Vision Transformer | CVPR 2022 - Vision Transformer with Deformable Attention
CVPR 2022 - Vision Transformer with Deformable Attention

- 论文:https://arxiv.org/abs/2201.00520
- 代码:https://github.com/LeapLabTHU/DAT
- 核心内容:使用流场偏移的策略对key和value更加聚焦于相关区域,从而获得更具针对性的上下文信息。

- 首先对形状为H×W×3的输入图像进行4×4不重叠的卷积嵌入,然后进行归一化层,得到H4×W4×C 的patch嵌入。
- 为了构建一个层次特征金字塔,Backbone包括4个阶段,stride逐渐增加。
- 在2个连续的阶段之间,有一个不重叠的2×2卷积与stride=2来向下采样特征图,使空间尺寸减半,并使特征尺寸翻倍。
- 前两个阶段主要是学习局部特征,并且其中的key和value尺寸较大。全局计算的Deformable Attention操作并不适合。为了实现模型容量和计算负担之间的权衡,这里采用Local Attention+Shift Window Attention的形式,以便在早期阶段有更好的表示。
- 在三四阶段引入了Local Attention+Deformable Attention Block的形式。特征图首先通过基于Window的Local Attention进行处理聚合局部信息,然后通过Deformable Attention Block对局部增强后的token之间的全局关系进行建模。
主要改进


- Deformable Attention被提出来针对Attention操作引入数据依赖的稀疏注意力
- 使用q生成一组offsets。按照这些offsets对q进行基于双线性插值的偏移后获得k和v对应的x,之后与q构建MHSA。这里为了稳定训练过程,对偏移值使用一个预定义的因子s来对其进行放缩,从而阻止太大的偏移。 即 Δ p ← s tanh ( Δ p ) \Delta p ← s \tanh (\Delta p) Δp←stanh(Δp).
- 这一过程中,同样基于生成的offsets来获得对应的相对位置偏置。它会被加到QK/sqrt(d)上。
- 为了实现多样的偏移效果,这里同样将特征通道划分为G组,每组使用共享的偏移量。实际中,注意力模块的头数M被设置为偏移组G的倍数。
- 实际计算中可以通过对输入特征图下采样 r r r被来通过offset进行下采样。文中的模型配置里 r r r都设为1。
Attention计算:

