机器学习实践(五)——Logistic回归
一、概念
logistic回归又称logistic回归分析,是一种广义的线性回归分析模型,常用于数据挖掘,疾病自动诊断,经济预测等领域。例如,探讨引发疾病的危险因素,并根据危险因素预测疾病发生的概率等。
二、原理
1.梯度下降法
梯度下降法(gradient descent)是一种常用的一阶(first-order)优化方法,是求解无约束优化问题最简单、最经典的方法之一。我们来考虑一个无约束化问题![]() ,其中
,其中 为连续可微函数,如果我们能构造一个序列
为连续可微函数,如果我们能构造一个序列![]() ,并能够满足
,并能够满足![]() ,那么我们就能够不断执行该过程即可收敛到局部极小点,可参考下图:
,那么我们就能够不断执行该过程即可收敛到局部极小点,可参考下图:
那么问题就是如何找到下一个点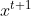 ,并保证
,并保证![]() 呢?假设我们当前的函数的形式是上图的形状,现在我们随机找了一个初始的点
呢?假设我们当前的函数的形式是上图的形状,现在我们随机找了一个初始的点 ,对于一元函数来说,函数值只会随着
,对于一元函数来说,函数值只会随着 的变化而变化,那么我们就设计下一个 是从上一个
的变化而变化,那么我们就设计下一个 是从上一个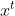 沿着某一方向走一小步
沿着某一方向走一小步 得到的。此处的关键问题就是:这一小步的方向是朝向哪里?
得到的。此处的关键问题就是:这一小步的方向是朝向哪里?
对于一元函数来说,是会存在两个方向:要么是正方向![]() ,要么是负方向
,要么是负方向![]() ,如何选择每一步的方向,就需要用到闻名的泰勒公式,先看一下这个泰勒展式:
,如何选择每一步的方向,就需要用到闻名的泰勒公式,先看一下这个泰勒展式:![]()
左边就是当前的移动一小步之后的下一个点位,它近似等于右边。前面我们说了关键问题是找到一个方向,使得![]() ,那么根据上面的泰勒展式,显然我们需要保证:
,那么根据上面的泰勒展式,显然我们需要保证:![]() ,可选择令:
,可选择令:![]() ,其中步长
,其中步长 是一个较小的正数,从而:
是一个较小的正数,从而:![]() .
.
由于任何不为0的数的平方均大于0,因此保证了![]() ,从而设定:
,从而设定:![]() ,则可保证:
,则可保证:![]() ,那么更新的计算方式就很简单了,可按如下公式更新:
,那么更新的计算方式就很简单了,可按如下公式更新:![]() ,这就是所谓的沿负梯度方向走一小步。
,这就是所谓的沿负梯度方向走一小步。
到此为止,就是梯度下降的全部原理。
2.Sigmoid函数的引入
Sigmoid函数也叫Logistic函数,用于隐层神经元输出,取值范围为(0,1),它可以将一个实数映射到(0,1)的区间,可以用来做二分类。在特征相差比较复杂或是相差不是特别大时效果比较好。
Sigmoid函数由下列公式定义:
![]()
其对的导数可以用自身表示:
![]()
Sigmoid函数的图形如S曲线:

3.代价函数
在线性回归中,我们使用茶平方和作为代价函数,公式为:
但是在逻辑回归中,差平方和公式就不适用了,原因如下:
- 由于Sigmoid函数在自变量很大的时候,图形趋近于一条直线,表明其导数值趋近于0。如果使用差平方和公式最为代价函数,我们就需要求Sigmoid函数的偏导数,这就会导致在进行参数更新时,参数更新速度会变得非常慢。
- 而使用交叉熵损失函数作为代价函数,不仅在求偏导中能够将Sigmoid函数给消除掉,而且该函数是凸函数,只有一个最优解。带有Sigmoid函数的差平方和公式不是一个凸函数,会有很多局部最优解。
- 由信息论中KL散度推导出来,更能衡量数据分布与数据在模型中分布的不同。
4.参数更新公式推导
Sigmoid公式[1]为:![]()
使用交叉熵作为损失函数,交叉熵的公式[2]为:![]()
损失函数公式[3]为:![J(\theta )=-\frac{1}{m}\sum_{i=1}^{m}[y^{(i)}log(G(x))+(1-y^{(i)})log(1-G(x))]](http://img.e-com-net.com/image/info8/4643d10eb05241fabe17c1ec735fc492.gif)
梯度下降参数更新公式[4]为:![]()
将公式[1]、[2]、[3]代入公式[4]中,求得最终结果为:![\theta _{j}=\theta _{j}-\alpha \frac{1}{m}\sum_{i=1}^{m}[G(x^{(i)})-y^{(i)}]*x_{j}^{(i)}](http://img.e-com-net.com/image/info8/624122f54c4845f7995b2fc31db914b4.gif)
三、实现
Logistic实现的一般步骤为:
1. 收集数据:采用任意方法收集数据
2. 准备数据:由于需要进行距离计算,因此要求数据类型为数值型。另外,结构化数据格式则最佳。
3. 分析数据:画出决策边界。
4. 训练算法:找到最佳的分类回归系数。
5. 测试算法:一旦训练步骤完成,分类将会很快。
6. 使用算法:首先,我们需要输入一些数据,并将其转换成对应的结构化数值;接着,基于训练好的回归系数就可以对这些数值进行简单的回归计算,判定它们属于哪个类别;在这之后,我们就可以在输出的类别上做一些其他分析工作。
1.数据集介绍
此次实践使用Logistic回归实现简单数据集的分类问题,因此需准备一个简单的数据集,并保存为Data.txt 文本文件

