【论文笔记】ST-TR:Skeleton-based Action Recognition via Spatial and Temporal Transformer Networks
Skeleton-based Action Recognition via Spatial and Temporal Transformer Networks
基于骨骼通过时空变换网络的行为识别
未解决的问题:有效编码3D骨骼下面的潜在信息,尤其是从关节运动模式以及其相关性中提取有效信息时,诸如“拍手”之类的动作在人体骨骼中未链接的身体关节之间的相关性(例如,左手和右手)也被低估了。
时空变换网络ST-TR:
-
Transformer self-attention operator。基于双流的Transformer-based模型,空间时间维度都采用了self-attention对关节之间依赖关系建模
-
spatial self-attention(SSA):用于了解不同身体部位之间的帧内交互;动态建立骨骼关节之间的链接,代表人体各部分之间的关系,有条件地取决于动作,并且独立于自然的人体结构
-
temporal self-attention(TSA):用于对帧内相关性进行建模;研究关节随时间的动力学
使用改良的变换自注意运算符:

Sangwoo Cho, Muhammad Maqbool, Fei Liu, and Hassan
Foroosh. Self-attention network for skeleton-based human
action recognition. 2020. 2, 9, 10还提出了一个自我注意网络(SAN)来提取长期语义信息。但是,由于它专注于时间分割的片段,因此只能部分解决卷积的局 限性。
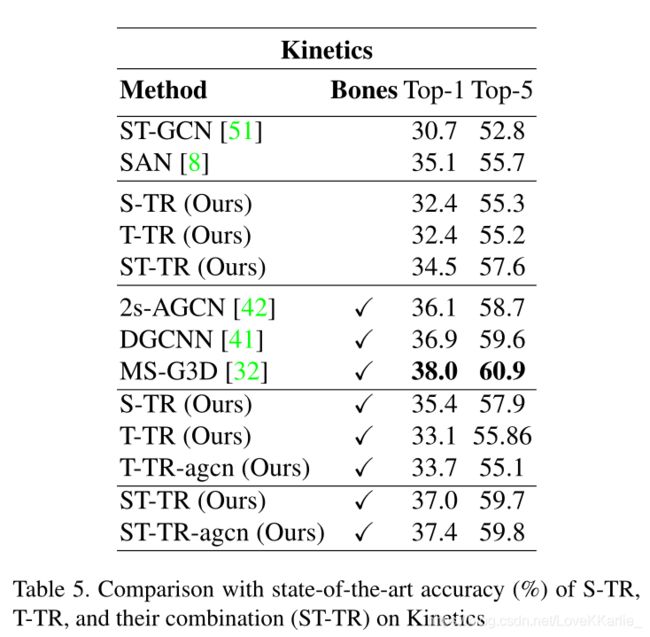
ST-GCN:
f o u t = ∑ k K s ( f i n A k ) W k {\bf f}_{out}=\sum_{k}^{K_s}({\bf f}_{in}{\bf A}_k){\bf W}_k fout=∑kKs(finAk)Wk
A k = D k − 1 2 ( A ~ k + I ) D k − 1 2 , D i i = ∑ k K s ( A ~ k i j + I i j ) {\bf A}_k={\bf D}_k^{-\frac{1}{2}}(\tilde{\bf A}_k+{\bf I}){\bf D}_k^{-\frac{1}{2}},D_{ii}=\sum_{k}^{K_s}(\tilde{\bf A}_k^{ij}+{\bf I}_{ij}) Ak=Dk−21(A~k+I)Dk−21,Dii=∑kKs(A~kij+Iij)
A-GCN:
f o u t = ∑ k K s f i n ( A k + B k + C k ) W k {\bf f}_{out}=\sum_{k}^{K_s}{\bf f}_{in}({\bf A}_k+{\bf B}_k+{\bf C}_k){\bf W}_k fout=∑kKsfin(Ak+Bk+Ck)Wk
Transformer Self-Attention:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention({\bf Q},{\bf K},{\bf V})=softmax(\frac {{\bf Q}{\bf K}^T}{\sqrt{d_k}}){\bf V} Attention(Q,K,V)=softmax(dkQKT)V
Spatial Self-Attention (SSA):
self-attention应用于每个帧,独立计算每个帧中没对关节之间的相关性来提取嵌入身体各个部分之间关系的低级特征

