷积,如果已经处理好了数据,那么就会直接读取处理好的数据,而构造图结构、归一化数据这些操作都免去了。
(3)torch_geometric.data.InMemoryDataset.download()
下载原始数据到指定的文件夹下。
(4)torch_geometric.data.InMemoryDataset.process()
处理原始数据并将其保存到processed_dir中。
通过一个简单的例子来看看这个过程:
import torch
import torch_geometric
import numpy as np
from torch_geometric.data import InMemoryDataset
from torch_geometric.data import Data
from torch_geometric.data import DataLoader
# 创建一个随机的dataset
def toy_dataset(num_nodes, num_node_features, num_edges):
x = np.random.randn(num_nodes, num_node_features) # 节点数 x 节点特征
edge_index = np.random.randint(low=0, high=num_nodes-1, size=[2, num_edges], dtype=np.int64) # [2, num_edges]
data = Data(x=torch.from_numpy(x), edge_index=torch.from_numpy(edge_index)) # 转换成张量,再实例化Data类
return data
# In Memory Dataset
class PyGToyDataset(InMemoryDataset):
def __init__(self, save_root, transform=None, pre_transform=None):
"""
:param save_root:保存数据的目录
:param pre_transform:在读取数据之前做一个数据预处理的操作
:param transform:在访问之前动态转换数据对象(因此最好用于数据扩充)
"""
super(PyGToyDataset, self).__init__(save_root, transform, pre_transform)
self.data, self.slices = torch.load(self.processed_file_names[0])
@property
def raw_file_names(self): # 原始数据文件夹存放位置,这个例子中是随机出创建的,所以这个文件夹为空
return ['origin_dataset']
@property
def processed_file_names(self):
return ['toy_dataset.pt']
def download(self): # 这个例子中不是从网上下载的,所以这个函数pass掉
pass
def process(self): # 处理数据的函数,最关键(怎么创建,怎么保存)
# 创建了100个样本,每个样本是一个图,每个图有32个节点,每个节点3个特征,每个图有42个边
data_list = [toy_dataset(num_nodes=32, num_node_features=3, num_edges=42) for _ in range(100)]
data_save, data_slices = self.collate(data_list) # 直接保存list可能很慢,所以使用collate函数转换成大的torch_geometric.data.Data对象
torch.save((data_save, data_slices), self.processed_file_names[0])
if __name__ == "__main__":
# toy_sample = toy_dataset(num_nodes=32, num_node_features=3, num_edges=42)
# print(toy_sample)
toy_data = PyGToyDataset(save_root="toy") # 100个样本(图)
# print(toy_data[0])
data_loader = DataLoader(toy_data, batch_size=5, shuffle=True) # batch_size=5实现了平行化——就是把5张图放一起了
for batch in data_loader: # 循环了20次
print(batch)
说明:
每个数据集都可以传递一个transform、一个pre_transform和一个pre_filter函数,这些函数在默认情况下为None。transform函数在访问之前动态地转换数据对象(因此最好用于数据扩充)。pre_transform函数在将数据对象保存到磁盘之前应用转换(因此它最好用于只需执行一次的大量预计算)。pre_filter函数可以在保存之前手动过滤掉数据对象。用例可能涉及数据对象属于特定类的限制。
2、创建 “Larger” Datasets
用于创建无法装入内存的数据集,可以使用torch_geometor.data.Dataset,这紧跟 torchvision 数据集的概念。此外,还需要执行下列方法:
torch_geometric.data.Dataset.len(): 返回数据集中示例的数目。torch_geometric.data.Dataset.get(): 实现加载单个图的逻辑。
在内部,torch_geometry.data. dataset.__getitem__()从 torch_geometry .data. data. get() 获取数据对象,并根据transform可选地转换它们。
看一个简单的例子来说明这个过程:
import os.path as osp
import torch
from torch_geometric.data import Dataset
class MyOwnDataset(Dataset):
def __init__(self, root, transform=None, pre_transform=None):
super(MyOwnDataset, self).__init__(root, transform, pre_transform) # 继承父类所有方法
@property
def raw_file_names(self): # 原始数据文件夹存放位置
return ['some_file_1', 'some_file_2', ...]