2.解析数据
将文本文件中的数据集划分,实现代码如下:
#解析数据
def loadDataSet(file_name):
'''
Desc:
加载并解析数据
Args:
file_name -- 要解析的文件路径
Returns:
dataMat -- 原始数据的特征
labelMat -- 原始数据的标签,也就是每条样本对应的类别。即目标向量
'''
# dataMat为原始数据, labelMat为原始数据的标签
dataMat = []
labelMat = []
fr = open(file_name)
for line in fr.readlines():
lineArr = line.strip().split()
# 为了方便计算,我们将 X0 的值设为 1.0 ,也就是在每一行的开头添加一个 1.0 作为 X0
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
labelMat.append(int(lineArr[2]))
return dataMat, labelMat测试划分结果:
FileName="C:/Users/86188/Desktop/Logistic/Data.txt"
DataMat,LabelMat=loadDataSet(FileName)
print(DataMat)
print(LabelMat)
3.Logistic函数
# sigmoid阶跃函数
def sigmoid(inX):
# return 1.0 / (1 + exp(-inX))
return 1.0/(1+np.exp(-inX))
# Logistic 回归梯度上升优化算法
def gradAscent(dataMatIn, classLabels):
#用mat函数将列表转换成numpy矩阵
dataMatrix = np.mat(dataMatIn)
#用mat函数将列表转换成numpy矩阵,并进行转置
labelMat = np.mat(classLabels).transpose()
#返回dataMatrix的大小。m为行数,n为列数。
m,n = np.shape(dataMatrix)
#移动步长,也就是学习速率,控制更新的幅度。
alpha = 0.001
#最大迭代次数
maxCycles = 500
# weights 代表回归系数, 此处的 ones((n,1)) 创建一个长度和特征数相同的矩阵,其中的数全部都是 1
weights = np.ones((n,1))
for k in range(maxCycles):
# m*3 的矩阵 * 3*1 的矩阵 = m*1的矩阵
h = sigmoid(dataMatrix*weights)
# labelMat是实际值,labelMat - 是两个向量相减
error = (labelMat - h)
# 0.001* (3*m)*(m*1) 表示在每一个列上的一个误差情况,最后得出 x1,x2,xn的系数的偏移量
# 矩阵乘法,最后得到回归系数
weights = weights + alpha * dataMatrix.transpose() * error
return np.array(weights)# 画出数据集和 Logistic 回归最佳拟合直线的函数
def plotBestFit(dataArr, labelMat, weights):
n = np.shape(dataArr)[0]
xcord1 = []; ycord1 = []
xcord2 = []; ycord2 = []
for i in range(n):
if int(labelMat[i])== 1:
xcord1.append(dataArr[i][1]); ycord1.append(dataArr[i][2])
else:
xcord2.append(dataArr[i][1]); ycord2.append(dataArr[i][2])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s=30, c='red', marker='s')
ax.scatter(xcord2, ycord2, s=30, c='green')
x = np.arange(-3.0, 3.0, 0.1)
y = (-weights[0]-weights[1]*x)/weights[2]
ax.plot(x, y)
plt.xlabel('X'); plt.ylabel('Y')
plt.show()4.测试算法
#测试算法: 使用 Logistic 回归进行分类
def testLR():
dataMat, labelMat = loadDataSet("C:/Users/86188/Desktop/Logistic/Data.txt")
dataArr = np.array(dataMat)
weights = gradAscent(dataArr, labelMat)
plotBestFit(dataArr, labelMat, weights)
运行后的结果如图:

四、总结
Logistic回归是二分类任务中最常用的机器学习算法之一。它的设计思路简单,易于实现,可以用作性能基准,且在很多任务中都表现很好。
Logistic回归是一种被人们广泛使用的算法,因为它非常高效,不需要太大的计算量,又通俗易懂,不需要缩放输入特征,不需要任何调整,且很容易调整,并且输出校准好的预测概率。它还非常容易实现,且训练起来很高效,可在研究中用回归模型作为基准,也可用它来衡量其他更复杂的算法的性能。但是,Logistic回归并非最强大的算法之一,它并不能用于解决非线性问题,它的决策面是线性的,并且高度依赖正确的数据表示,它同时也以其过拟合而闻名。