![]()
核心代码
class DAttentionBaseline(nn.Module):
def __init__(
self,
q_size,
kv_size,
n_heads,
n_head_channels,
n_groups,
attn_drop,
proj_drop,
stride,
offset_range_factor,
use_pe,
dwc_pe,
no_off,
fixed_pe,
):
super().__init__()
self.dwc_pe = dwc_pe
self.n_head_channels = n_head_channels
self.scale = self.n_head_channels**-0.5
self.n_heads = n_heads
self.q_h, self.q_w = q_size
self.kv_h, self.kv_w = kv_size
self.nc = n_head_channels * n_heads
self.n_groups = n_groups
self.n_group_channels = self.nc // self.n_groups
self.n_group_heads = self.n_heads // self.n_groups
self.use_pe = use_pe
self.fixed_pe = fixed_pe
self.no_off = no_off
self.offset_range_factor = offset_range_factor
if self.q_h == 14 or self.q_w == 14 or self.q_h == 24 or self.q_w == 24:
kk = 5
elif self.q_h == 7 or self.q_w == 7 or self.q_h == 12 or self.q_w == 12:
kk = 3
elif self.q_h == 28 or self.q_w == 28 or self.q_h == 48 or self.q_w == 48:
kk = 7
elif self.q_h == 56 or self.q_w == 56 or self.q_h == 96 or self.q_w == 96:
kk = 9
self.conv_offset = nn.Sequential(
nn.Conv2d(self.n_group_channels, self.n_group_channels, kk, stride, kk // 2, groups=self.n_group_channels),
LayerNormProxy(self.n_group_channels),
nn.GELU(),
nn.Conv2d(self.n_group_channels, 2, 1, 1, 0, bias=False),
)
self.proj_q = nn.Conv2d(self.nc, self.nc, kernel_size=1, stride=1, padding=0)
self.proj_k = nn.Conv2d(self.nc, self.nc, kernel_size=1, stride=1, padding=0)
self.proj_v = nn.Conv2d(self.nc, self.nc, kernel_size=1, stride=1, padding=0)
self.proj_out = nn.Conv2d(self.nc, self.nc, kernel_size=1, stride=1, padding=0)
self.proj_drop = nn.Dropout(proj_drop, inplace=True)
self.attn_drop = nn.Dropout(attn_drop, inplace=True)
if self.use_pe:
if self.dwc_pe:
self.rpe_table = nn.Conv2d(self.nc, self.nc, kernel_size=3, stride=1, padding=1, groups=self.nc)
elif self.fixed_pe:
self.rpe_table = nn.Parameter(torch.zeros(self.n_heads, self.q_h * self.q_w, self.kv_h * self.kv_w))
trunc_normal_(self.rpe_table, std=0.01)
else:
self.rpe_table = nn.Parameter(torch.zeros(self.n_heads, self.kv_h * 2 - 1, self.kv_w * 2 - 1))
trunc_normal_(self.rpe_table, std=0.01)
else:
self.rpe_table = None
@torch.no_grad()
def _get_ref_points(self, H_key, W_key, B, dtype, device):
ref_y, ref_x = torch.meshgrid(
torch.linspace(0.5, H_key - 0.5, H_key, dtype=dtype, device=device),
torch.linspace(0.5, W_key - 0.5, W_key, dtype=dtype, device=device),
)
ref = torch.stack((ref_y, ref_x), -1)
ref[..., 1].div_(W_key).mul_(2).sub_(1)
ref[..., 0].div_(H_key).mul_(2).sub_(1)
ref = ref[None, ...].expand(B * self.n_groups, -1, -1, -1) # B * g H W 2
return ref
def forward(self, x):
B, C, H, W = x.size()
dtype, device = x.dtype, x.device
q = self.proj_q(x)
q_off = einops.rearrange(q, "b (g c) h w -> (b g) c h w", g=self.n_groups, c=self.n_group_channels)
offset = self.conv_offset(q_off) # B * g 2 Hg Wg
Hk, Wk = offset.size(2), offset.size(3)
n_sample = Hk * Wk
if self.offset_range_factor > 0:
offset_range = torch.tensor([1.0 / Hk, 1.0 / Wk], device=device).reshape(1, 2, 1, 1)
offset = offset.tanh().mul(offset_range).mul(self.offset_range_factor)
offset = einops.rearrange(offset, "b p h w -> b h w p")
reference = self._get_ref_points(Hk, Wk, B, dtype, device)
if self.no_off:
offset = offset.fill(0.0)
if self.offset_range_factor >= 0:
pos = offset + reference
else:
pos = (offset + reference).tanh()
x_sampled = F.grid_sample(
input=x.reshape(B * self.n_groups, self.n_group_channels, H, W),
grid=pos[..., (1, 0)], # y, x -> x, y
mode="bilinear",
align_corners=True,
) # B * g, Cg, Hg, Wg
x_sampled = x_sampled.reshape(B, C, 1, n_sample)
q = q.reshape(B * self.n_heads, self.n_head_channels, H * W)
k = self.proj_k(x_sampled).reshape(B * self.n_heads, self.n_head_channels, n_sample)
v = self.proj_v(x_sampled).reshape(B * self.n_heads, self.n_head_channels, n_sample)
attn = torch.einsum("b c m, b c n -> b m n", q, k) # B * h, HW, Ns
attn = attn.mul(self.scale)
if self.use_pe:
if self.dwc_pe:
residual_lepe = self.rpe_table(q.reshape(B, C, H, W)).reshape(
B * self.n_heads, self.n_head_channels, H * W
)
elif self.fixed_pe:
rpe_table = self.rpe_table
attn_bias = rpe_table[None, ...].expand(B, -1, -1, -1)
attn = attn + attn_bias.reshape(B * self.n_heads, H * W, self.n_sample)
else:
rpe_table = self.rpe_table
rpe_bias = rpe_table[None, ...].expand(B, -1, -1, -1)
q_grid = self._get_ref_points(H, W, B, dtype, device)
displacement = (
q_grid.reshape(B * self.n_groups, H * W, 2).unsqueeze(2)
- pos.reshape(B * self.n_groups, n_sample, 2).unsqueeze(1)
).mul(0.5)
attn_bias = F.grid_sample(
input=rpe_bias.reshape(B * self.n_groups, self.n_group_heads, 2 * H - 1, 2 * W - 1),
grid=displacement[..., (1, 0)],
mode="bilinear",
align_corners=True,
) # B * g, h_g, HW, Ns
attn_bias = attn_bias.reshape(B * self.n_heads, H * W, n_sample)
attn = attn + attn_bias
attn = F.softmax(attn, dim=2)
attn = self.attn_drop(attn)
out = torch.einsum("b m n, b c n -> b c m", attn, v)
if self.use_pe and self.dwc_pe:
out = out + residual_lepe
out = out.reshape(B, C, H, W)
y = self.proj_drop(self.proj_out(out))
return y, pos.reshape(B, self.n_groups, Hk, Wk, 2), reference.reshape(B, self.n_groups, Hk, Wk, 2)
实验结果

