机器学习算法基础——Logistic回归、K-means
机器学习算法基础——Logistic回归、K-means
- 分类算法——逻辑回归
-
- 逻辑回归
- sklearn逻辑回归API
- LogisticRegression回归案例
- LogisticRegression总结
- 生成模型和判别模型
- 非监督学习(unsupervised learning) K—means
-
- k-means步骤
- k-means API
- k-means对Instacart Market用户聚类
- Kmeans性能评估指标
- Kmeans性能评估指标API
- Kmeans总结
分类算法——逻辑回归
逻辑回归
1.逻辑回归是解决二分类问题的利器。
h ( ω ) = ω 0 + ω 1 x 1 + ω 2 x 2 + . . . = ω T x h(\omega) = \omega_0+\omega_1x_1+\omega_2x_2+...=\omega^Tx h(ω)=ω0+ω1x1+ω2x2+...=ωTx
2.Sigmoid函数
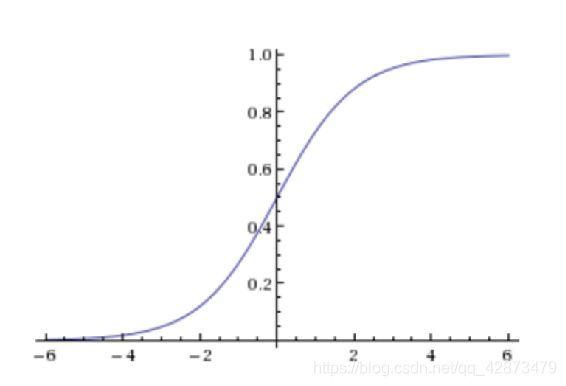
逻辑回归公式:
h θ ( x ) = g ( θ T x ) = 1 1 + e − θ T x h_{\theta}(x)=g(\theta^Tx)=\frac{1}{1+e^{-\theta^T}x} hθ(x)=g(θTx)=1+e−θTx1
g ( z ) = 1 1 + e − z g(z)=\frac{1}{1+e^{-z}} g(z)=1+e−z1
输出:[0,1]取件的概率值,默认0.5作为阈值。z为回归的结果,g(z)为sigmoid函数。
3.逻辑回归的损失函数、优化
与线性回归原理相同,但由于是分类问题,损失函数不一样,只能通过梯度下降求解。
(1)对数似然损失函数:
 (2)完整的损失函数
(2)完整的损失函数
 cost损失的值越小,那么预测的类别准确度更高。
cost损失的值越小,那么预测的类别准确度更高。
4.局部最低点
(1)损失函数:
均方误差(不存在多个局部最低点),只有一个最小值。
对数似然损失:存在多个局部最小值。
(2)解决方法
多次随机初始化,多次比较最小值结果。
在求解过程中,调整学习率。
sklearn逻辑回归API
类: sklearn.linear_model.LogisticRegression
sklearn.linear_model.LogisticRegression(penalty=‘l2’, C = 1.0) 自带了正则化
Logistic回归分类器
coef_:回归系数
LogisticRegression回归案例
1.良/恶性乳腺癌肿数据
(1)原始数据的下载地址:
https://archive.ics.uci.edu/ml/machine-learning-databases/
(2)数据描述
a.699条样本,共11列数据,第一列用语检索的id,后9列分别是与肿瘤相关的医学特征,最后一列表示肿瘤类型的数值。
b.包含16个缺失值,用”?”标出。
2.良/恶性乳腺癌肿分类流程
(1)网上获取数据(工具pandas)
(2)数据缺失值处理、标准化
(3)LogisticRegression估计器流程
PS:哪个类别少,将哪一个类别作为正例去判定概率。
3.案例实现
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import mean_squared_error,classification_report
def logistic():
# 逻辑回归做二分类进行癌症预测(根据细胞的属性特征)
column = ['Sample code number','Clump Thickness', 'Uniformity of Cell Size','Uniformity of Cell Shape','Marginal Adhesion',
'Single Epithelial Cell Size','Bare Nuclei','Bland Chromatin','Normal Nucleoli','Mitoses','Class']
data = pd.read_csv('file:///D:/%E7%81%AB%E7%8B%90%E4%B8%8B%E8%BD%BD/breast-cancer-wisconsin.data',names=column)
print(data)
#缺失值处理
data = data.replace(to_replace='?',value = np.nan)
data = data.dropna()
#进行数据的分割
x_train,x_test,y_train,y_test = train_test_split(data[column[1:10]],data[column[10]],test_size=0.25)
#进行标准化处理
std = StandardScaler()
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
#进行逻辑回归预测
lg = LogisticRegression(C=1.0)
lg.fit(x_train,y_train) #用对数似然损失去训练优化w值
y_predict = lg.predict(x_test)
print('lg.coef_')