@property
def processed_file_names(self): # 处理后保存的文件名
return ['data_1.pt', 'data_2.pt', ...]
def download(self):
# Download to `self.raw_dir`.
def process(self):
i = 0
for raw_path in self.raw_paths:
# Read data from `raw_path`.
data = Data(...)
if self.pre_filter is not None and not self.pre_filter(data):
continue
if self.pre_transform is not None:
data = self.pre_transform(data)
torch.save(data, osp.join(self.processed_dir, 'data_{}.pt'.format(i))) # 第一个参数为实例,第二个为处理后数据保存的文件名
i += 1
def len(self): # 返回数据集中示例的数目。
return len(self.processed_file_names)
def get(self, idx):
data = torch.load(osp.join(self.processed_dir, 'data_{}.pt'.format(idx)))
return data
在这里,每个图数据对象在process()中单独保存,并在get()中手动加载。
注:
程序运行一次后,只要不重写download()和process()方法,就可以跳过下载和处理。
最后还要说明:
像在常规PyTorch中一样,不是必须使用 datasets,例如,当我们想动态创建合成数据而不显式地将其保存到磁盘时。在本例中,只需传递一个包含torch_geometry.data.Data的常规python列表数据对象,并将其传递给torch_geometry.Data.dataloader
from torch_geometric.data import Data, DataLoader
data_list = [Data(...), ..., Data(...)]
loader = DataLoader(data_list, batch_size=32)
二、查阅其他GCN方法
上一节调用了GCN模型: Y = A ^ W X Y=\hat AWX Y=A^WX来实现了cora数据集的节点分类,现在接着基于cora数据集实现节点分类来看看其他的图卷积方法,在PyG的官方文档查看。
查看:链接.
如下图:

为此,通过别的图卷积模型来实现cora数据集的节点分类,准确率达到82%。
1、问题分析
虽然基于cora数据集的节点分类是个很简单的问题,但也算是一个小项目,那么就要有以下的流程:
- 数据分析:看看数据有什么特征,长什么样子,可以打印出来,也可以可视化看看什么样子,当然要是能直接打开原文件最好不过了。
- 训练可视化:模型的训练尽量可视化越多越好,这样可以判断在训练过程中到底发生了什么样的变化。
- 模型选择:整个框架搭建好了之后,就可以选择具体的图卷积了。
下面具体看看:
1、数据分析:
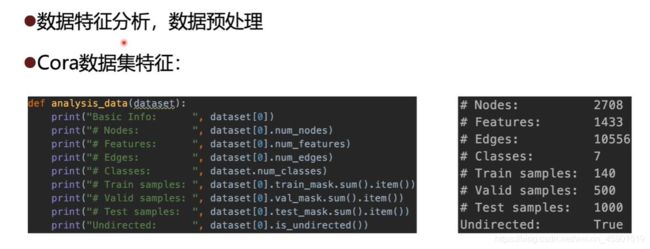
上面就是通过打印数据集的各种维度来了解数据集的特征。

通过对下载的数据进行transform和pre_transform操作。这个我上面已经说过了,下面再看一下这两个的作用是什么。
每个数据集都可以传递一个transform、一个pre_transform和一个pre_filter函数,这些函数在默认情况下为None。transform函数在访问之前动态地转换数据对象(因此最好用于数据扩充)。pre_transform函数在将数据对象保存到磁盘之前应用转换(因此它最好用于只需执行一次的大量预计算)。pre_filter函数可以在保存之前手动过滤掉数据对象。用例可能涉及数据对象属于特定类的限制。
2、训练可视化:

对训练、验证、测试的准确率可视化,就能够很好的发现模型是否可用,参数是否合理,尤其是加入验证集能够防止过拟合现象。
3、模型选择:
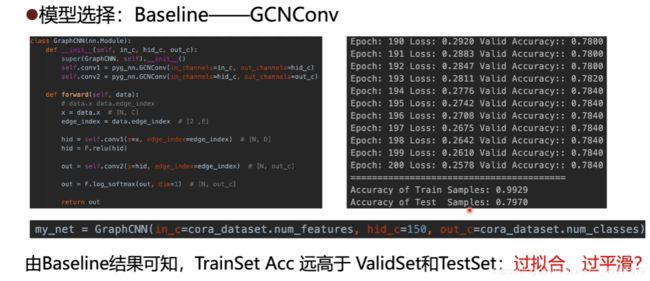
查看PyG官方文档看看GCNConv为什么效果不太好:

2、解决方案
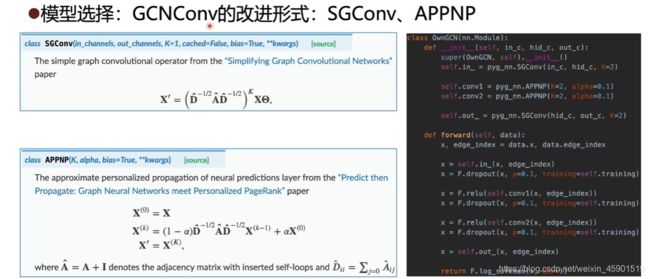
现在知道了GCNConv模型的过平滑现象会造成测试结果的不理想,其实早就有对GCNConv改进的模型了,看看PyG官方文档:
-
SGConv就是对 A ^ \hat A A^进行了 K K K次幂, K = 1 K=1 K=1就是普通的GCNConv了,这个论文我贴在这里:链接.感兴趣的可以看看,为什么这样就防止过平滑了。
-
APPNP还是一阶空域的图卷积,实际上,这个模型通过加入 α \alpha α 来更多的保留自身节点的信息,具体而言:
![]()
当 α = 0 \alpha=0 α=0 时,就是普通的GCNConv了,当 α \alpha α在(0,1)之间时,就会舍弃一些图卷积之后的的信息,同时会保留一些原本自身节点的信息,这样也就防止了过平滑的现象了。详细的看论文:链接: link.
最终,我们通过这两种图卷积来构建模型,因为SGConv可以控制输入输出,所以放在第一层和第四层,具体模型的代码如下:
class OwnGCN(nn.Module):
def __init__(self, in_c, hid_c, out_c):
super(OwnGCN, self).__init__()
self.in_ = pyg_nn.SGConv(in_c, hid_c, K=2)
self.conv1 = pyg_nn.APPNP(K=2, alpha=0.1)
self.conv2 = pyg_nn.APPNP(K=2, alpha=0.1)
