如何封锁您的(或打开别人的) Java 代码
无论是修改许多网上源码库中的代码,还是调用常见的操作系统例行程序,您免不了要花一些时间去琢磨您没有编写过的代码,而且您还 可能没有这些代码的源文件。在开始调试代码时,您需要有一个好的 Java 反编译器,并了解正确使用它的技术。同时,您还要知道如何保护您自己的代码不被窥视。为此,您还需了解有关代码模糊处理的问题。在这篇有关打开和封锁 Java 代码的初学者指南中, Greg Travis 使用 Mocha、HoseMocha、jmangle 和 JODE 等流行工具中的范例,来循序渐进地教你有关反汇编、反编译和 Java 代码模糊处理的基础知识。
没有比发现一个错误,却没有源代码就不能修改更令人沮丧的了。正是这个原因导致了 Java 反编译器的出现,它可以把编译后的字节码完全转回成源代码。尽管代码反编译器不只是针对 Java 语言,但它从来没有象在 Java 开发人员中那样被公开地或广泛地使用。
与 反编译针锋相对的是模糊处理。假设反编译人员能很容易从编译后的代码中设法得到源代码,那么要保护您的代码和有价值的技术秘密就不是那么简单了。随着 Java 反编译器的普遍使用, Java 模糊处理器也同样被普及,它的作用就好像放一块烟幕在您的代码前面。反编译和模糊处理在商业开发领域中引起了一场争论 -- 争论中的大部分都集中在了 Java 语言上。
在本文中,我将让您了解代码反编译和模糊处理的具体过程,讨论在这两种技术之后的理论问题,同时简要地谈到它们在商业编程领域中所引起的争论。我还将介绍一些比较有名的反编译器和模糊处理器(有商业的,也有开放源代码的),并随着文章的深入使用它们来创建一些实例。
反 编译是一个将目标代码转换成源代码的过程。这应该很清楚了,因为编译是一个将源代码转换成目标代码的过程。但什么是目标代码呢?大体上的定义是:目标代码 是一种用语言表示的代码,这种语言能通过实机或虚拟机直接执行。对于象 C 这样的语言,目标代码通常运行在硬件 CPU 上,而 Java 目标代码通常运行在虚拟机上。
正 如以上所描述的,反编译听上去比较简单,但它实际上是非常困难的 -- 从本质上说,它所包含的是根据小规模、低层次的行为来推断大规模、高层次的行为。为了对此有个直观的理解,我们把一个计算机程序看作是一个复杂的公司组织 结构。高层管理人员向他们的下属下达类似“最大程度地提高技术生产能力”的命令,下属们再把这些命令转变成更具体的行动,例如安装新的 XML 数据库。
作为该公司的新雇员,您可能会问下属他或她在做些什么,并得到回答,“我在安装新的 XML 数据库。”从这句话中,您不可能推断出其最终目的是最大程度地提高技术生产能力。毕竟,最终目标不尽相同,例如可能是分离供应链或累积消费者的数据。
然而,如果属于好奇心特强的那类人,您可能会再多问几个问题,并让公司中不同级别的下属回答您的问题。最后,当把所有的答案汇总后,您可能会猜到企业更大的目标是最大程度地提高技术生产能力。
如果您把计算机程序的工作方式看作类似一个公司的组织结构,那么对于为什么反编译代码不是无关紧要的,以上的这个比方就会给你一个直接的感受。从比较理论化的角度来看,这儿要引用在该领域的杰出研究员 Cristina Cifuentes 对反编译过程的描述:
任 何一个二进制改造工程都需要对存储在二进制文件中的代码进行反汇编。从理论上说,分离 von Neumann 上的数据和代码就好象停机问题,因此完全的静态翻译是不可能的。然而,实际上可以使用不同技术来提高可被静态翻译的代码的所占比例,或者采取可在运行中被 使用的动态翻译技术。 --"Binary Reengineering of Distributed Object Technology"(请参阅 参考资料)
把目标代码转换成源代码并不是反编译时碰到的唯一问题。一个 Java 类文件潜在包含了一些不同类型的信息。知道类文件中可能包含了哪类信息对于了解您如何利用该信息以及对于信息作何种处理都是很重要的。这其实就是 Java 反汇编器所要做的。