消融实验
| 利用空间信息的形式的对比以及位置信息的引入方式 | Deformable Attention 的使用位置 | Deformable Attention offset的范围因子(代码中可见) |
|---|---|---|
 |
 |
 |
对比实验
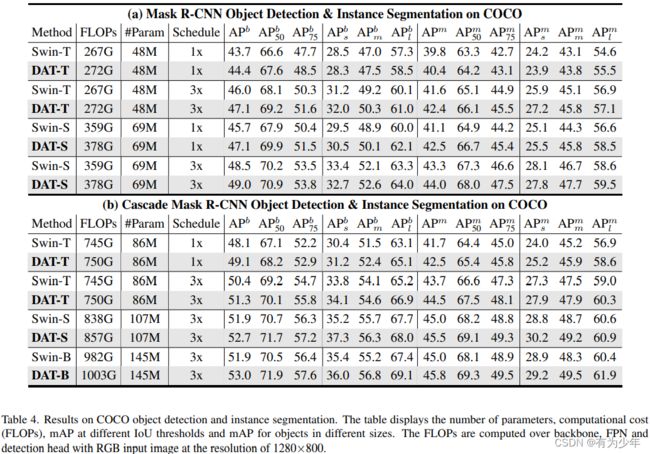
| 分类 | 目标检测 | 分割 |
|---|---|---|
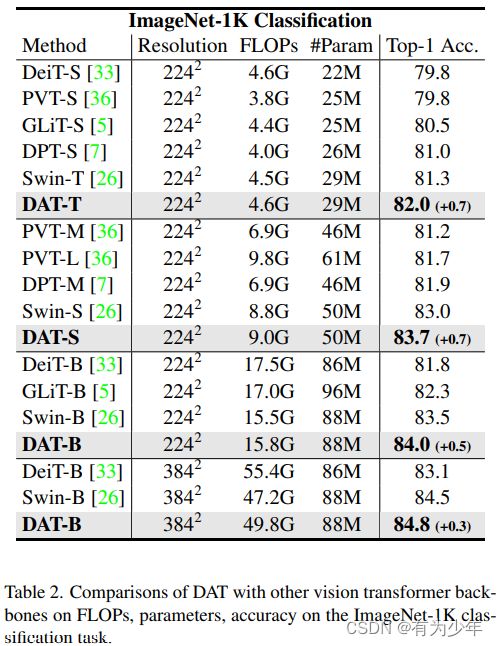 |
 |
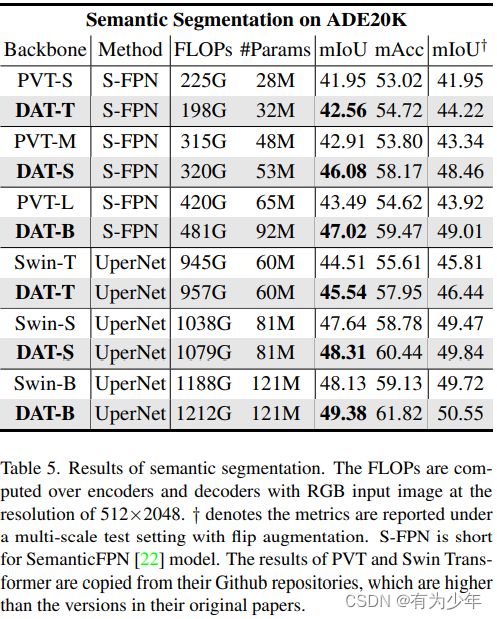 |