(Unsupervised Anomaly Detection)无监督异常检测领域最新研究进展 - Part 0 异常检测简述 【持续更新...】
文章目录
-
- 1. 简介
- 2. 相关数据集与评价指标
- 3. 研究进展
- 参考
1. 简介

异常检测,简单地说就是让学习到的模型能够区分开正常样本和异常样本。比如在医学领域,根据CT影像学习的癌症检测模型也可以说是异常检测,正常样本就是正常人地CT影像,异常样本就是癌症患者的CT影像。再比如在智能监控领域,要求模型能够检测高速公路上出现的影响通行的阻挡物,那么这也是异常检测。总之,异常检测就是根据任务的需求定义好正常样本(比如正常人的CT影响,干净的路面),并在测试阶段能够检测出异常样本(可疑的癌症患者,公路上的阻碍物)。
很容易觉得这不就是“图像分类”或者“目标检测”嘛,只是类别只有正常/异常两个类而已!
其实不然,相比于一般的分类、检测、分割,在异常检测任务中对于异常类别的定义通常是难以定义的。此外,通常异常样本也难以获取并且数据量有限。比如在癌症检测的例子中,医院可能有海量的正常样本(正常人CT影像),但癌症患者的影像可能非常少,如果直接简单地进行二分类任务,存在极端的样本不均衡问题,并且模型会严重过拟合(因为癌症影像可能千奇百怪,所获取的样本并不能代表全部的分布)。
所举的CT检测的例子缺乏专业知识,请体谅
由于异常类别定义困难并且异常样本难以收集,这就导致了异常检测任务的特殊性。因此很多工作也将异常检测任务视为"semi-supervised"或"unsupervised"设置,而本系列文章也主要是介绍无监督图像异常检测领域的最新研究。
如果在某个任务中,能够很清晰地定义好异常情况并收集较多的异常样本,那么异常检测就可以视为一般的分类、检测任务。
2. 相关数据集与评价指标
无监督异常检测领域的数据集类型目前可以大致分为两类:① 语义级的异常检测 和 ② 区域级的缺陷检测。
语义级的异常检测,简单点地理解就是:需要模型区分语义级别的异常样本。比如一个任务中设定猫是正常样本,那么异常样本就是所有的非猫样本,不管你是加菲猫还是田园猫,都是正常样本,但如果是狗、人就是异常样本。这类任务主要采用的数据集为:CIFAR-10,CIFAR-100或者ImageNet这类数据,将某个类别(或者某几个类别)作为正常样本,测试时其他类别的图像作为异常样本。
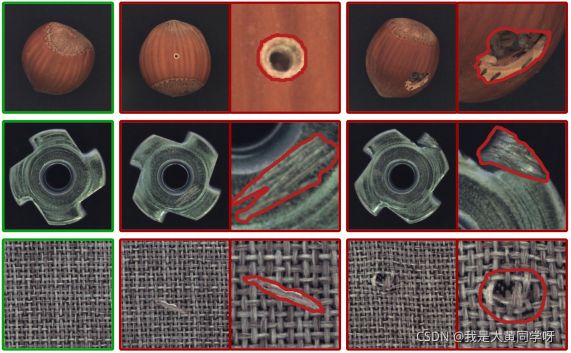
而区域级的缺陷检测,主要应用在工业质检领域,比如工业零部件的异常检测,从整幅图像上来看可能并无较大变动(仍属于同一类),但在某个局部区域存在缺陷,如下图所示。这类任务相比于语义级的异常检测更难,但在现实应用中也具有应用意义,因此近两年也得到了研究者的广泛关注。数据集主要为MVTec AD,一共有15个类别,训练时只能获取正常样本,要求测试时能分辨出缺陷样本。并且数据集也提供了缺陷样本的缺陷区域的像素级标注,因此也引出了一个新的子领域Anomaly Segmentation。关于MVTec这个数据集可以参照我另一篇更详细的介绍文章CVPR2019 无监督异常检测/定位数据集:MVTec AD。
博主目前也主要是研究的这个方向,欢迎私聊探讨
常用的评价指标为AUCROC,这是一个与阈值无关的指标,常用于二分类算法的评估。首先选取不同的阈值绘制ROC曲线(纵轴为TPR真正率,横轴为假正率FPR),然后曲线下的面积就是AUCROC。这方面的资料已经非常多了,不过多赘述,贴上一个知乎的文章供参考ROC曲线和AUC值。
针对缺陷检测中的Anomaly Segmentation任务,常用的指标有Pixel AUCROC,也就是视为像素级二分类任务。但有工作也提到AUCROC对于一些面积较大的缺陷会比较宽容,因此提出了PRO-score,PRO-score同样也是在一系列阈值下构建性能曲线,并以曲线下面积作为综合评估指标。不同的是,PRO-score统计的是不同阈值下的区域重叠率(Per-region-overlap, PRO), 以二值化后连通域和真值图之间的相对重叠率作为每一个阈值下的模型分类性能。也有工作直接使用语义分割的IoU作为异常分割的评价指标,但目前用的最多的还是像素级的AUCROC。
3. 研究进展
无监督异常检测一直都是计算机视觉领域的主流研究方向之一,在深度学习兴起之前,就已经有很多利用传统方法进行异常检测的工作。它们的主要思想都是学习一个能描述正常样本的模型,在测试阶段比较测试样本与模型间的差异来进行异常检测的,比如模板匹配,GMM,OC-SVM以及SVDD等方法。
对传统方法感兴趣的请参考文献[1]
随着深度学习的发展,后来的工作开始引入神经网络进行异常检测。前几年的方法主要针对于CIFAR-10以及MNIST这类语义级异常检测的数据集,指标已经被刷得非常高了,随着MVTec数据集的提出和深度学习技术的发展,最近几年又出现了大量新的方法与思路,给这个领域注入了新的活力(目前也刷得比较高了… …)。
以下几个主要板块,点击跳转到对应链接,持续更新中… …
本系列的文章主要基于博主自己的积累和阅读,对近几年无监督学习的发展进行了一些总结和思考。肯定有不详细和未涉及之处,还请大家多多指点。主要按照各个工作的研究思路,大致分为以下几个方向进行介绍:
- 基于重构的方法 (Reconstruction Based)
主要为基于图像空间重构的方法
- Part 1 基于重构的方法(1)【主要内容:AE/VAE,基于inpainting,基于Memory】
- 基于自监督学习的方法 (Self-Learning Based)
主要为基于代理任务和对比学习的方法
- 基于特征嵌入的方法 (Embedding Based)
主要为进行特征空间学习的方法
- Part 3 基于嵌入的方法(1)【主要内容:SPADE系列,知识蒸馏】
持续更新中… …
上述分类可能存在一定的交叉,因为很多工作同时用到了不同的思想。比如,重构本身也可以说是一种自监督学习方法;自监督学习方法的对比学习也是在学习特征嵌入。所以,上述板块只是按照我的阅读积累和理解来进行分类,如有建议,请评论区告知~
参考
[1] Lv Cheng-Kan, Shen Fei, Zhang Zheng-Tao, Zhang Feng. Review of image anomaly detection. Acta Automatica Sinica, 2021, 47(x): 1−27 doi: 10.16383/j.aas.c200956
温馨提示:码字不易,转载请提前告知(私聊和评论皆可)