z i t = ∑ j s o f t m a x j ( α i j t d k ) v j t {\bf z}_i^t=\sum_j softmax_j(\frac {\alpha ^t_{ij}}{\sqrt{d_k}}){\bf v}^t_j zit=∑jsoftmaxj(dkαijt)vjt提取多次来应用多头注意力。
Temporal Self-Attention (TSA):
α t u v = q t u v ⋅ k u v , z t v = ∑ j s o f t m a x u ( α t u v d k ) v u v {\alpha ^v_{tu}}={\bf q}^v_{tu}·{\bf k}^v_u,{\bf z}_t^v=\sum_j softmax_u(\frac {\alpha ^v_{tu}}{\sqrt{d_k}}){\bf v}^v_u αtuv=qtuv⋅kuv,ztv=∑jsoftmaxu(dkαtuv)vuv

Two-Stream Spatial Temporal Transformer Network:
SSA在空间流(S-TR)上运行,而TSA在时间流(T-TR)上运行。
在两个流上,首先通过三层残差网络提取节点特征,其中每个层通过图卷积(GCN)处理空间维度上的输入,并通过标准2D卷积(TCN)处理时间维度上的输入。
然后将SSA和TSA应用于后续层中的S-TR和T-TR流,分别代替GCN和TCN特征提取模块。
子网的输出最终通过将它们的softmax输出得分相加而融合在一起,以获得最终的预测。

S-TR:
在空间流中,通过注意力集中在关节之间的空间关系的SSA模块在骨架级别应用了自我注意。SSA模块的输出被传递到带有时间维数(TCN)的内核的2D卷积模块,以提取时间相关的特征。
S − T R ( x ) = C o n v 2 D ( 1 × K t ) ( S S A ( x ) ) {\bf S-TR}(x)=Conv_{2D}(1×K_t)({\bf SSA}(x)) S−TR(x)=Conv2D(1×Kt)(SSA(x))
遵循原始的Transformer结构,通过BN对输入进行预标准化,并使用跳过连接将输入与SSA模块的输出求和
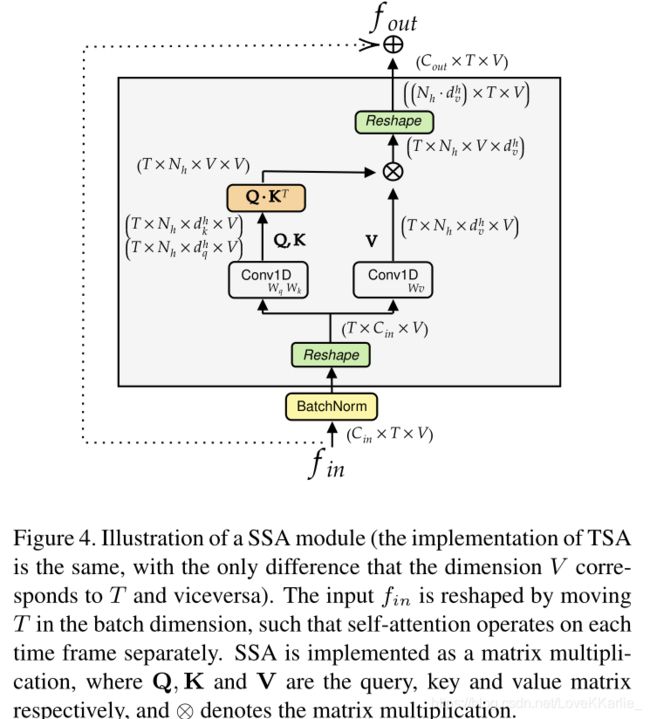
T-TR:
在每个TTR层内部,标准图卷积子模块之后是建议的时间自注意模块: T − T R ( x ) = T S A ( G C N ( x ) ) {\bf T-TR}(x)={\bf TSA}(GCN(x)) T−TR(x)=TSA(GCN(x))。TSA在沿所有时间维度(例如,所有左脚或所有右手)链接同一关节的图形上进行操作。