Java 类文件的真正二进制格式不是很重要。重要的是知道在那些字节中包含了哪些不同种类的信息。到了这一步,我们将利用多数 JDK 都带有的一个工具 -- javap。 javap 是一个 Java 代码反汇编器,它和反编译器是不同的。反汇编器把机器可读格式的目标代码(如清单 1 所示)转换成人们可读的代码(如清单 2 所示)。
0000000 feca beba 0300 2d00 4200 0008 081f 3400 |
Local variables for method void priv(int) |
请注意,清单 2 所示的并不是源代码。该清单的第一部分列出了方法的局部变量;第二部分是汇编代码,它也是人们可读的目标代码。
javap 被用来反汇编或解包一个类文件。这里简要列出了可以通过使用 javap 进行反汇编的 Java 类文件所包含的信息:
- 成员变量。每个类文件中包含了对应于该类每个数据成员的所有名称信息和类型信息。
- 经过反汇编后的方法。类的每一个方法都是由一串虚拟机指令来表示的,并附带它的类型签名。
- 行号。每个方法中的每个节被映射到源代码行,在可能的情况下,源代码行来生成节。这使得实时系统和调试器能够为在运行状态的程序提供堆栈跟踪。
- 局部变量名一旦方法被编译了,这个方法的局部变量就不太需要名称了,但是能通过对 javac 编译器使用
-g选项来包含它们。这也使得实时系统和调试器能帮助您。
既然对 Java 类文件的内部情况已有所了解,让我们看一下如何能转换这些信息来达到我们的目的。
从概念上讲,反编译器使用起来非常简单。他就是把编译器逆过来用:你给它 .class 文件,它还给你一个源代码文件。
一些比较新的反编译器有精致的图形界面。但在一开始所举的例子中,我们将使用的是 Mocha,它是第一个公开的可利用的反编译器。在本文的最后,我会讨论一下在 GPL 下一个较新的反编译器。(请参阅 参考资料,下载 Mocha 并获取 Java 反编译器的清单。)
让我们假设在目录中有一个名为 Foo.class 的类文件。用 Mocha 对它进行反编译非常简单,只要键入以下命令:
$ java mocha.Decompiler Foo.class |
这会生成一个新的名为 Foo.mocha 的文件(Mocha 使用 Foo.mocha 这个名字以避免覆盖原文件的源代码)。这个新文件就是 Java 的源文件,并且假设一切顺利的话,您现在就能正常地编译它。只需把它重命名为 Foo.java 就可以开始了。
但是这儿有个问题:如果在一些您已经有所改动的代码上运行 Mocha,您会注意到它生成的代码和源代码不是完全一样的。我举个例子,这样您能明白我的意思。清单 3 所示的原始源代码是来自一个名为 Foo.java 的测试程序。
private int member = 10; |
以下是 Mocha 生成的代码
private int member; |
这两个代码片段的成员变量 member 被初始化为 10 的位置不同。在原始源代码中,它在与声明的同一行中被表示为一个初始值,而在被反编译后的源代码中,它在一个构造符中被表示为一条赋值语句。反编译后的代 码告诉我们一些有关源代码被编译的方法;即它的初始值是作为在构造符中的赋值来被编译的。通过观察其反编译后的输出结果,您能了解到不少 Java 编译器的工作方法。
虽然 Mocha 的确可以反汇编您的目标代码,但它不会总是成功的。由于困难重重,没有一个反编译器能够准确无误地翻译出源代码,而且每个反编译器处理它们在翻译过程中的 漏洞的方式也不同。举例来说,Mocha 有时在输出准确的循环构造的结构方面有一些问题。如果真的这样,它会在最终输出中使用伪 goto 语句,如清单 5 所示。
if (i1 == i3) goto 214 else 138; |
撇开 Mocha 的问题不谈,反编译器在通常情况下还是能比较准确地翻译出源代码。一旦知道了某一反编译器的弱点,您可以手工分析和转换反编译后的代码,以使它们能较准确 地符合原始源代码。随着反编译器正变得越来越出色,我们又碰到了另外一个问题:如果您不想让任何人能反编译您的代码,那该怎么办呢?
