星宸科技IC2020笔试
题目
1.
以下程序的功能是求100-999之间的水仙花数(水仙花数是指一个三位数的各位数字的立方和是这个数本身,如:153=1^3+5^3+3^3).请补充【?】的代码
#includeusing namespace std; int fun (int n) { int i, j, k, m; m = n; // 1 for (i = 1; i < 4; i++) { //2 m = (m - j) /10; k = k + j * j * j; } if (k == n) //3 else { return 0; } } void main() { int i; for (i = 100; i < 1000; i++) { // 4 if ( /*4*/ == 1) cout << i << "is ok" << endl; } } /*-------------------solution--------------- 1. k = 0; 2. j = m % 10; 3. return 1; 4. fun(i) */
2
请基于图示Path回答下面时序相关问题,其中
时钟周期Period:T,
组合逻辑delay:Comb_D
A.FF_A clock latency:CLK _D_A
B.FF_B clock latency:CLK_D_B
C.FF_A setup time/hold timing/CK->Q delay分别是A_setup/A_hold/A_CK2Q
D.FF_B setup time/hold timing/CK->Q delay分别是B_setup/B_hold/B_CK2Q
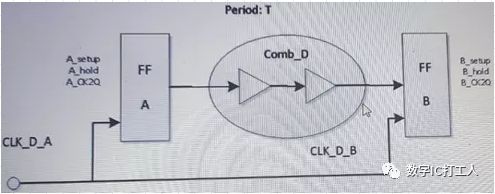
Q1:如果报从FF_A到FF_B path的setup违例,请问是违反FF_A的setup还是FF_B的setup?(+2)如果报从FF_A到FF_B path的hold违例请问是违反FF_A的hold还是FF_B的hold?(+2)
违反FF_B setup 违反FF_B setup
Q2请写出FF_A到FF_B path setup检查需满足period的条件公式?(+4)
setup check: A_CK2Q + Comb_D + B_setup + CLK_D_A <= T + CLK_D_B
Q3.请写出FF_A到FF_B path hold检查需满足的条件公式?(+4)
hold check: A_CK2Q + Comb_D + CLK_D_A >= B_hold + CLK_D_B
Q4.如果发现组合逻辑Comb_D太大超出预期,请列出可能的原因?(+4)
组合逻辑路径过长,经过组合逻辑的cell太多 布线太长,线延时大
Q5.如果Comb只是两级buffer组成,Comb_D太大超出预期请列出可能的原因?(+4)
跟cell单元延时有关,cell延时与input transition 和 output load有关,cell延时大,Comb_D大。 布线太长,线延时大
3
某主频为400MHz的CPU执行标准测试程序,程序中指令类型、执行数量和平均时钟周期数如下:
指令类型 指令执行数量 平均时钟周期数
整数 45000 1
数据传送 75000 2
浮点 8000 10
1.求该计算机的有效CPI(Cycle Per Instruction). MIPS(Million Instruction Per Second)和程序执行时间。
CPI = (一条指令所需要的平均时钟周期)
=(45000 + 75000 * 2 + 8000 * 10) / (45000 + 75000 + 8000)= 2.1484375
MIPS = 400*10^6 / 2.1484375 / 10 ^ 6 = 186.18181818
time = (45000 + 75000 * 2 + 8000 * 10) / 400 = 687.5us
2.若将CPU中浮点单元加速10倍,CPU整体性能提升比例是多少?
CPI = (45000 + 75000 * 2 + 8000) / (45000 + 75000 + 8000)= 1.5859375 2.1484375/1.5859375 = 1.3546798倍
4.
为该逻辑表达式作化简:Y=A'BC+AB'C+ABC'+ABC+AB'C+AB'C'('表示取非运算)
Y = BC + AB'
5
池化操作(Pooling)是CNN中非常常见的一种操作,Pooling层是模仿人的视觉系统对数据进行降维,池化操作通常也叫做子采样(Subsampling]或降采样(Downsampling),Maxpooling是最常见的一种池化操作,下文描述了一个典型的poling操作:
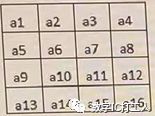
Input data Matrix A
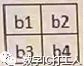
Output data Matrix B
Date flow
b1 b2 b3 b4
Calculation
b1=max(a1,a2,a3,a5,a6,a7,a9,a10,a11)
输入数据Matrix A为8bit无符号数,数据a1-a16按照顺序存放在一块深度16宽度8bit的sram里,经过maxpool模块对数据进行池化操作,输出数据Matrix B按照b1~b4的顺序写到fifo中。按照下面的框图,用verilog HDL编写maxpool模块,具体要求如下:
1.收到trig信号时开始pooling操作,计算完16个输入数据,输出4个输出数据,返回done信号,trig和done都是1T pulse;
2.输入数据来源是标准sram,cs:高有效;wen:低电平写,高电平读:ra:读地址;
3.FIFO是标准接口,wr_rdy为高时可写,wr_en为高时写有效;
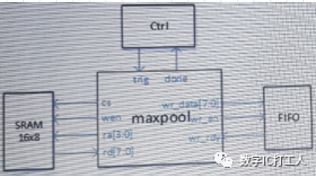
Q1.maxpool理论上最少需要多少cycle完成一次数据处理(从trig到done的cycle数)?给出方案及分析(+4)
采样:第一个周期采样到trig为高,然后拉高cs和wen,ra = 0,第二个周期对读取的数据进行采样,以此类推,到第17个周期将16个数据全部采样到mem里 计算最大值:在第10个周期、第13个周期、第16个周期、第17个周期开始计算最大值 存储到FIFO:在第11个周期、第14个周期、第17个周期、第18个周期存到FIFO中
Q2.用verilog HDL编写maxpooI代码,尽量减少逻辑资源使用;(+20)
上面的思路其实不确定... 希望有懂的指点一下... 所以代码没写
6
现在有两个数组a=[1,1,2,4,5],b=[1,2,3,7],请用python/perl实现,找到这两个数组的交集和并集
#!/usr/bin/python3 a = [1,1,2,4,5] b = [1,2,3,7] res_and = [] for item_a in a: for item_b in b: if (item_a == item_b): res_and.append(item_a) res_union = a + b res_union = list(set(res_union)) res_and = list(set(res_and)) print(res_and) print(res_union)
7
某IP有支持3种op操作:WRITE/READ/NOP,其中这个IP 40%是处于读的状态,40%是处于写状态,20%左右是处于NOP状态,请写出constraint(sv代码)
module tb;
typedef enum {WRITE, READ, NOP} op_state;
class state;
rand op_state op;
constraint c {
op dist { WRITE:= 40, READ := 40, NOP := 20};
}
endclass
endmodule