self.out_ = pyg_nn.SGConv(hid_c, out_c, K=2)
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.in_(x, edge_index)
x = F.dropout(x, p=0.1, training=self.training) # 做一个采样,提高模型的鲁棒性
x = F.relu(self.conv1(x, edge_index))
x = F.dropout(x, p=0.1, training=self.training)
x = F.relu(self.conv2(x, edge_index))
x = F.dropout(x, p=0.1, training=self.training)
x = self.out_(x, edge_index)
return F.log_softmax(x, dim=1)
下面是模型的超参数选择:

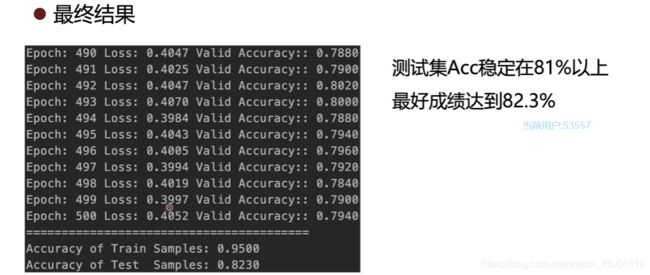
下面我将修正后完整的代码贴在下面:
# -*- coding: utf-8 -*-
import os
import torch
import torch.nn.functional as F
import torch.nn as nn
from torch_geometric.datasets import Planetoid
import torch_geometric.nn as pyg_nn
import torch_geometric.transforms as T
# load dataset
def get_data(folder="node_classify/cora", data_name="cora"):
dataset = Planetoid(root=folder, name=data_name,
transform=T.NormalizeFeatures())
return dataset
# create the graph cnn model
class GraphCNN(nn.Module):
def __init__(self, in_c, hid_c, out_c):
super(GraphCNN, self).__init__()
self.conv1 = pyg_nn.GCNConv(in_channels=in_c, out_channels=hid_c)
self.conv2 = pyg_nn.GCNConv(in_channels=hid_c, out_channels=out_c)
def forward(self, data):
# data.x data.edge_index
x = data.x # [N, C]
edge_index = data.edge_index # [2 ,E]
hid = self.conv1(x=x, edge_index=edge_index) # [N, D]
hid = F.relu(hid)
out = self.conv2(x=hid, edge_index=edge_index) # [N, out_c]
out = F.log_softmax(out, dim=1) # [N, out_c]
return out
class OwnGCN(nn.Module):
def __init__(self, in_c, hid_c, out_c):
super(OwnGCN, self).__init__()
self.in_ = pyg_nn.SGConv(in_c, hid_c, K=2)
self.conv1 = pyg_nn.APPNP(K=2, alpha=0.1)
self.conv2 = pyg_nn.APPNP(K=2, alpha=0.1)
self.out_ = pyg_nn.SGConv(hid_c, out_c, K=2)
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.in_(x, edge_index)
x = F.dropout(x, p=0.1, training=self.training)
x = F.relu(self.conv1(x, edge_index))
x = F.dropout(x, p=0.1, training=self.training)
x = F.relu(self.conv2(x, edge_index))
x = F.dropout(x, p=0.1, training=self.training)
x = self.out_(x, edge_index)
return F.log_softmax(x, dim=1)
def analysis_data(dataset):
print("Basic Info: ", dataset[0])
print("# Nodes: ", dataset[0].num_nodes)
print("# Features: ", dataset[0].num_features)
print("# Edges: ", dataset[0].num_edges)
print("# Classes: ", dataset.num_classes)
print("# Train samples: ", dataset[0].train_mask.sum().item())
print("# Valid samples: ", dataset[0].val_mask.sum().item())
print("# Test samples: ", dataset[0].test_mask.sum().item())
print("Undirected: ", dataset[0].is_undirected())
def main():
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