虽然,大部分的代码反编译是完全正大光明的,但事实是一个优秀的反汇编器是软件侵权的必需工具之一。正因如此,尤其对于在商业和不开放源代码领域中的开发人员来说,便宜的(或免费的) Java 代码反汇编工具的存在是一个严重的问题。
就 语言本身而言, 由于其相对简单的 Java 虚拟机(与真实的微处理器相比)和其写得很规范的字节码格式, Java 代码非常容易反汇编。而这随着 Java 语言在 Web 开发平台上的日益普及,已经在商业开发领域引起了很多争议。自从 Mocha 于 1996 年首次发布以来,一些在保护它们的源代码方面有过投资的公司和个人一直在为 Java 反编译器大吵大闹。
实际上,当 Mocha 第一次发布时,它的作者 Hanpeter van Vliet 曾被一些公司的诉讼威胁过(请参阅 参考资料)。起初,他把反编译器从他的网站上移去,但是他后来以 Crema 的形式提供了一个更好的解决方案。Crema 是一个 Java 模糊处理器,它完全对立于 Mocha。
自 Crema 发布以来,许多 Java 模糊处理器开始出现,其中一些是商业的,也有一些是开放源代码的。正如您看到的那样,一个好的 Java 模糊处理器可以在很大程度上保护您的 Java 代码。
代码模糊处理字面上的意思就是模糊处理您代码的行为。Java 模糊处理器用不易察觉的方法改变程序,以致于它的 运行对 JVM 来说是一模一样的,但它使得试图理解程序的人更加迷惑了。
让 我们看一下当反汇编器遇到经过模糊处理后的代码会发生什么情况。清单 6 显示了 Mocha 在尝试反汇编被一种名为 jmangle 的工具模糊处理的 Java 代码后的结果。请注意以下的一小段程序和我们在前面清单中使用的是相同的,尽管乍一看,您肯定不会这么认为。
public Foo() |
象 jmangle 这样的模糊处理器把许多变量名和方法名(有时甚至是类名和包的名称)转换成没有意义的字符串。这样就使得人们难以阅读程序,但对于 JVM 来说,其在本质上和原来的程序是一样的。
所有的模糊处理器都要使标记变得没有意义,但他们所做的不仅仅是这些。Crema 之所以臭名昭著是因为它用了许多卑鄙的手段来阻止反汇编,并且有许多在已经出现的模糊处理器中,纷纷仿效它。
一种常用的模糊处理代码的方法是用一个非法的字符串来替代类文件中的标记,这比使用没有意义的字符串更进了一步。替代的有可能是一个关键字,例如 private ,或者甚至是象 *** 这样没有意义的标记。一些虚拟机 -- 尤其在浏览器中 -- 对这些古怪的用法不会作出合法的反应。从技术上说,一个象 = 这样的变量与 Java 的规范是相反的;一些虚拟机可以忽略它,而另一些不可以这样。
按字面意思,Crema 使用的另一个计策就是炸弹。Crema 具有完全关闭 Mocha 的能力。它在编译后的代码中添加一个小“炸弹”,导致 Mocha 在试图反编译代码时崩溃。
可惜,Crema 已经没有了,但有一种名为 HoseMocha 的工具是专门为关闭 Mocha 而设计的。为了了解 HoseMocha 是如何工作的,我们将使用 javap,这个值得信赖的反汇编器。清单 7 所示的是 HoseMocha 放置炸弹前的代码。
Method void main(java.lang.String[]) |
以下是 HoseMocha 处理后的代码。
Method void main(java.lang.String[]) |
您看到那颗炸弹吗?请注意现在这个程序在返回后面有 一条 pop 语句。等一下 -- 一个函数在返回之后还能做什么吗?很显然,它不能,而这就是关键所在。在返回语句后放一条指令确保了它不会被执行。您这儿所见的是根本不可能被反汇编的。 因为它没有对应任何可能的 Java 源代码,所以也就没有任何意义。
但为什么这一个小小的障碍就能导致 Mocha 崩溃呢? Mocha 可以只是简单地忽略它,或发一条警告信息并继续下去。尽管 Mocha 对于此类炸弹的脆弱性可以被认为是一个程序错误,但更有可能的是 van Vliet 为了回应对 Mocha 的攻击而故意设置的。
到此为止,我们已经了解了较老的反汇编工具和模糊处理工具 -- 虽然有点过时,但还是比较出色的。但是,类似工具在这几年已经变得更加成熟,尤其在图形界面方面更是如此。在本文的最后,我们看一下一个较新的反汇编器,仅仅让您有个大致的概念。
