LeNet-5网络结构详解和minist手写数字识别项目实践
参考论文:Gradient-Based Learning Applied to Document Recognition
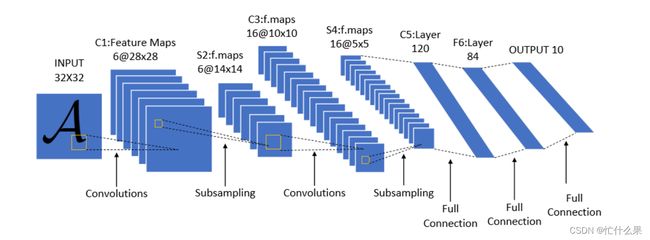
组成
网络虽然很小,但是它包含了深度学习的基本模块:卷积层,池化层,全连接层。
输入层:32×32(输入层不计入网络层数)
卷积层1:6个5×5的卷积核,步长为1——>(6,28,28)
池化层1:MaxPooling,(2,2)——>(6,14,14)
卷积层2:16个5×5的卷积核,步长为1——>(16,10,10)
池化层2:MaxPooling,(2,2)——>(16,5,5)
全连接层1:120,——>16×5×5×120+120
全连接层2:84,——>120×84+84
全连接层3:10,——>84*10+10
特点
- 第一次将卷积神经网络应用于实际操作中,是通过梯度下降训练卷积神经网络的鼻祖算法之一;
- 奠定了卷积神经网络的基本结构,即卷积、非线性激活函数、池化、全连接;
- 使用局部感受野,权值共享,池化(下采样)来实现图像的平移,缩放和形变的不变性,其中卷积层用
- 来识别图像里的空间模式,如线条和物体局部特征,最大池化层则用来降低卷积层对位置的敏感性;
lenet5-minist手写数字识别项目实践
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Input, Dense, Activation, Conv2D, MaxPooling2D, Flatten
from tensorflow.keras.datasets import mnist
# 加载mnist数据
(x_train, y_train), (x_test, y_test) = mnist.load_data()
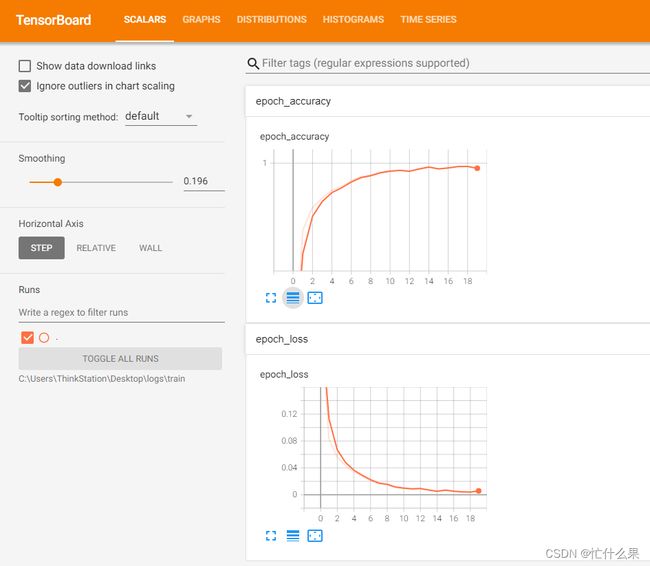
print(type(x_train)) # tensorboard --logdir=C:\Users\ThinkStation\Desktop\logs\train
模型保存