cora_dataset = get_data()
# my_net = GraphCNN(in_c=cora_dataset.num_features, hid_c=150, out_c=cora_dataset.num_classes)
my_net = OwnGCN(in_c=cora_dataset.num_features, hid_c=300, out_c=cora_dataset.num_classes)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
my_net = my_net.to(device)
data = cora_dataset[0].to(device)
optimizer = torch.optim.Adam(my_net.parameters(), lr=1e-2, weight_decay=1e-3)
# model train
my_net.train()
for epoch in range(100):
optimizer.zero_grad()
output = my_net(data)
loss = F.nll_loss(output[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()
_, prediction = output.max(dim=1)
valid_correct = prediction[data.val_mask].eq(data.y[data.val_mask]).sum().item()
valid_number = data.val_mask.sum().item()
valid_acc = valid_correct / valid_number
print("Epoch: {:03d}".format(epoch + 1), "Loss: {:.04f}".format(loss.item()),
"Valid Accuracy:: {:.4f}".format(valid_acc))
torch.save(my_net.state_dict(), "node_classify/best.pth") # 保存模型
# model test
my_net = OwnGCN(in_c=cora_dataset.num_features, hid_c=300, out_c=cora_dataset.num_classes) # 复原模型
my_net.load_state_dict(torch.load("node_classify/best.pth")) # 加载参数
my_net = my_net.to(device)
my_net.eval()
_, prediction = my_net(data).max(dim=1)
target = data.y
test_correct = prediction[data.test_mask].eq(target[data.test_mask]).sum().item()
test_number = data.test_mask.sum().item()
train_correct = prediction[data.train_mask].eq(target[data.train_mask]).sum().item()
train_number = data.train_mask.sum().item()
print("==" * 20)
print("Accuracy of Train Samples: {:.04f}".format(train_correct / train_number))
print("Accuracy of Test Samples: {:.04f}".format(test_correct / test_number))
def test_main():
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
cora_dataset = get_data()
data = cora_dataset[0].to(device)
my_net = OwnGCN(in_c=cora_dataset.num_features, hid_c=300, out_c=cora_dataset.num_classes) # 复原模型
my_net.load_state_dict(torch.load("node_classify/best.pth")) # 加载参数
my_net = my_net.to(device)
my_net.eval()
_, prediction = my_net(data).max(dim=1)
target = data.y
test_correct = prediction[data.test_mask].eq(target[data.test_mask]).sum().item()
test_number = data.test_mask.sum().item()
train_correct = prediction[data.train_mask].eq(target[data.train_mask]).sum().item()
train_number = data.train_mask.sum().item()
print("==" * 20)
print("Accuracy of Train Samples: {:.04f}".format(train_correct / train_number))
print("Accuracy of Test Samples: {:.04f}".format(test_correct / test_number))
if __name__ == '__main__':
main()
# test_main()
# dataset = get_data()
# analysis_data(dataset)