在过去的五年中,不仅仅是反汇编和模糊处理的技术越来越复杂,而且这些工具的界面也更加华丽。在最近出现的反汇编器中,有几个能让您浏览 .class 文件的目录并且只要单击一下,就能对它们进行反汇编。
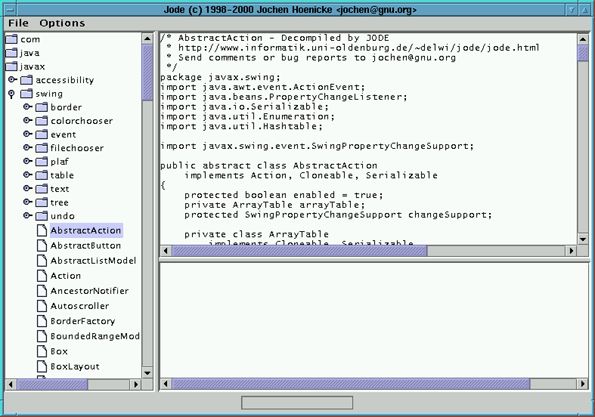
JODE (Java 优化和反编译环境)就是这样一个程序。在命令行中键入 .jar 文件的名称, JODE 就会允许您图形化地浏览它的类,并自动反汇编每个类以让您查看。这特别有助于通过 Java SDK 提供的库来查找源代码。简单地键入以下命令:
$ java jode.swingui.Main --classpath [path to your Java SDK]/jre/lib/rt.jar |
您就会得到如图 1 所示的对文件的完整翻译。
请参阅 参考资料,获取更有用的工具的清单。
无论选择使用象 Mocha 或 HoseMocha 这样的经典工具,还是乐于亲自研究一下更新的工具,您都应把这篇文章作为您学习 Java 反汇编和模糊处理的起点。在此,请浏览一下在 参考资料中所提供的许多链接,试着使用其中的一些工具,并准备以后不断磨练自己的技术。尽管有许多争议,反汇编和模糊处理的技术如今依然存在,并且在今后的几年中只会变得更加成熟和完善。
- 您可以参阅本文在 developerWorks 全球站点上的 英文原文.
- 虽然 Mocha已经过时,但使用起来要比较有趣,而且偶尔会有一些用处。
- 正如在它之前的 Crema, HoseMocha制造一个阻止 Mocha 工作的炸弹。
- Borland 的 JBuilder据说是基于原来 Crema 的代码。
- 请查看 jmangle。
- SourceForge 如今拥有 JODE,它可以在 GPL 下获得。
- WingDis是另一个流行的商业反编译器。
- Blackdown 列出了许多在 Linux 上的 Java 开发工具,包括 JAD、它被认为是“最快的 Java 反汇编器”。
- Zelix KlassMaster是一个作为模糊处理器工作的商业类文件查看工具。
- Marc Meurrens 的 Java 代码工程是一个出色的网站,涵盖了汇编器、反汇编器、模糊处理器及相关信息。
- 反汇编和反汇编器是另一个包罗万象的页面,有许多软件和研究论文的有用链接。
- Cristina Cifuentes维护着 反汇编页面,有许多有关反汇编的理论和实际工作的信息,包括一个名为
dcc的 C 反汇编器。 - 已故的 Maurice Halstead 被许多人认为是反汇编之父。请阅读有关他从 1960 年至 1976 年领导的 反汇编项目的信息。
- 请参阅“ Java 反编译器比较”(JavaWorld,1997 年 7 月),这里有对 Java 反汇编器的大范围回顾。
- 请阅读 Hanpeter van Vliet 的 原始反汇编器宣言(Web Techniques,1997 年 9 月)。
- IBM 苏黎世研究实验室在安全性和 Java 加密技术上投入了大量资源。
- 请阅读 IBM 是如何研究 Java 安全性和分布式目标系统。
- 在 “ 让您的软件运行:模糊安全性” (developerWorks,2000 年 10 月)中,作者 Gary McGraw 和 John Viega 讨论了试图在运行软件时实现保密。
- 请不要错过 developerWorks 在这重要领域的 安全性专题。
- McGraw 和 Felten 的经典著作 Securing Java, 2nd Edition (John Wiley & Sons, 1999)的第 6 章有关于 Java 反汇编器的更多信息。
| Greg Travis 是一名居住在纽约的自由程序员。他对计算机的兴趣可以追溯到 "The Bionic Woman" 中的这样一段情节,Jamie 试图逃离一幢其灯光和门都被邪恶的人工智能所控制的大楼,而且人工智能还通过扩音器嘲弄她。Greg 坚定地认为当计算机程序工作时,它是完全一致的。可通过 [email protected]联系 Greg。 |
||