print('准确率:',lg.score(x_test,y_test))
print('召回率:',classification_report(y_test,y_predict,labels=[2,4],target_names = ['良性','恶性']))
return None
if __name__ == '__main__':
logistic()
LogisticRegression总结
1.应用:广告点击率预测、是否患病、金融诈骗、是否为虚假账号、电商购物搭配推荐
2.优点:适合需要得到一个分类概率的场景,简单,速度快
3.缺点:不好处理多分类问题;当特征空间很大时,逻辑回归的性能不是很好(看硬件能力)
|
|
优化 | |
|---|---|---|
| 线性回归 |
|
正规方程、梯度下降学习率 |
| 逻辑回归 |
|
梯度下降 |
生成模型和判别模型
|
|
朴素贝叶斯:生成模型 | |
|---|---|---|
|
|
|
多分类问题 |
|
|
|
文本分类 |
|
|
|
无 |
|
|
得出的结果都有概率解释 | 得出的结果都有概率解释 |
1.判别方法:由数据直接学习决策函数Y=f(X)或者条件概率分布P(Y|X)作为预测的模型,即判别模型。基本思想是有限样本条件下建立判别函数,不考虑样本的产生模型,直接研究预测模型。典型的判别模型包括k近邻,感知机,决策树,支持向量机等。
2.生成方法:由数据学习联合概率密度分布P(X,Y),然后求出条件概率分布P(Y|X)作为预测的模型,即生成模型:P(Y|X)= P(X,Y)/ P(X)。考虑先验概率,典型的生成模型有朴素贝叶斯、隐马尔可夫。
非监督学习(unsupervised learning) K—means
k-means步骤
1、随机设置K个特征空间内的点作为初始的聚类中心。
2、对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别。
3、接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平均值)。
4、如果计算得出的新中心点与原中心点一样,那么结束,否则重新进行第二步过程。
k-means API
类:sklearn.cluster.KMeans
sklearn.cluster.KMeans(n_clusters=8,init=‘k-means++’)
k-means聚类
n_clusters:开始的聚类中心数量
init:初始化方法,默认为’k-means ++’
labels_:默认标记的类型,可以和真实值比较(不是值比较)
k-means对Instacart Market用户聚类
1、降维之后的数据
2、k-means聚类
3、聚类结果显示
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
#x为之前的合并好的用户-购买物品类别数据
#减少样本数量
x = data[:500]
x.shape
#假定用户一共分为四个类别
km = KMeans(n_clusters=4)
km.fit(x)
predict = km.predict(x)
predict
#显示聚类的结果
plt.figure(figsize=(10,10))
#建立四个颜色的列表
colored = ['orange','green','purple','pink']
color = [colored[i] for i in predict]
plt.scatter[x[:,1],x[:,20],color = color]
plt.xlabel = ['1']
plt.ylabel = ['20']
plt.show()
Kmeans性能评估指标
轮廓系数:对于每一个样本都有对应的轮廓系数
s c i = b i − a i m a x ( b i , a i ) sc_i=\frac{b_i-a_i}{max(b_i,a_i)} sci=max(bi,ai)bi−ai
 1.计算蓝1到自身类别点的距离 a i a_i ai
1.计算蓝1到自身类别点的距离 a i a_i ai
2.计算蓝1分别到红色类别、绿色类别所有点的距离,求出平均值b1,b2,取其中最小的值当做 b i b_i bi。
轮廓系数在 [-1,1] 之间,最好是1,最差-1,大于0.1认为效果可以。
【评估】
(1)如果 s c i sc_i sci小于0,说明 a i a_i ai的平均距离大于最近的其他族,聚类效果不好。
(2)如果 s c i sc_i sci越大,说明 a i a_i ai的平均距离小于最近的其他族,聚类效果好。
(3)轮廓系数的值趋近于1代表内聚度和分离度都相对较优。
Kmeans性能评估指标API
类:sklearn.metrics.silhouette_score
sklearn.metrics.silhouette_score(X, labels)
计算所有样本的平均轮廓系数
X:特征值
labels:被聚类标记的目标值
from sklearn.metrics import silhouette_score
#评判聚类效果,轮廓系数
silhouette_score(x,predict)
Kmeans总结
1.特点分析:采用迭代式算法,直观易懂并且非常实用
2.缺点:容易收敛到局部最优解(多次聚类)
需要预先设定簇的数量(k-means++解决)
注:聚类一般做在分类之前。